My take on: Percona Live Europe and ProxySQL Technology Day
This week is almost over, and it pass after two nice event that I had attended.
PerconaLive 2019 in Amsterdam Schiphol and ProxySQL Technology Day in Ghent.
What are my takeaways on both events?
Well, let us start with PerconaLive first.
Venue
The venue was nice, the hotel comfortable and rooms were nice as well, clean and quiet. Allow to have good rest and same time decent space to work if you have to. The conference was just there so I was able to attend, work and rest without any effort, A+.
The hotel was far away from the city and the Amsterdam’s distractions, which it may be a negative thing for many, but honestly IF I spend money, and time of my life to attend a conference, I want to take the most out of it. Have the chance to stay focus on it and to talk with all attendees, customer and experts is a plus. If you want to go around and be a tourist, take a day more after or before the conference and not try to do it while you should work.
Attendees & Speakers
Attendee were curious and investigative, given that I notice most of the speeches were interactive, with people asking questions during the presentations and after. All good, there. A couple of comments I have is more towards some speakers. First, I think some of them should rehears more the speech they present, second please please please STOP reading the slides. You should refer to them, but speak toward the audience not the screen and speak! Give your opinion your thoughts, they can read your bullet points, no need for you to read the text to them.
Outside the rooms we have a good mix of people, talking and interacting. Small groups where reshuffling quite often, which at the end result in better exchanges. Never the less I think we should do better, sometimes we, and I am referring to people like me that are the “old ones” of the MySQL conferences, should help more the customers to connect to each other and with other experts.
Key-notes
I am not going to do a full review of the Key-Note sessions, but one thing come to my mind over and over, and to be honest it makes me feel unhappy and a bit upset.
The discussion we are having over and over about Open Source model and how some big giants (aka Amazon AWS, Google cloud, Microsoft Azure but not only) use the code develop by others, get gazillion and give back crumbs to the community who had develop it, makes me mad.
We had not address it correctly at all, and this because there is a gap not only in the licensing model, but also in the international legislation.
This because open source was not a thing in the past for large business. It is just recently that finally Open Source has been recognized a trustable and effective solution also for large, critical business.
Because that, and the obvious interest of some large group, we lack a legislation that should help or even prevent the abuse that is done by such large companies.
Technical Tracks
Anyhow back to the technical tracks. Given this was a PerconaLive event, we had few different technologies presents. MySQL, Postgress and MongoDB. It comes without saying that MySQL was the predominant and the more interesting tracks were there. This not because I come from MySQL, but because the ecosystem was helping the track to be more interesting.
Postgres was having some interesting talk, but let us say clearly, we had just few from the community.
Mongo was really low in attendee. The number of attendees during the talks and the absence of the MongoDb community was clearly indicating that the event is not in the are of interest of the MongoDB utilizers.
Here I want to give a non sollecitated advice. The fact that Percona supports multiple technologies is a great thing, and Percona do that in the best and more professional way possible.
But this doesn’t mean the company should dissipate its resources and create confusion and misunderstanding when realizing events like the Percona Live.
Do all the announcement and off sessions presentations you want, to explain what the company does (and does them in a great way) to serve the other technologies, but keep the core of the conference for what it should be, a MySQL conference.
Why? It is simple, Percona has being leading in that area after MySQL AB vanished, and the initial years had done a great job.
The community had benefitted a lot form it, and customers understanding and adoption had improved significantly because Percona Live. With this attempt of building up a mix conference, Percona seems have lost the compass during the event. Which is not true!!! But that is what comes out in the community, and more important not sure that is good for customers.
At the same time, the attempt is doom to fail, because both Postgres and Mongo already have strong communities. So instead trying to have the Sun gravitate around the Earth, let us have the Earth to gravitate around the Sun.
My advice is to be more present in the Postgres/MongoDB events, as sponsor, collaborating with the community, with talks and innovation (like Percona packaging for Postgres or MongoDB backup), make the existing conference stronger with the Percona presence.
That will lead more interest towards what Percona is doing than trying to get the Sun out of its orbit.
MySQL
About MySQL, as usual we had a lot of great news and in-depth talks. We can summarize them, indicating how MySQL/Oracle and Percona Software are growing. Becoming more efficient and ready to cover enterprise needs even better than before.
The MySQL 8.0.17 version contains great things, not only the clone plugins. The performance optimization indicated by Dimitri KRAVTCHUK in his presentation, and how they were achieved, is a very important step. Because FINALLY we had broken the barrier and start to touch core blocks that were causing issues from forever.
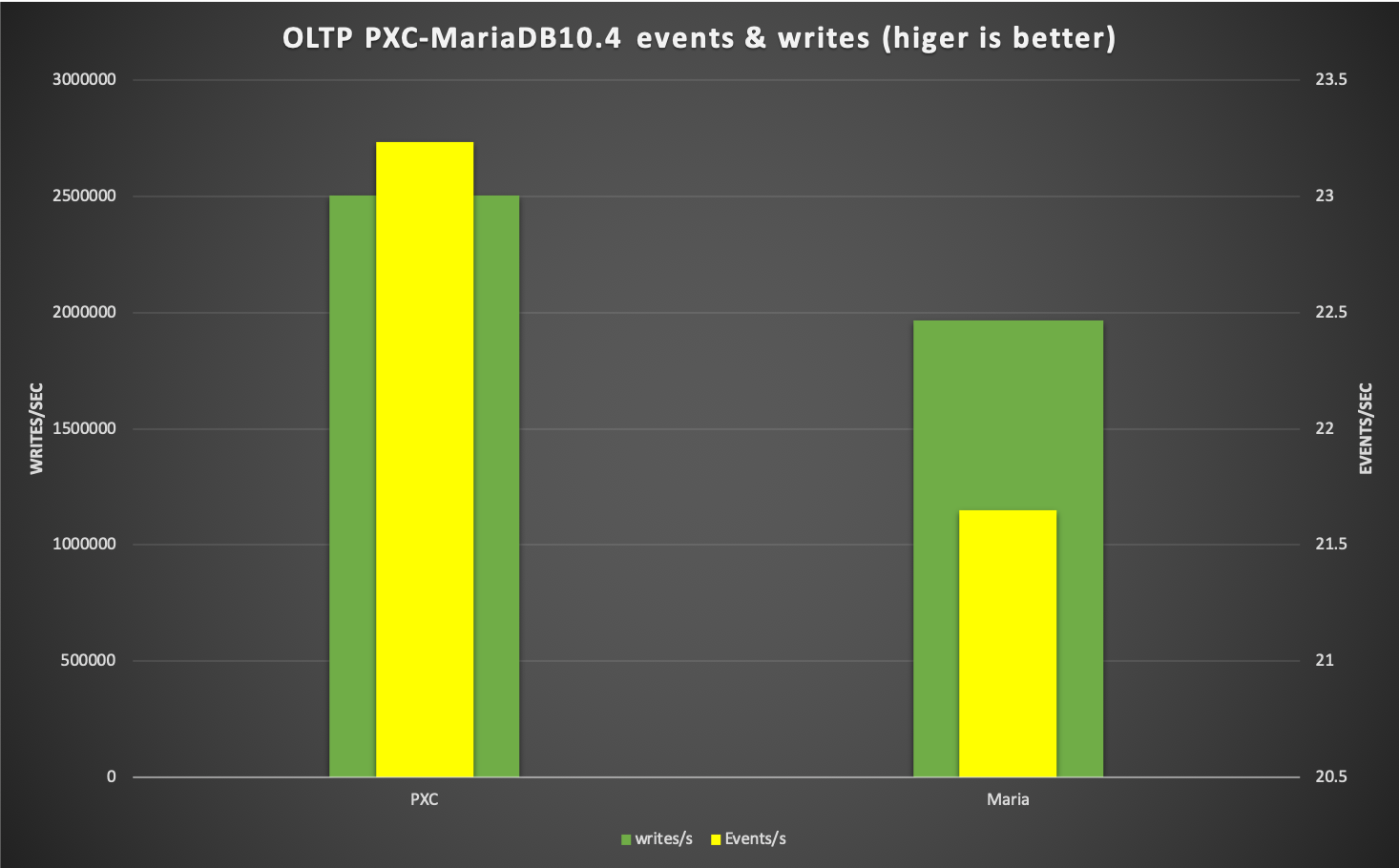
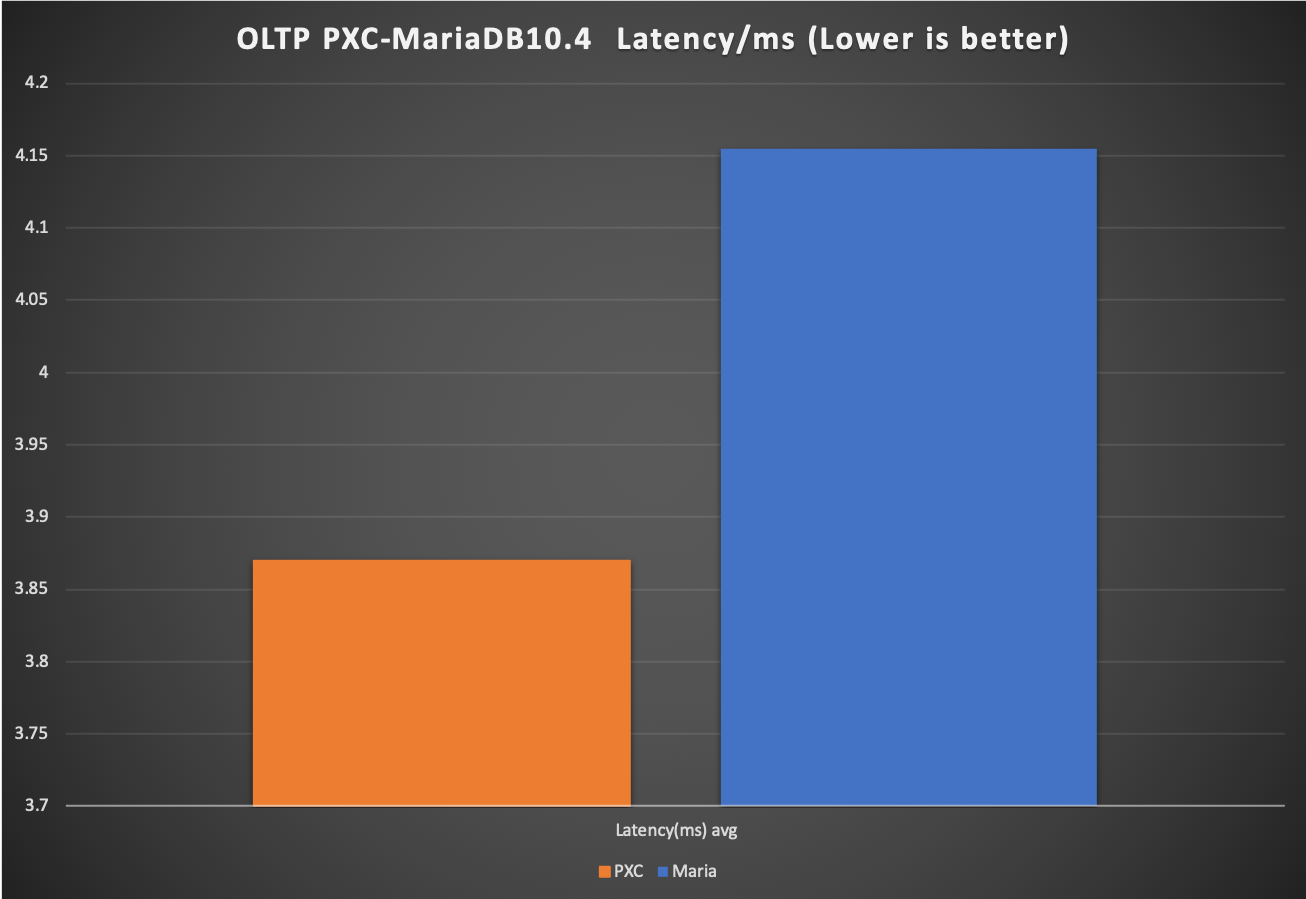
At the same time, it is sad to see how MariaDb is accumulating performance debt respect to the other distributions. Sign that the decision to totally diverge is not paying back, at least in the real world, given for their sales they are better than ever.
As Dimitri said about himself, “I am happy not to use MariaDB” I second that.
InnoDB Cluster
The other interesting topic coming over and over was InnoDB cluster and Group replication. The product is becoming better and better, and yes it still have some issues, but we are far from the initial version on 5.7, lightyear far. Doing some in depth talks about it with the Oracle guys, we can finally say that IF correctly tuned GR is a strong HA solution. At the moment and on the paper stronger than anything based on Galera.
But we still need to see performance wise if the solution keeps the promises when under load, or IF there will be the need to relax the HA constrains, resulting in lowering the HA efficiency. The last operation will result in making GR less HA efficient than Galera, but still a valid alternative.
Galera
About Galera, I have noticed a funny note in the Codership slides at the boot, which says “Galera powers PXC” or something like that.
Well of course guys!!! We all know who is the real code producer of Galera (Codership). Other companies are adopting the core and changing few things around to “customize” the approach.
Packaging that, adding some variants, will never change the value of what you do. Just think about the last PXC announcement who include the: “PXC8 implements Galera 4”.
It seems to me, we have to sit at a table and resolve a bit of identity crisis from both sides.
Vitess also is growing and the interest around it as well, Morgo is doing is best to help the community to understand what it does and how to approach it, well done!
Proxysql taks
A lot of talks about ProxySQL as well, I did one but there where many. ProxySQL is confirming its role as THE solution when you need to add a “proxy/router/firewall/ha/performance improvement”. I am still wondering what Oracle is waiting for to replace router and start to use a more performing and flexible product like ProxySQL.
ProxySQL Technology Day
Finally let us talk about ProxySQL Technology day.
The event was organized in Ghent (a shame it was not on the same venue as PLEU) for the 3td of October after the close of PLEU 2019.
I spoke with many PLEU attendee and a lot of them were saying something like this: “I would LOVE to attend the event, if in Amsterdam, but cannot do at the last minute in Ghent”. Well that is a bit a shame because event was promoted and announced in time, but I have to say I understand not all the people are willing to move away from Amsterdam, take the train and move to the historical Ghent.
Anyhow the ProxySQL Technology Day was actually very well attended. Not only in number of people there, but also company participating. We had, Oracle, Virtual Health, Percona, Pythian and obviously the ProxySQL guys.
It was also interesting to see the different level of attendees, from senior dba or technical managers to students.
The event was happening in the late afternoon starting at 5PM, but I think that ProxySQL should plan the next one as a full day event. Probably a bit more structured in the line to follow for the talks, but I really see it as a full day event, with also real cases presented eventually by customers. This because real life always wins on any other kind of talk, and because a lot of attendee where looking to have the chance to share real cases.
The other great thing that I saw happening there, was during the Pizza Time (thanks Pythian!). The interaction between the people was great, the involvement they had and the interest was definitely worth the trip. I had answered more technical questions during the pizza there than the 2 days PLEU. No barriers no limit, I love that.
Given all the above, well folks in Amsterdam, great to see your pictures in FB or whatever social platform, but trust me you had miss something!
Conclusion
PLEU 2019 in Amsterdam was a nice conference, it totally shows we need to keep focus on MySQL and diversify the efforts for the other technology. It also shows collaboration pay and fights doesn’t.
Some of the thing could have be done better, especially in the session scheduling and in following the Community indications, but those are workable bumps on the road that should be addressed and clarified.
ProxySQL is doing great and is doing better with the time, just this week the ProxySQL 2.0.7 was announced, and include full native support for AWS Aurora and AUTODISCOVERY.
Wow so excited … must try it NOW!
Good MySQL to all…
 Is “that” time of the year … when autumn is just around the corner and temperature start to drop.
Is “that” time of the year … when autumn is just around the corner and temperature start to drop.