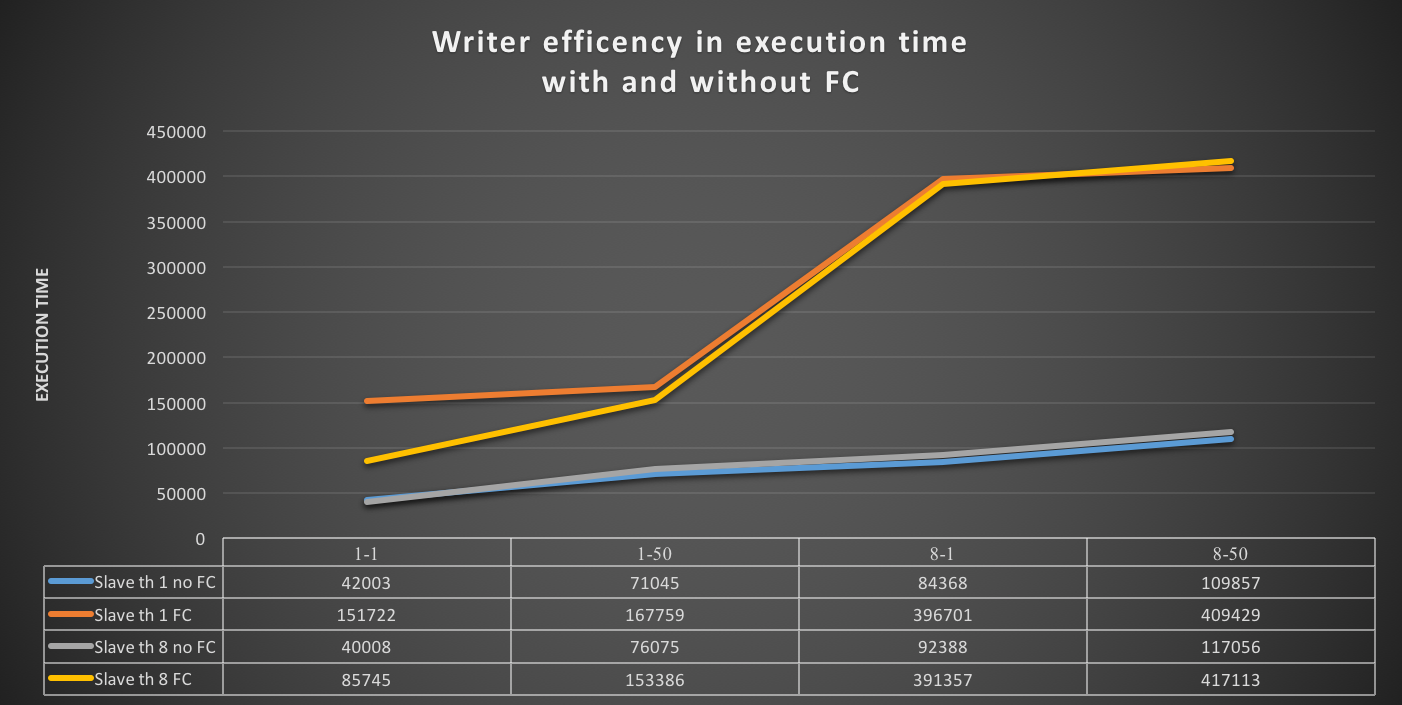
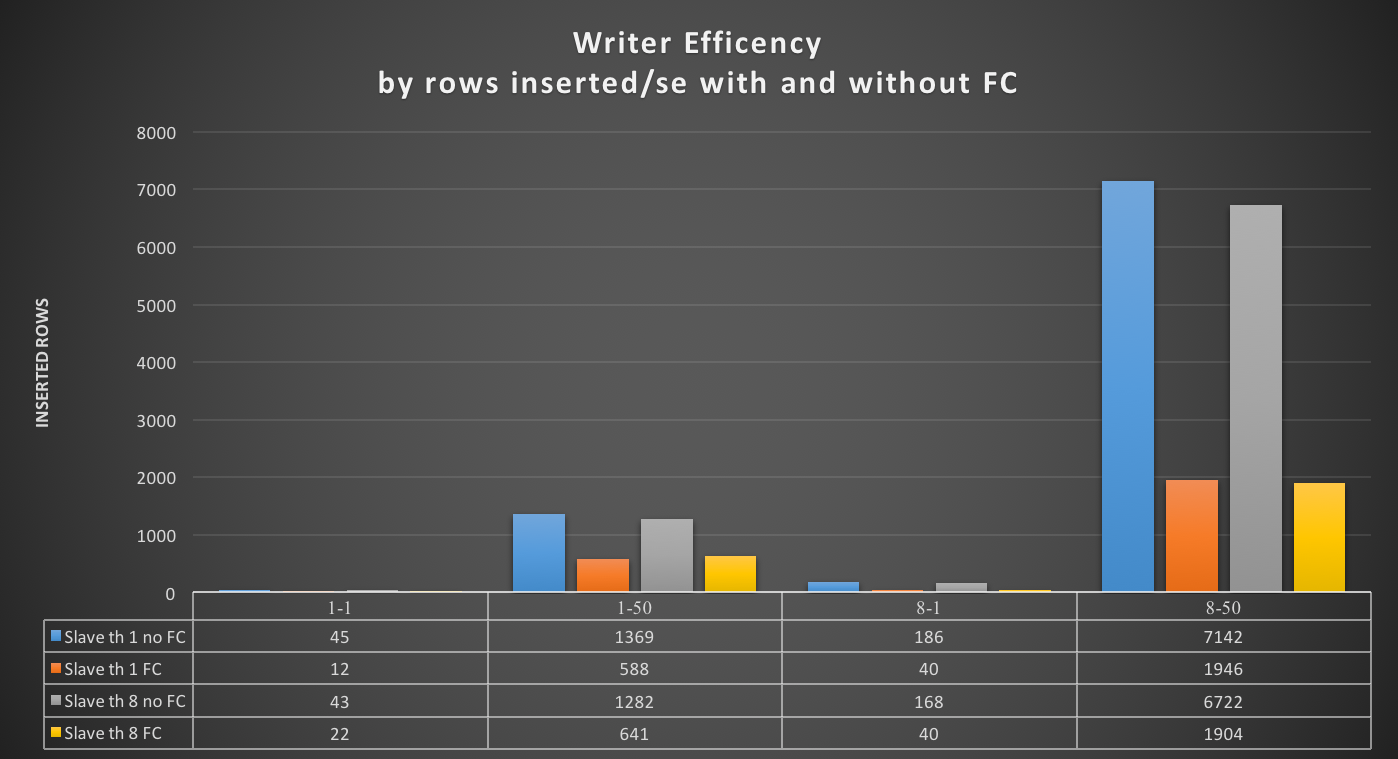
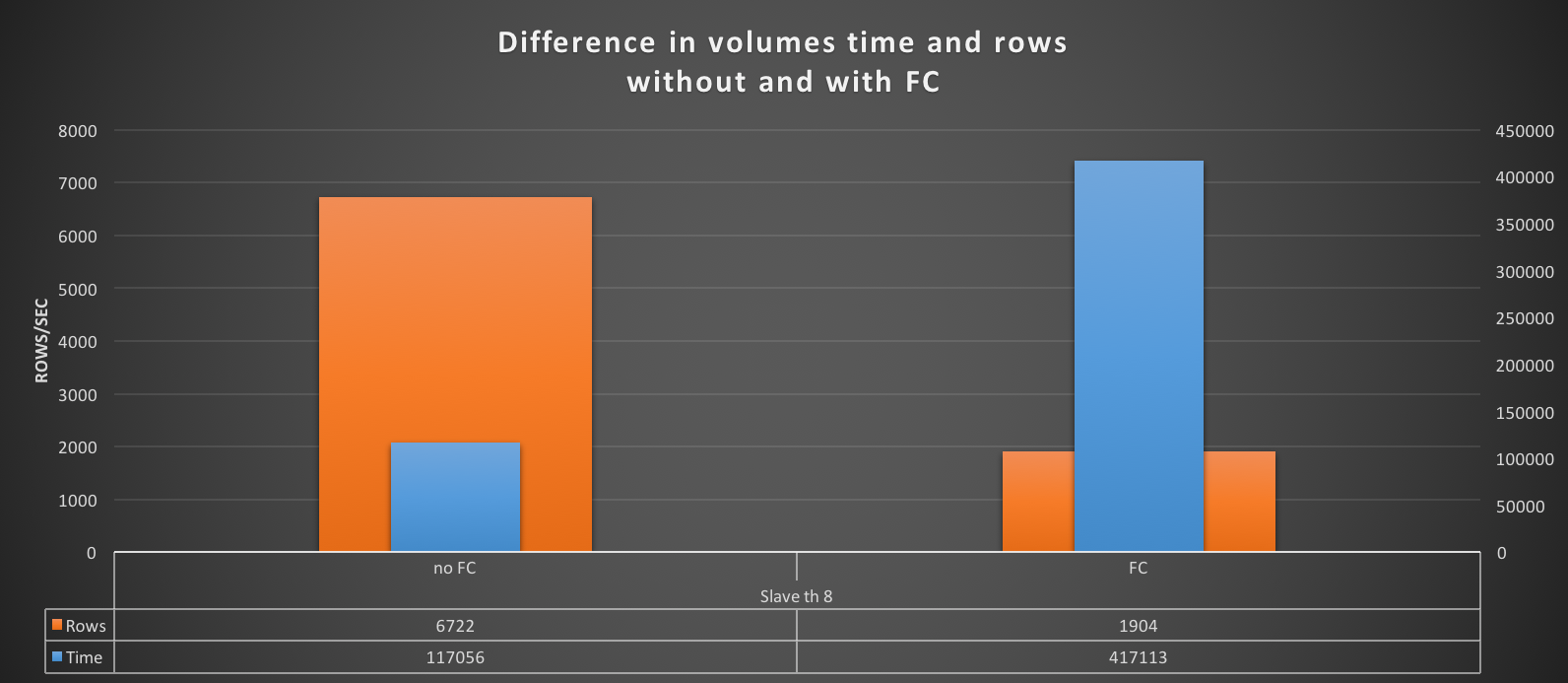
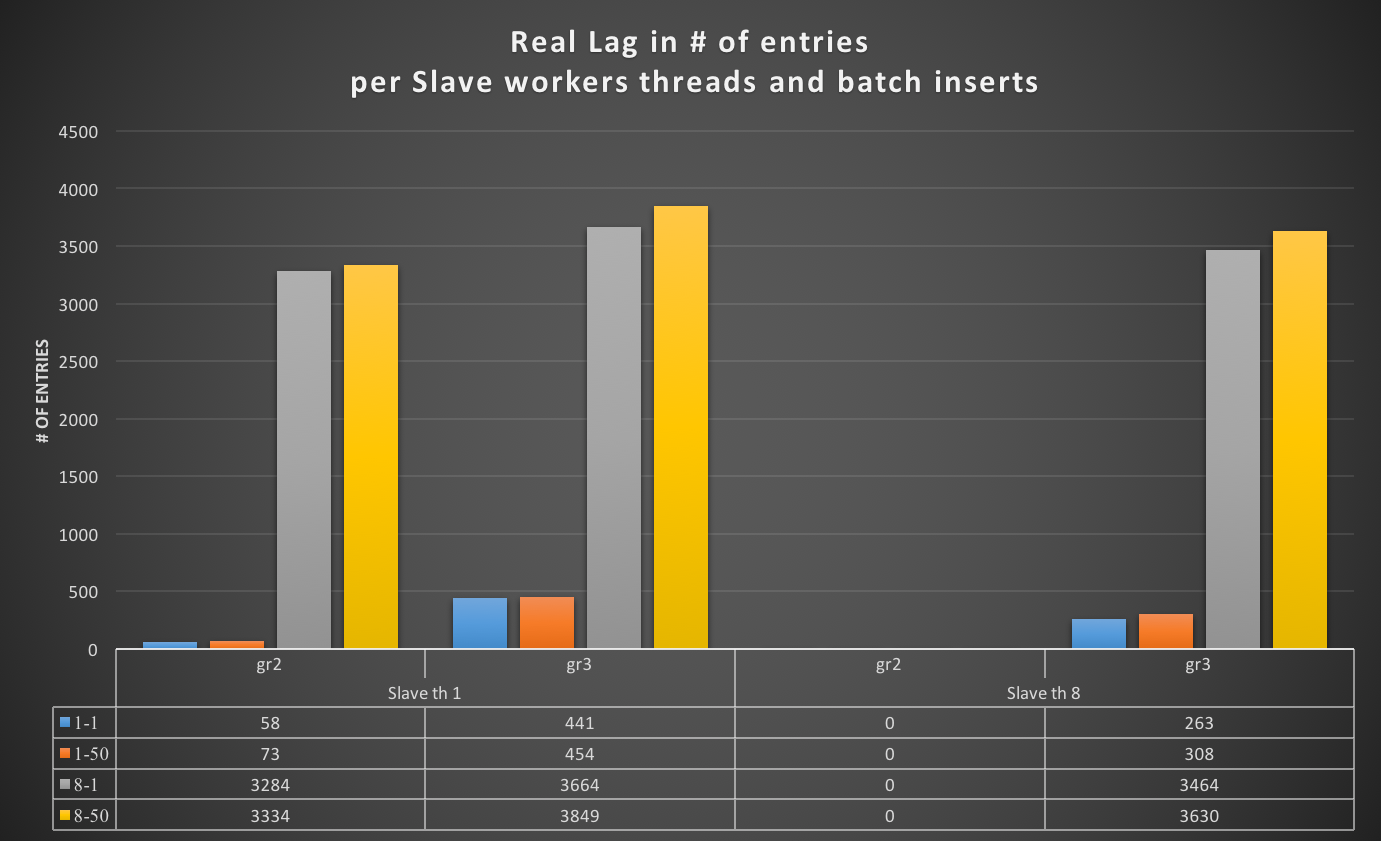
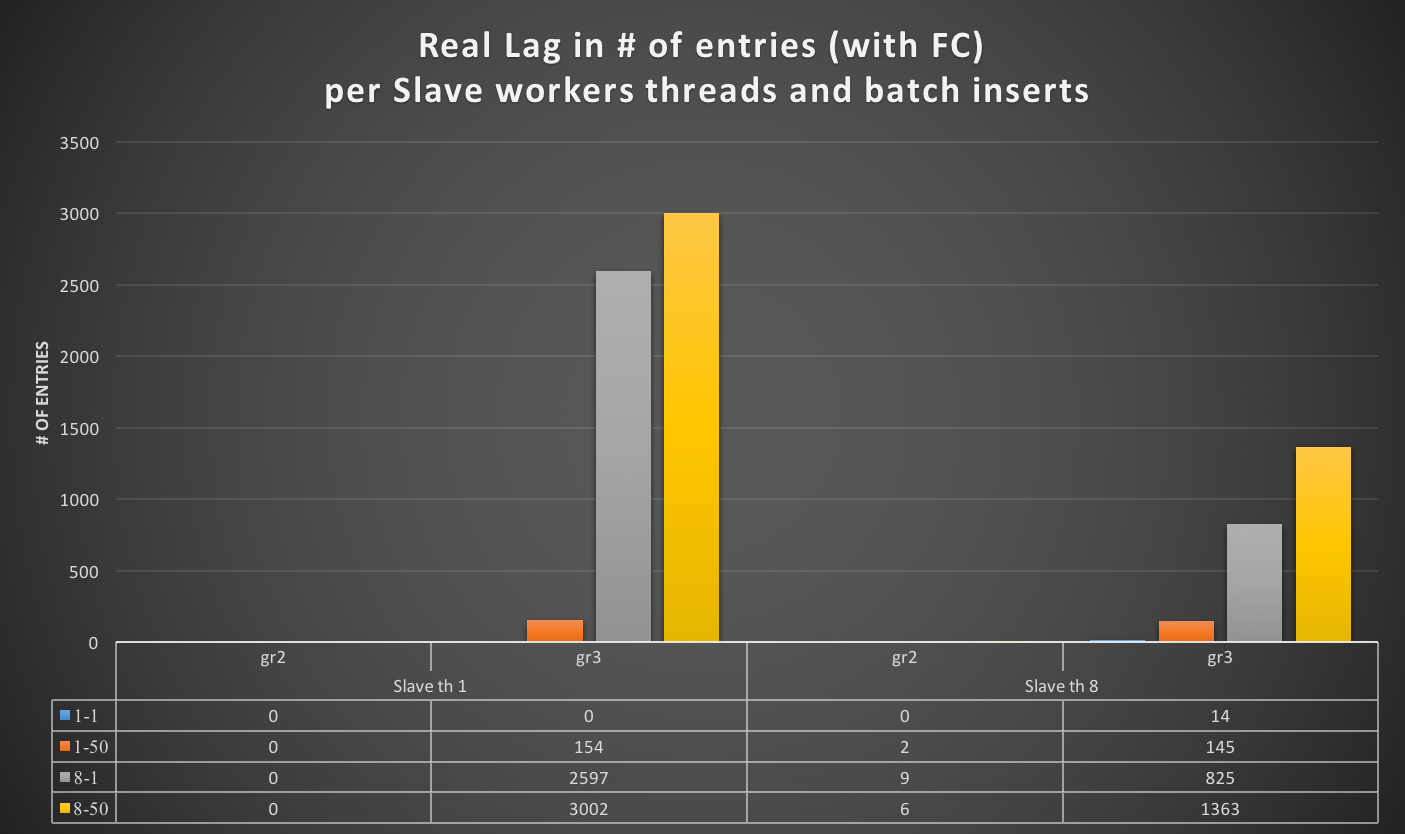
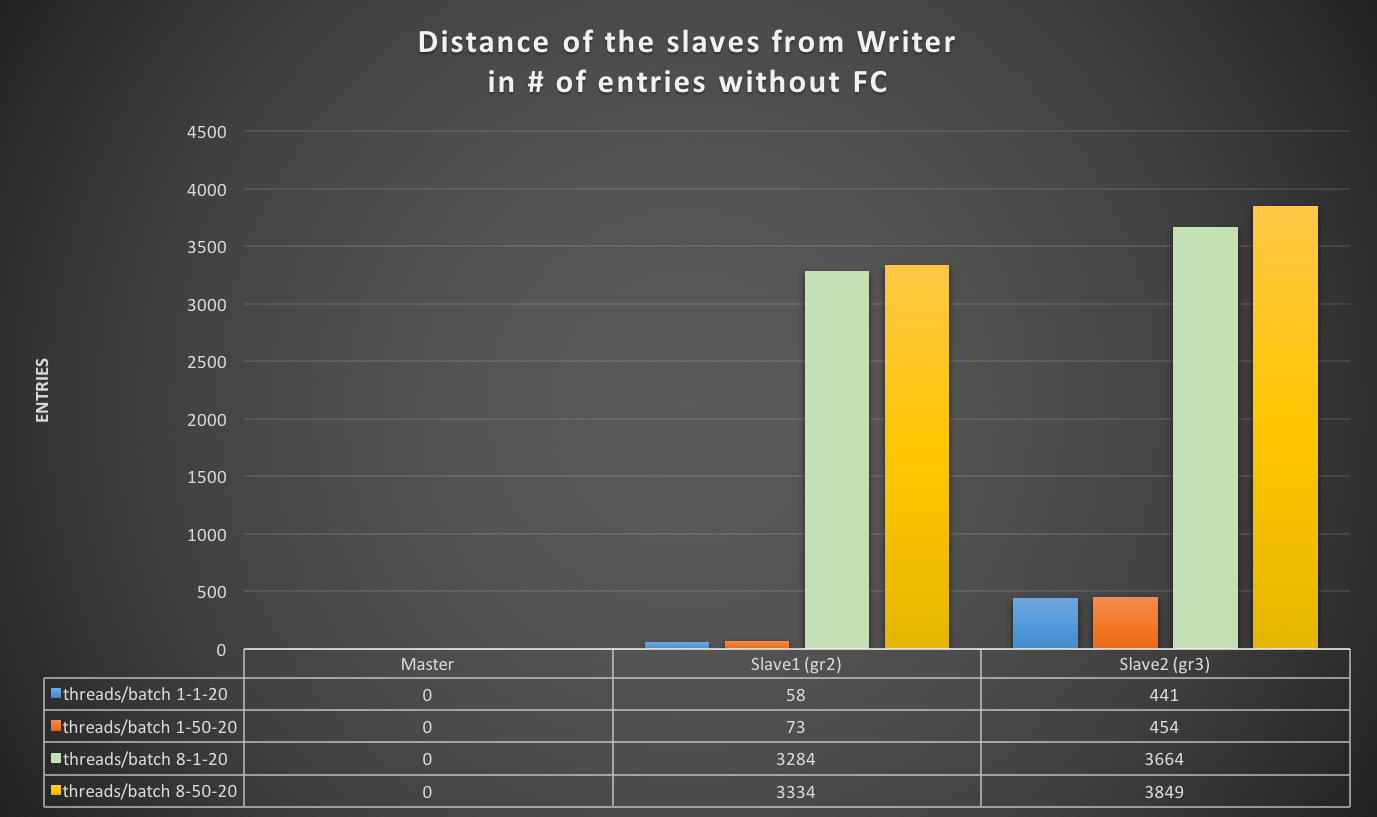
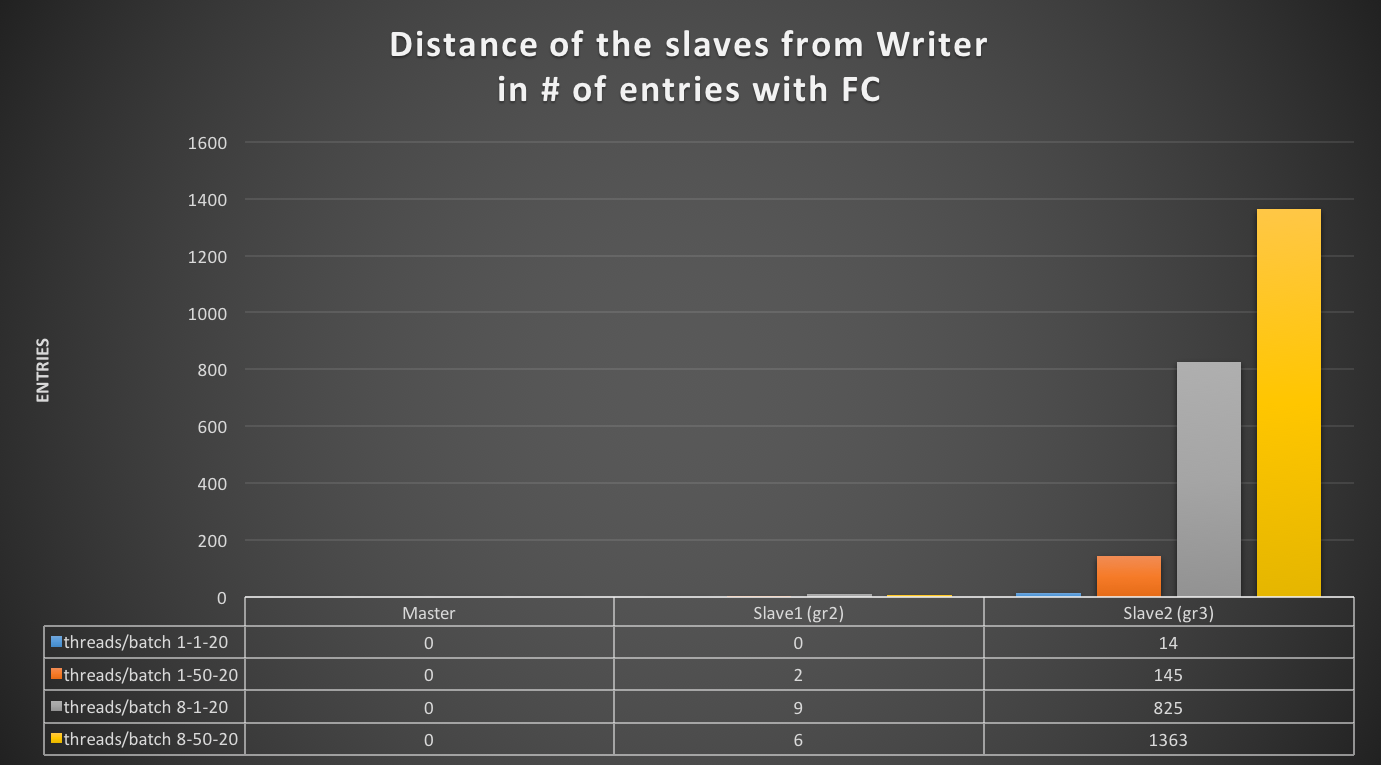
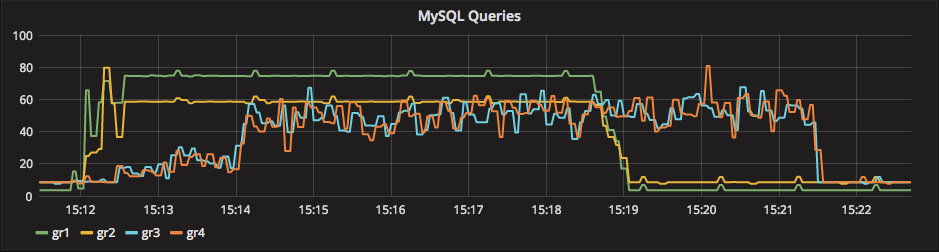
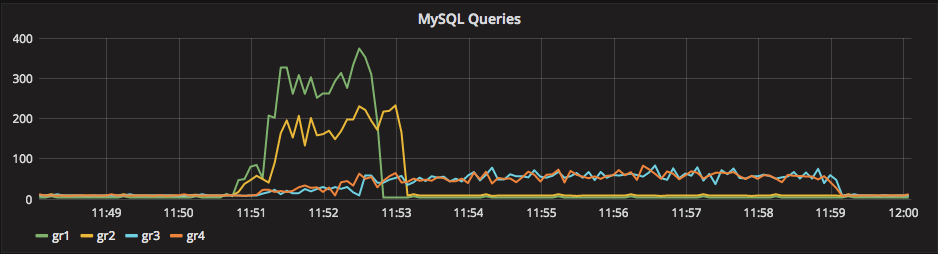
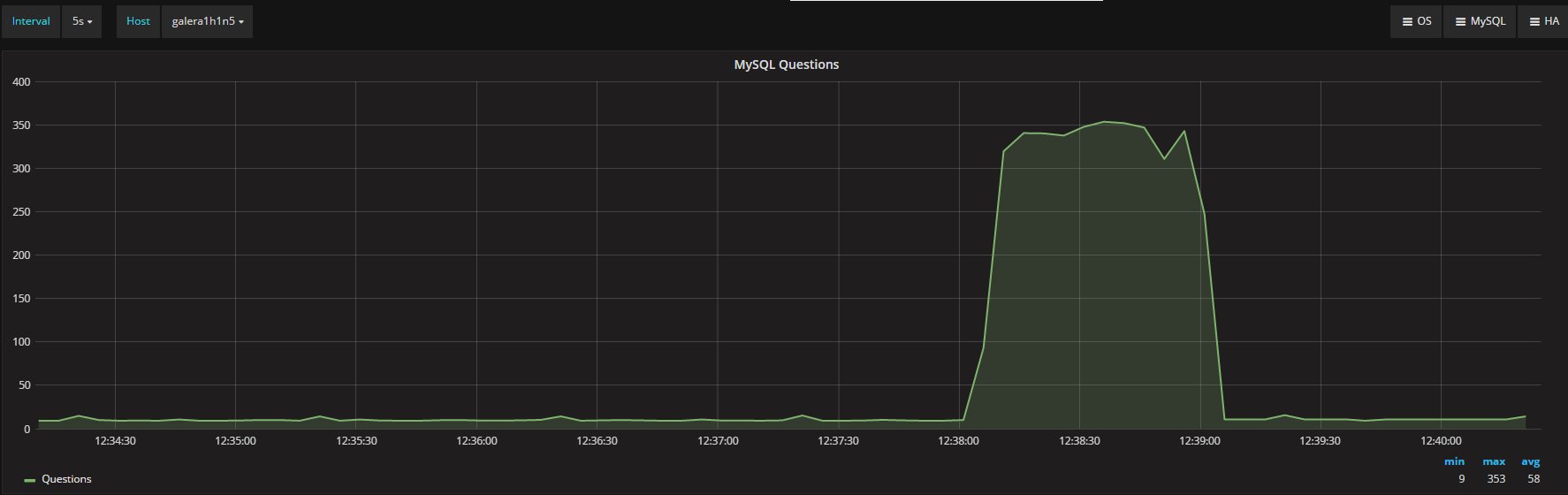
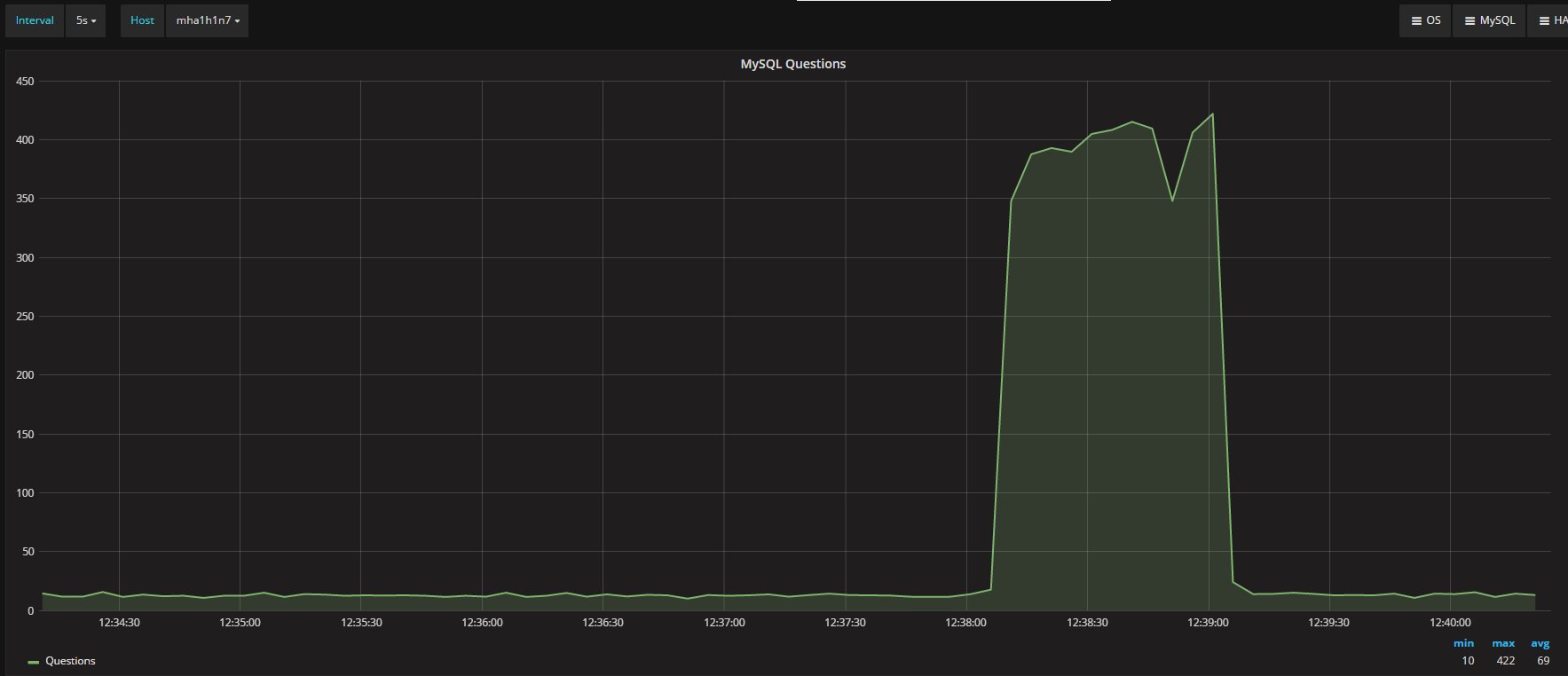
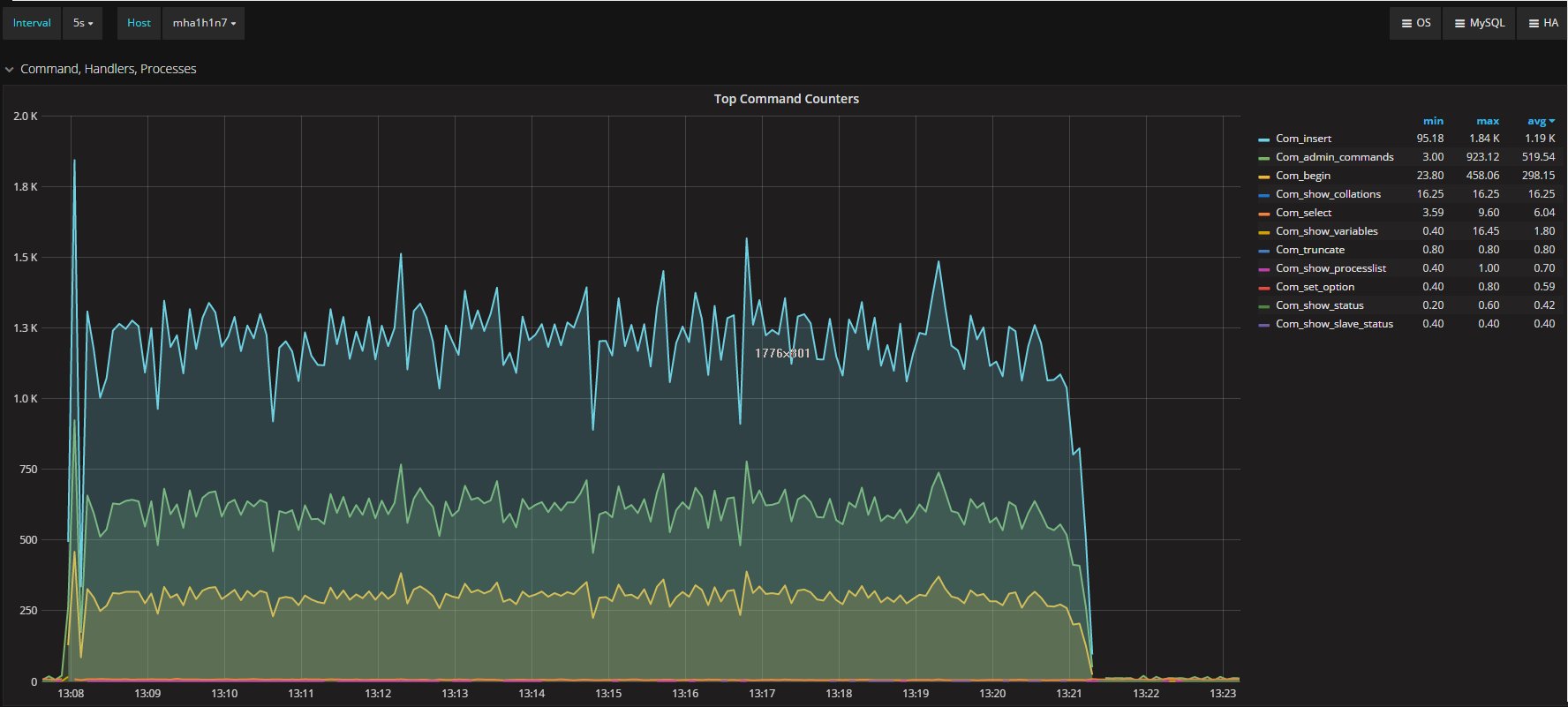
How ProxySQL deal with schema (and schemaname)
I think that very often we are so focus in analyzing internals, or specific behaviours/situations/anomalies that we tend to forget the simple things.
It happened to me that last week a couple of customers raise the same question: "How ProxySQL manage the default schema, or the ones declared inside a FROM/JOIN?"
I was a bit surprise because I was given that for granted, and my first thought was, 'well read the documentation', but then I realize we do not have a clear section in the documentation about this.
Given that and also because I realize I had not done a full and extensive test on how the SCHEMA is actually managed.
I decide to do a simple set of tests and write down few lines.
This blog is to answer that very simple question:"How ProxySQL manage the default schema, or the ones declared inside a FROM/JOIN?"
The blog is split in two parts, part 1 simple declaration and summary of what happen. Part 2 all the details and tests, in case you want to see them.
Schemaname and ProxySQL
In ProxySQL we can specify the schema in two different places and with different scope.
- In the mysql_user table as property of the USER, where it will represent the DEFAULT schema.
- In the mysql_query_rules as filter for which a query can be capture. The filter is valid only for the explicitly set default SCHEMA, (ie with -D mysql command line or USE). ProxySQL will NOT analyze the FROM SQL clausole. Given the limitation in the above point 2, it is not 100% safe to trust the SCHEMANAME as filter unless you are 200% sure the code do not contains commands to change default schema like USE.
On the other hand if I want to filter by a schemaname (in general) it is safer and more flexible to use regular expression and query_rules, as I will show later.
For the scope of this article I want to answer these simple sub-questions:
- How ProxySQL differes from MySQL in managing explicit default schema declaration? does it respect the -D or USE
- How proxy respect/follow security agains schema
- How schemaname filter acts in the query rules?
- How can I transparently redirect using schema name?
To test the above I have created:
two servers:
Master
Slave
two schemas:
world
City
Country
myworld
CityM
CountryM
three users:
uallworld, can access all the schemas (including test)
uworld, can access world in write/read on Master, read on slave. Can access myworld in read on slave.
umyworld, can access myworld in write/read on Master, read on slave. Can access world in read on slave.
Queries used during the tests:
1 2 3 4 5 6 7 8 9 10 11 |
select database(); update world.City set Population=10500000 where ID=1024; update world.Country set LifeExpectancy=62.5 where Code='IND'; update myworld.CityM set Population=10500001 where ID=1024; update myworld.CountryM set LifeExpectancy=0 where Code='IND'; Select * from world.City order by Population DESC limit 5 ; Select * from myworld.CityM order by Population DESC limit 5 ; Select City.*, Country.name, Country.LifeExpectancy from world.City as City join world.Country as Country on City.CountryCode=Country.code order by Population DESC limit 5; Select City.*, Country.name, Country.LifeExpectancy from myworld.CityM as City join myworld.CountryM as Country on City.CountryCode=Country.code order by Population DESC limit 5; Select City.*, Country.name, Country.LifeExpectancy from world.City as City join myworld.CountryM as Country on City.CountryCode=Country.code order by Population DESC limit 5; |
To setup the environment see instructions at Annex 1.
Short story
- How ProxySQL differes from MySQL in managing explicit default schema declaration? Does it respect the -D or USE?
MySQL and ProxySQL will behave the same when passing the default schema, setting it as default.
MySQL
mysql -uuallworld -ptest -h192.168.1.107 -P 3306 -D test
ProxySQL
mysql -uuallworld -ptest -h127.0.0.1 -P 6033 -D test
If a default schema is set in ProxySQL the schema coming from command line or connection (like in java:"connUrl=jdbc:mysql://192.168.1.50:6033/test"), will override the ProxySQL default.
In case a default schema is not pass during the connection MySQL and ProxySQL will differs on how the behave:
MySQL will set the current schema to NULL. It is to be noted that MySQL accept a NULL schema when u connect but then once SET it with USE you cannot set it back to NULL.
ProxySQL will set it as the one declared default in the mysql_user table. If no schema is declared as default, ProxySQL will elect information_schema as the default. In short ProxySQL cannot have a default schema set to NULL.
-
How proxy respect/follow security agains schema
MySQL
mysql -uuworld -ptest -h192.168.1.107 -P 3306 -D test ERROR 1044 (42000):
Access denied for user 'uworld'@'%' to database 'test'
ProxySQL
mysql -uuworld -ptest -h127.0.0.1 -P 6033 -D test
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 483902 Server version: 5.5.30 (ProxySQL)
On connection the behaviour is different between MySQL and ProxySQL.
Why? Because while you directly connect to MySQL, when you connect to ProxySQL you do not actually touch the final server.ProxySQL is NOT a forward proxy, but a reverse proxy, so its scope is act as an intermediary for its associated servers to be contacted by any client. Backend connection that will serve your client is establish at the monent you actually send a query, which will be comunicated to the relevent host group.
As such when you connect, you only open a connection to the ProxySQL. While issue a query will USE a connection to the backend and if the user do not have the right grants an error will be returned.
But ProxySQL will not known until you submit the query and it can decide where this query should go (which HG to point to).
mysql> select database(); ERROR 1044 (42000): Access denied for user 'uworld'@'%' to database 'test'Aside from this all the GRANTS defined in MySQL are transparent and followed by ProxySQL
-
How schemaname filter acts in the query rules?
In MySQL we can easily change the default schema with USE , this action is fully supported by ProxySQL.
But it may have some side effects when using "schemaname" as filter in the query_rules.
If you define a rule that include the default schemaname and the default schema is changed with USE, the rule will not apply, and unpredictable results may happen.
To prevent that ProxySQL has another option in mysql_user "schema_locked" which will prevent the schema to be changed by USE.
This feature is present but not fully implemented, and after a brief conversation with Rene (https://github.com/sysown/proxysql/issues/1133), I hope it will be soon.
Given that, when designing Query rules using the Default schema, you must to take in consideration the possibility to have the application or user changing the default schema and invalidating that rule. -
how can I transparently redirect using schema name?
This is not a Schema feature, more one of the things that in ProxySQL are quite easy to set, while close to be impossible if done in plain MySQL.
When connecting directly with MySQL there is no option for you to "play" with GRANTS and schema such that you will transparently allow a user to do an action on a schema/server pair
and another on a different schema/server pair.
When using ProxySQL to filter by schemaname is quite trivial.
For instance assuming we have 3 users one is admin of the platform which include 2 separate schemas (or more), each user can access one schema for write (but that can be table as well),
and a final slave with reporting information, where all the users that needs to read from other schema except their own can read cross schemas. While all the select not cross schema mus still got to the Master;
This is not so uncommon, actually with few variant is exactly what one of the customer I spoke last week needs to do.
Now in MySQL this is impossible while in ProxySQL is just a matter of 3 rules:
insert into mysql_query_rules (rule_id,username,destination_hostgroup,active,retries,match_digest,apply) values(10,'uworld',10,1,3,'^SELECT.*FOR UPDATE',1);
insert into mysql_query_rules (rule_id,username,destination_hostgroup,active,retries,match_digest,apply,FlagOUT,FlagIN) values(11,'uworld',10,1,3,'^SELECT ',0,50,0);
insert into mysql_query_rules (rule_id,username,destination_hostgroup,active,retries,match_digest,apply,FlagOUT,FlagIN) values(12,'uworld',11,1,3,'\smyworld.',1,50,50);
Simply applying the rules above will allow the application to transparently access the data from different servers without errors,
following the GRANTS given on the MySQL side. This for ONE user (uworld), but it can eventually extended to any, and the rule chain is minimal just 2 rules, so minimal overhead also with high traffic.
Summarizing
ProxySQL is following the MySQL model to access the schema, in most parts. There are a couple of differences though.
ProxySQL will require to set a default schema when connecting, implicitly or explicitly.
ProxySQL will not return an error at connection time, if a user is not authorized to connect to the given schema. Error will raise at the first query, moment when ProxySQL will actually establish the connection.
Finally using ProxySQL, will allow administrator to play with GRANTS and HG/servers to provide transparent access to data in a more granular way, choosing an HG where user may have read (or other specific) access, against one where user is not allow at all .
 Story ... click me
Story ... click me
Annex 1
Create environment for test
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
create schema myworld; create table myworld.CityM like City; create table myworld.CountryM like Country; create table myworld.CountryLanguageM like CountryLanguage; insert into myworld.CityM select * from City; insert into myworld.CountryM select * from Country; insert into myworld.CountryLanguageM select * from CountryLanguage; delete from mysql_users where username like '%world'; insert into mysql_users (username,password,active,default_hostgroup,default_schema,transaction_persistent) values ('uworld','test',1,10,'world',1); insert into mysql_users (username,password,active,default_hostgroup,default_schema,transaction_persistent) values ('umyworld','test',1,10,'myworld',1); insert into mysql_users (username,password,active,default_hostgroup,default_schema,transaction_persistent) values ('uallworld','test',1,10,'test',1); LOAD MYSQL USERS TO RUNTIME;SAVE MYSQL USERS TO DISK; delete from mysql_servers where hostgroup_id in (10,11,20,21); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,comment) VALUES ('192.168.1.107',10,3306,100,'master'); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,comment) VALUES ('192.168.1.109',11,3307,100,'slave'); LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK; delete from mysql_replication_hostgroups; INSERT INTO mysql_replication_hostgroups VALUES (10,11,'world-myworld replication hgroup'); LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK; DO NOT RUN AT THE beginning this is for test 3 !! delete from mysql_query_rules where rule_id in (10,11,12,13,14,15); insert into mysql_query_rules (rule_id,username,schemaname,destination_hostgroup,active,retries,match_digest,apply) values(10,'uworld','world',10,1,3,'^SELECT.*FOR UPDATE',1); insert into mysql_query_rules (rule_id,username,schemaname,destination_hostgroup,active,retries,match_digest,apply) values(11,'uworld','world',11,1,3,'^SELECT ',1); LOAD MYSQL QUERY RULES TO RUNTIME;SAVE MYSQL QUERY RULES TO DISK; DO NOT RUN AT THE beginning this is for test 4 !! delete from mysql_query_rules where rule_id in (10,11,12,13,14,15); Let see what we need and how to do it: 1) user(s) uworld & umyworld need to go to their default schema on Master for Writes. 2) user(s) uworld & umyworld should go to their default schema on master for direct reads 3) user(s) uworld & umyworld should go to the slave for reads when the other schema is used To do this we will need the following rules: insert into mysql_query_rules (rule_id,username,destination_hostgroup,active,retries,match_digest,apply) values(10,'uworld',10,1,3,'^SELECT.*FOR UPDATE',1); insert into mysql_query_rules (rule_id,username,destination_hostgroup,active,retries,match_digest,apply,FlagOUT,FlagIN) values(11,'uworld',10,1,3,'^SELECT ',0,50,0); insert into mysql_query_rules (rule_id,username,destination_hostgroup,active,retries,match_digest,apply,FlagOUT,FlagIN) values(12,'uworld',11,1,3,'myworld.',1,50,50); insert into mysql_query_rules (rule_id,username,destination_hostgroup,active,retries,match_digest,apply) values(13,'umyworld',10,1,3,'^SELECT.*FOR UPDATE',1); insert into mysql_query_rules (rule_id,username,destination_hostgroup,active,retries,match_digest,apply,FlagOUT,FlagIN) values(14,'umyworld',10,1,3,'^SELECT ',0,50,0); insert into mysql_query_rules (rule_id,username,destination_hostgroup,active,retries,match_digest,apply,FlagOUT,FlagIN) values(15,'umyworld',11,1,3,'\sworld.',1,50,50); LOAD MYSQL QUERY RULES TO RUNTIME;SAVE MYSQL QUERY RULES TO DISK; GRANTS ------- grant all on *.* to uallworld@'%' identified by 'test'; grant all on world.* to uworld@'%' identified by 'test'; grant all on myworld.* to umyworld@'%' identified by 'test'; on the slave REVOKE ALL ON *.* FROM 'uworld'@'%'; REVOKE ALL ON *.* FROM 'umyworld'@'%'; grant select on myworld.* to uworld@'%' identified by 'test'; grant select on world.* to umyworld@'%' identified by 'test'; To monitor what is happening --------------------------------- watch -n 1 'mysql -h 127.0.0.1 -P 6032 -uadmin -padmin -t -e "select * from stats_mysql_connection_pool where hostgroup < 30 order by hostgroup,srv_host desc;" -e " select srv_host,command,avg(time_ms), count(ThreadID) from
stats_mysql_processlist group by srv_host,command;" -e "select * from stats_mysql_users;";
mysql -h 127.0.0.1 -P 6032 -uadmin -padmin -t -e "select * from stats_mysql_global "|egrep -i "(mirror|memory|stmt)"' select active,hits,destination_hostgroup, mysql_query_rules.rule_id, match_digest, match_pattern, replace_pattern, cache_ttl, apply,flagIn,flagOUT FROM mysql_query_rules
NATURAL JOIN stats.stats_mysql_query_rules where destination_hostgroup < 30 ORDER BY mysql_query_rules.rule_id; select * from stats_mysql_query_digest; select * from stats_mysql_query_digest_reset; |