The Binary Log
The binary log in MySQL has two main declared purpose, replication and PTR (point in time recovery), as declared in the MySQL manual. In the MySQL binary log are stored all that statements that cause a change in the database. In short statements like DDL such as ALTER, CREATE, and so on, and DML like INSERT, UPDATE and DELETE.
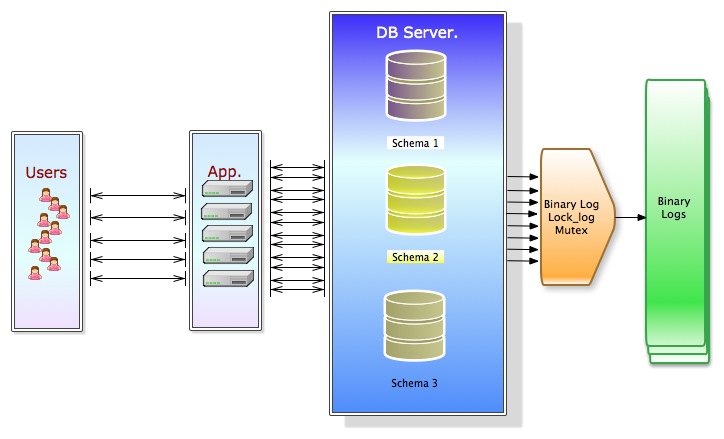
As said binary log transform multi thread concurrent data/structure modification in to a serialize steps of activity. To handle this, a lock for the binary log—the LOCK_log mutex—is acquired just before the event is written to the binary log and released just after the event has been written. Because all session threads for the server log statements to the binary log, it is quite common for several session threads to block on this lock.
The other side effect of this is on SLAVE side. There the binary log becomes the relay-log, and will be processed SINGLE threaded.
In the MASTER it looks like:
While on SLAVE:
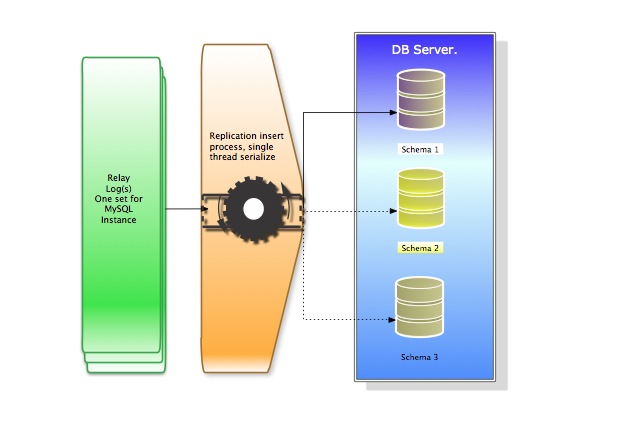
It is quite clear how the SLAVE cannot work efficiently in the case we will have a high level of data modification on the MASTER.
And now the story
The other day I was working on a client site, I was performing some simple benchmarking to identify the correct thresholds for monitoring tools and so on.
While doing that I start to stress a little his server a 24CPU 48GB RAM SAN attached storage running Linux kernel 2.6.
The client had decided, before I or (we) can say anything to use MMM for HA, given that to have an up to date replication is a crucial factor for their HA architecture.
The test I was running execute inserts and selects, of 650 Bytes per insert using scalable number of thread, modifiable complexity in the SELECT, can do single insert or batch inserts and finally can do also BLOB/TEXT inserts (in that case the size per insert will jump up).
I was executing my standard low traffic exercises, when I realized that with only 6 threads doing 318 inserts per second (204Kb/s) the slaves were lagging behind the master for an indecent number of seconds.
I was expecting some lag but not so much. I stop any activity on the Master and wait for slave to recover, it takes 25 minutes to the slaves to recover/apply 20 seconds of inserts on the master.
I was shocked. That was too much considering I normally reach the 36 threads running at the same time on 5.1 and 144 on 5.5 before starting to see scaling issue and performance degradations (not in the scope of this article to publish that results).
Anyhow the issue was on replication not on Master. I was in the need to find a solution for the client or at least try before suggesting an architecture review.
Given re-inventing the wheel it is not my “motto” I started to look around for possible solutions, and parallelization seems the most interesting one.
My first though goes to Tungsten from Continuent, this also thanks to the very nice bogs coming from Giuseppe Maxia :
http://datacharmer.blogspot.com/2011/02/advanced-replication-for-masses-part-i.html
http://datacharmer.blogspot.com/2011/02/advanced-replication-for-masses-part-ii.html
http://datacharmer.blogspot.com/2011/03/advanced-replication-for-masses-part.html
Giuseppe was providing a superb introduction on one of the most interesting (actually the only really usable) solution currently available, the “Tungsten Replicator”.
I was reading the articles and get excited more and more.
That was exactly what I was looking for, until I read “A Shard, in this context, is the criteria used to split the transactions across channels. By default, it happens by database”.
Ooops, it will not work for my customer and me, given that his instance is mainly single schema, or at least the major amount of traffic is directed to only one schema.
I pinged Giuseppe, and we had a very interesting talk, he confirms the approach by object/schema, suggesting alternatives for my issue. Unfortunately given the special case no sharding could be done or table distribution, so for the moment and for the specific case this solution will not fit.
Looking around I had seen that almost all use the same approach, which is parallel replication by OBJECT where object is again and unfortunately, mainly the SCHEMA.
Sharding replication by schema is an approach that could work in some cases but not all.
If you have many schemas, with a limited number of well-distributed Questions per second, I agree this solution is a very good one.
If you have only one schema with very high level of Questions per seconds, this will not work anymore, for sure we can distribute the tables in different schemas, but what about transactions doing inserts/modifications in multiple tables?
We should be sure that each action is running on isolate state, so no relation with others. In short it will not work.
Having the possibility to dream, I would like to have parallel replication by MySQL User/Connections.
I know it could looks as a crazy idea, but trying to replicate the behavior of the MASTER on the SLAVES starts from the user(s) behavior, not from the Object inside the server instance.
Trying to move objects from A to B (see from MASTER to SLAVE) is really complicate because it needs to take in to account how people->application behave on a specific OBJECT or set of them. The status of the OBJECTS is subject to constant changes and most of them at the same time, so concurrency and versioning needs to be preserve.
In short what I was thinking was to realize a conceptual shift from REPLICATION to MIMIC approach.
I started my dream looking on what we already have and how it could be used.
We have a flexible binary log format (version4), we have a known set of SCHEMAS, USERS, and connections going from users to schemas. We have (at least for Innodb) the possibility to have good concurrent and versioning mechanism. The MAX_USER_CONNECTIONS can be used to tune the number of threads the specific user can use, and assign also the permissions.
Setting MAX_USER_CONNECTIONS=30 to USER1@ will help us in correctly dimensioning the effort that replication by user will have to do in checking for consistency.
I am aware of the issue given the interaction and relation between user/transactions, and I see the need of having a coordinator that will eventually manage the correct flush of the transaction by epoch.
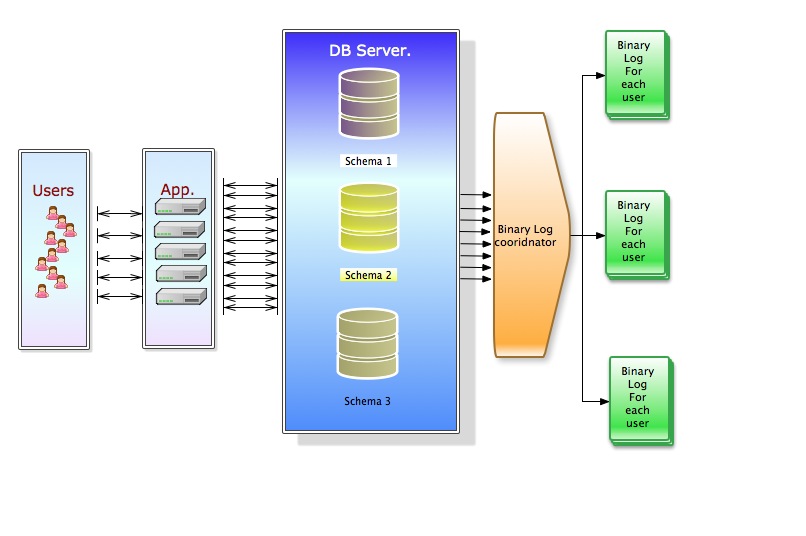
What I was thinking is that the coordinator on the slave could open as much as MAX_USER_CONNECTIONS on the master, and use them as flushing threads.
As said before, I was thinking to trust the internal versioning, so not supporting transaction engines are excluded.
The epoch and/or Transaction ID would then be used to flush them in correct order, where the flush will be done to the pages in memory and then use internal mechanism for flushing to disk(s), talking of InnoDB.
It will not be real parallelization but also not a serialization given we will trust the internal versioning, so we will respect the EPOCH for the launch order not waiting for the completion.
On MASTER the replicator agent will create an X number of Replication channel for each authorized/configured user per SCHEMA, users and permission must be the same also on SLAVE.
The binary log write could looks like:
On the SLAVE, the logs will be copied and then processed opening 1 to MAX_USER_CONNECTIONS Thread(s).
Coordination between insert will be taken by replication MUTEX per User based on the EPOCH.
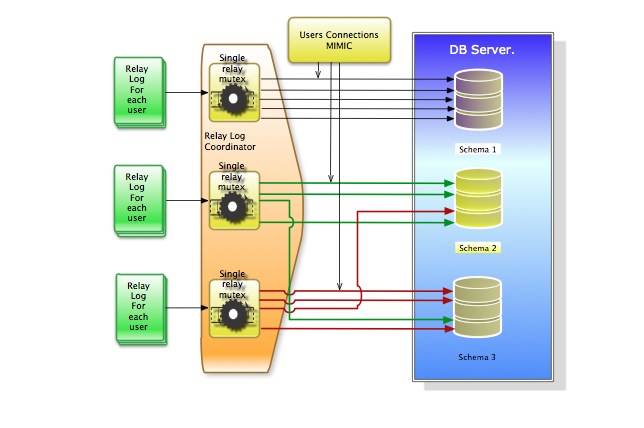
I know quite difficult to realize given the fact that we will have more users writing on different schemas. To have it working correctly, a MUTEX should check the correct process execution at Relay Log Coordinator, ensuring also a correct execution order base on the EPOCH.
Sounds like another serialization, also if we will not wait for the transaction to complete, but only to start.
It seems that a mixed approach will be a better solution, such that replication by SHARD will be used for DB and then per USER inside only by SHARD. This means archiving action per schema and per user transaction. Replicating the work on the SLAVE ensuring to have the same start order of the transaction for the modifications. This is not so crazy as most can think and not so far from sharding by schema, except the multi-threading during the writes.
Main point will be archiving correctly the information in the binary log:
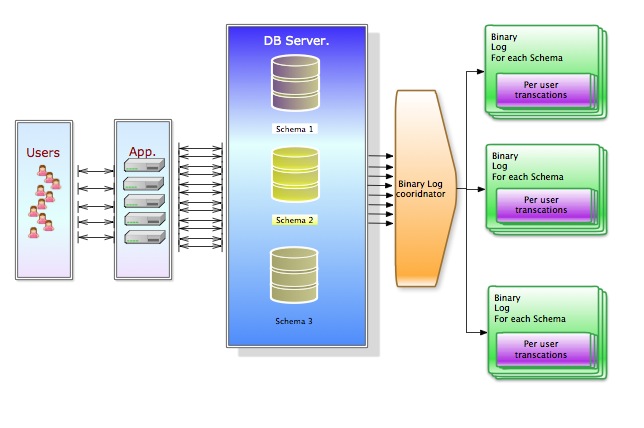
And execute them in the right order as well, keeping also into account the User/Transaction order:
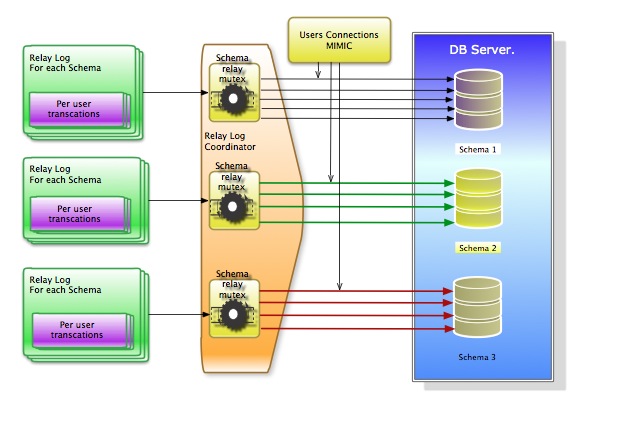
Relay logs will contain information divide by SCHEMA. Processed using multi thread per User/Connection and organize with reference to the epoch of the starting execution order on the MASTER. Different grades of parallel or serialization execution could be set on the how the single Schema relay coordinator will work.
I know it will not be full parallelization but is not serializing as well, given the possible parallel execution of N transaction per user.
I think that there could be some risk here so in the case we should be able to:
- Configure the number of executing threads per user
- Execute only one thread per user
- Choose between EPOCH execution and on Lock relief execution
Fast/short comment on the new binary log.
From binary log V4 we have the possibility to extend what the binary log store in a flexible way.
The extra headers (from byte 19 to X) are there but not used, while that sounds to me the most interesting place where to store additional information regarding what and how happen on the MASTER.
Not only, an HASH value representing the data on the master after the operation, would be of incredible help in checking if the replicated data on the SLAVE is consistent with the MASTER or not, avoiding to do that with silly methods like we are force to do today.
Below the binary log V4 format description:
v4 format description event (size >= 91 bytes; the size is 76 + the number of event types):
+=====================================+
| event | timestamp 0 : 4 |
| header +----------------------------+
| | type_code 4 : 1 | = FORMAT_DESCRIPTION_EVENT = 15
| +----------------------------+
| | server_id 5 : 4 |
| +----------------------------+
| | event_length 9 : 4 | >= 91
| +----------------------------+
| | next_position 13 : 4 |
| +----------------------------+
| | flags 17 : 2 |
+=====================================+
| event | binlog_version 19 : 2 | = 4
| data +----------------------------+
| | server_version 21 : 50 |
| +----------------------------+
| | create_timestamp 71 : 4 |
| +----------------------------+
| | header_length 75 : 1 |
| +----------------------------+
| | post-header 76 : n | = array of n bytes, one byte per event
| | lengths for all | type that the server knows about
| | event types |
+=====================================+
v4 event header:
+============================+
| timestamp 0 : 4 |
+----------------------------+
| type_code 4 : 1 |
+----------------------------+
| server_id 5 : 4 |
+----------------------------+
| event_length 9 : 4 |
+----------------------------+
| next_position 13 : 4 |
+----------------------------+
| flags 17 : 2 |
+----------------------------+
| extra_headers 19 : x-19 |
+============================+
Conclusion
My favorite mottos are:
“only the ones that do nothing do not make mistakes”
and
“don’t shoot on the pianist”.
As I say from the beginning mine is a dream, and I am just proposing an idea, specially because I see that almost all were following the same mind path focused on OBJECTS, probably for a good reason, but never the less I am following my dream.
It could happen that someone would like to see/try to work on that or that will use part of the idea revisiting modifying and making it possible to implement.
For the moment it is too complex and taking too much time, for me to do it alone, but it could be a good idea for a plug-in in my next life.
References:
In addition to Giuseppe blog, which for now it seems to me the only one proposing something that could be implement, I did some research, but at the end the actors are always the same:
Percona
http://www.percona.com/docs/wiki/percona-server:blueprints:parallel-replication
http://www.mysqlperformanceblog.com/2007/01/30/making-mysql-replication-parallel/
MySQL forge
http://forge.mysql.com/worklog/task.php?id=5569
Other
http://feedblog.org/2007/01/30/design-proposal-for-multithreaded-replication-in-mysql/
http://scale-out-blog.blogspot.com/2010/10/parallel-replication-on-mysql-report.html
Note
I already received a comment fromGiuseppe about how to handle the Locks and prevent dead lock... working on that (I have some ideas and details will provide soon).
{joscommentenable}