
The Galera series
Overview and some history
Some years ago (2011), I was presenting in one article what at that time I have call “A dream on MySQL parallel replication” (http://www.tusacentral.net/joomla/index.php/mysql-blogs/96-a-dream-on-mysql-parallel-replication).
At that time I was dreaming about having a replication mechanism working on the commit operations, and was also trying to explain how useless is to have parallel replication by schema. I have to say that I got a lot of feedback about that article, directly and indirectly, most of it telling me that I was crazy and that what I was looking for cannot be done.
The only crazy guy that was following me in my wandering was Herik Ingo, who mentions to me Codership and Galera.
After few months a customer comes to me describing a scenario that in my imagination, would have be perfect for the cloud and an extension of MySQL call Galera.
At that time I was not really aware of all the different aspect of Galera, but I give it a try. On November 2011, I had done the first POC and start to collect valuable information about how to play with Galera.
It was my intention to write an article presenting it, but I was really too busy and the article at the end was unfinished (http://www.tusacentral.net/joomla/index.php/mysql-blogs/119-galera-on-red-hat-is-123-part-1).
Instead I submit to MySQL connect 2012 the first version of a presentation about this POC, POC that was only the first of much longer list (http://www.slideshare.net/marcotusa/scaling-with-sync-replication-2012).
From September 2012 to April 2013, we have seen Galera and the work coming from Codership, becoming more and more known in the community, this also thanks to Percona and people like Jay Jansen, or support coming from FromDual and tools from Several Nines.
In April 2013 in Santa Clara I attend the Jay’s tutorial, also to see how others were dealing with what for me had become in the last 2 years, a must use.
If you have lost it, here the link and please review the material, Jay is a great professional, and his tutorial was awesome (http://www.percona.com/live/mysql-conference-2013/sessions/percona-xtradb-cluster-galera-practice-part-1).
At the same conference I presented the updates of the POC done with some additional numbers, statistics, and different binaries, in fact I moved from MySQL/Oracle InnoDB to XtraDB.
Keeping in mind that we still talk about 5.5 because Galera is still not 5.6 productions ready, the difference was significant. A lot of inconsistent behaviour in thread handling that I had suffers with standard InnoDB, were not present in XtraDB.
As for today after more then two years from that initial article, we have many Galera installations around, some of them used in very critical systems.
This is thanks to the continuous work of the Codership people, and to the others that had believe in them, people like Herik Ingo, Oli Sennauser (FromDual), Johan Anderson (Several Nines), Jay Jansen (Percona) and myself.
Galera is becoming more and more a solid and trustable product, it still has some issue here and there, but the Codership team is quite efficient in fixing them when tracked down.
ANYHOW I have to make a note here, and I am talking to all the company who are taking advantage out of Galera. Please remember that open source doesn’t mean free, people still has to pay bills, and Codership developers cannot provide and sustain Galera if you don’t support them.
To buy Codership support, it is a very efficient way to get a quality service from the software producer, and at the same time to guarantee the future development of a product that allow you to make business.
Architecture
Now let start to talk about it.
After many installation and different combination of blocks, the following is for me the solution that identify the most flexible, scalable and solid solution to implement a MySQL cluster using Galera.
Normally if a customer asks me advice the following is my answer:
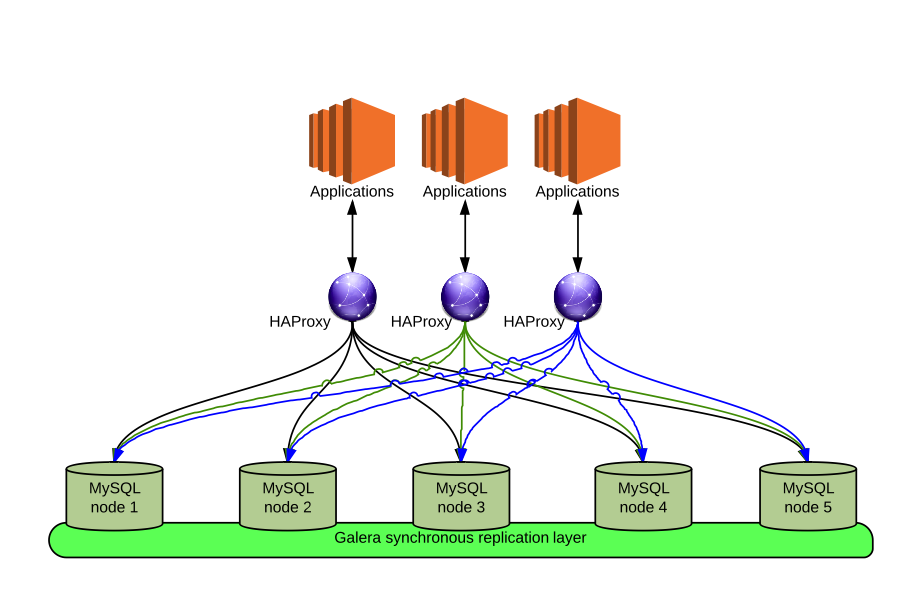
"The solution sees the HAProxy instance hosted directly on the application machine, the HAProxy then connect the application to the data layer rotating on them.
Given Codership had provide a check for HAProxy to recognize the status of the node in relation to his role, HAProxy is able to skip the MySQL nodes when those are in recover or Donor mode.
Our tests had shown that this approach is the most scalable in relation to Application/data connection, and at the same time is the one that reduce the impact to minimum, given each application tile is independent.
About MySQL this solution allow the data layer to scale both reads and writes. The scalability is anyhow limited by the amount of write and related bytes, which the data layer must share between nodes.
This is it; each MySQL node has a full copy of the dataset, as such each write or delete must be applying to all nodes.
The Galera replication layer is efficiently managing this effort, but efficiency is still dependant by the Data Storage and Network layer.
It is possible to have better understanding if this solution fulfils the requirements, calculating the real amount of traffic generated, and performing a projection.
Also a proof of concept is always suggested to validate the application functions against the MySQL/Galera cluster.
Pro
- Solution scales write and read, it also allow to have no service interruption when using a proxy solution like HAProxy which redirect the traffic In less then 5 seconds.
- MySQL nodes can be access at all times for read and write operation.
- Application can access database directly if needed, or can be configure as a tile with the HAProxy for better scalability.
- Specific check is provided to identify the internal status of MySQL/Galera node.
- The solution use InnoDB as storage engine, as such it will behave in a well known way, in responding to Read operations.
- This solution can scale out and scale in, quite easily, given that to scale out we just need to add a even number of MySQL servers, to an odd cluster.
- To scale in is just a matter to remove the nodes, from HAProxy and then turn the MySQL off.
Cons
- Data is not partitioned cross MySQL nodes, it is fully replicated on all the MySQL, as such a lot of space on disk will be used, (Data x Number of nodes) + (Binary logs size x number of nodes).
- When a node is recovering it will require a donor node, this will reduce the capacity of the Cluster of the failed node + the Donor. In case of a 3 nodes MySQL cluster, only one node will remain active, given that the recommended minimum number nodes on busy environment is five nodes.
- The solution has being tested on physical machines, Amazon EC2, and within different Zones, but it will require dedicated network cross-zone to prevent delay.
Minimum requirements
The minimum number of MySQL nodes for a cluster is 3, but if the application is critical to reduce possible issue when recovering a node, a cluster of 5 is strongly suggested.
Note that for quorum reasons the number of server must be odd.
Network between the nodes must be reliable and with low latency.
Best usage
Applications that require having write distribution and some scalability, with medium load of writes per second, and constant grow of the dataset size.
Uptime in nines
99. 995% that correspond to 26 minutes downtime per year.
Solution Availability
MySQL with Galera is a GA solution, so no cost in implementing it.
It is good practices to have a support contract with Codership as software provider, especially to have better reaction in case of bugs or feature requests."
Amen!
Implementation
Once you have identify your requirements, and dimension the machines (or cloud instances) that will host the MySQL Galera implementation, be sure to have one network channel to serve the MySQL-Application traffic, and a different one to serve the Galera replication layer, and a very efficient data storage layer.
To get help and advice on that you can contact me any time.
Basic requirements
Packages:
Xinetd
rsyslog
openssl-devel.x86_64
sysstat
iotop
netcat
htop
oprofile
Perl
Perl DBI
Perl DBD::mysql
Perl Time::HiRes
accepting network traffic from/to ports 3306 3307 3308 3311
HAPROXY for:
RH6: http://rpm.pbone.net/index.php3?stat=26&dist=74&size=440708&name=haproxy-1.4.8-1.el6.x86_64.rpm
MySQL Galera From Percona:
![]()
MariaDB Galera implementation
![]()
Codership (Oracle) Galera implementation
![]()
Configuration
The initial configuration is normally base on 5 or 7 MySQL galera node listening each other on the internal network.
The HAProxy will check MySQL using the code delivered by Codership which is recognizing the Galera state.
This check will be installed ONLY on the MySQL/Galera node usign port 3311, so no configuration is due in the HAProxy node.
The MySQL frontend will connect to application using HAProxy, each Application node will have his own HAProxy installation.
Each Application will then locally connect to HAProxy (127.0.0.1:3307) HAProxy will redirect the connection to final target.
The connections are distributed using RR (Round Robin) and are non persistent.
That is once the TCP/IP connection is close the same Application Node will have no guarantee to access the same server.
PORTS:
- HAProxy will listening on port 3307
- HAProxy will show status using HTTP client on port 3308
- MySQL will be listening on port 3306
- MySQL check for HAProxy will operate on port 3311
MySQL:
adjust the standard parameter to fit the hosting environment.

NOTE!! for innodb_io_capacity Run FIO or IOZONE to discover the real IOPS available and adjust the parameter to that value, just guessing is not what you want in production.
Galera:
In line of principle the WSREP settings are tuned during the POC, but possible fine-tuning could be require when moving to production.
I advise you to spend some time to check and tune the following.
wsrep_max_ws_rows= 131072 wsrep_max_ws_size= 2147483648 wsrep_slave_threads= 48 wsrep_provider_options="gcache.size=10240M; evs.send_window=512; evs.user_send_window=512"
Parameters to keep an eye on are the send/receive queue and the GCACHE.SIZE.
About this there is something that must be clarify and why is very important to set it large enough.
First of all you should understand that when a node become a DONOR the server will not be accessible for write operation, as such it will be removed by HAProxy from the pool until the node has finished to feed the JOINER.
Galera has two ways of synchronizing a starting or recovering node.
IST and SST.
IST
When performing a synchronization with IST, Galera will send over to the resarting node ONLY the information present in the GCache, this can be see an INCREMENTAL update.
For instance, if you have a cluster of 5 nodes and for maintenance reasons you need to put them down on rotation, the node that will remain down will loose a set of operation during the maintenance time.
When you start back Galera read the last position the node has locally registered, and will request from the donor to start from there. If the DONOR still has that position in the GCache it will send to the restarting node the data from there.
This operation is normally much faster and has very limited impact also on the DONOR.
SST
This is a rebuild from scratch; normally it applies when the node is started the first time, and/or when it crashes.
The operation can be very time consuming when talking of dataset of some consistencies.
There are several methods that can be used for SST, from mysqldump to Xtrabackup. I have choose almost always to use the Xtrabackup, which is very well integrated in the Percona Galera distribution and guarantee performance and data safety.
But obviously when you are in the need to backup several hundreds of gigabytes, the process will take some time. Or if you have a very high level of inserts and say one or two hundreds of gigabytes, again the combination of time and datasize will be fatal.
The main point is that in these cases the time Galera will take the DONOR down in order to backup and trasmit the data to the JOINER, will be too long after for the DONOR node to recover from his Gcache once finish the operation, transforming the DONOR in an additional JOINER.
I have being observing this on cascade effect on several cluster not configured correctly, in relation to their traffic and data size.
Clusters of 7 or more nodes, just going on hold because the nodes were not able to store enough information on gcache. It is true that when Galera is left with one node, given it is in DONOR mode it stops to write allowing the cluster to heal itself. But it is also tru that this could be a very long operation and in production is quite distruptive.
So what to do? Easy just calculate before what is the worse scenario for you, then dimension the GCache to be at least 1/3 bigger then that is not more. Try to be safe, and stay on IST, this very important if you have a very high level of writes.
What I do is that Gcache must be large enough to guarantee modification statements for the double of the time needed to take a full backup.
IE.
With five node, and a set of binary log of 20GB per day.
If a full backup with XTRABACKUP takes 6Hrs the GCACHE size should be:
GCache = ((BS x (tb/hrsDat )) x Mn) x 2
GCache = ((20 x (4/24)) x 5 )* 2 = ~33.3GB
BS - size of the binlog
Tb - Time for the backup in hours in a day
Mn - MySQLGalera nodes
hrsDat Hours in a day (24)
This should be sufficient to have a decent amount of time and space to be safe.
Finally rememeber that Galera with Xtrabackup REQUIRE perl with DBI DBD::mysql in place or synchronization will fail!
Main steps
1) configure the environment
- install xinetd (if not present)
- create user
- create directory layout
- download software for MySQL/Galera
- Install HAProxy
2) Deploy the first MySQL Galera node
- create the basic mysql database
- create basic grants
- test and cleanup the other accounts
3) Deploy all other nodes
4) Deploy HAProxy
- review configuration and change in relation to the network
- start HAProxy
5) Test connection from client to HAProxy
6) Perform test to validate the installation
7) Load data set
Step by step
configure the environment
1) Install basic tools, if cusomer agreed:
yum -y install htop/sysstat/screen/xinetd/haproxy/iotop/nc
rpm -Uvh http://mirrors.kernel.org/fedora-epel/6/i386/epel-release-6-8.noarch.rpm
or
rpm -Uvh http://mirrors.kernel.org/fedora-epel/5/i386/epel-release-5-4.noarch.rpm
2) If you like run inside a screen so if you need you can detach and not interfere with the installtion process
screen -h 50000 -S MySQLINSTALL
3) Check if ANY MySQL daemon is present (RPM) and running, in case remove it
ps aux|grep mysql rpm -qa |grep -i MySQL rpm -e --nodeps Or -ev --allmatches rpm -qa |grep MySQL #Remove OLD for bin in 'ls -D /usr/local/mysql/bin/'; do rm -f /usr/bin/$bin; done for lib in 'ls -D /usr/local/mysql/lib/libmysqlclient*'; do rm -f /usr/lib64mysql/$lib; done for bin in 'ls -D /usr/local/xtrabackup/bin/'; do rm -f /usr/bin/$bin; done
3) create user and the directory structure
userdel mysql rm -fr /home/mysql/ groupadd mysql useradd -m -g mysql -s /bin/bash -m -d /home/mysql mysql passwd mysql mkdir/opt/mysql_templates/ ln -s /usr/local/mysql -> /opt/mysql_templates/
IN case of binary use
5) Download the mysql version
wget http://www.percona.com/redir/downloads/Percona-XtraDB-Cluster/LATEST/binary/linux/x86_64/Percona-XtraDB-Cluster-5.5.30-23.7.4.405.Linux.x86_64.tar.gz tar -xzf Percona-XtraDB-Cluster-5.5.30-23.7.4.405.Linux.x86_64.tar.gz wget http://www.percona.com/redir/downloads/XtraBackup/LATEST/binary/Linux/x86_64/percona-xtrabackup-2.1.3-608.tar.gz tar -xzf percona-xtrabackup-2.1.3-608.tar.gz
6) Create symbolic links to /usr/local
ln -s /opt/mysql_templates/Percona-XtraDB-Cluster-5.5.30-23.7.4.405.Linux.x86_64 /usr/local/mysql ln -s /opt/mysql_templates/percona-xtrabackup-2.1.3 /usr/local/xtrabackup
7) Create symbolic links to /usr/bin
#Install new for bin in 'ls -D /usr/local/mysql/bin/'; do ln -s /usr/local/mysql/bin/$bin /usr/bin/$bin; done for bin in 'ls -D /usr/local/xtrabackup/bin/'; do ln -s /usr/local/xtrabackup/bin/$bin /usr/bin/$bin; done
#Set security for bin in 'ls -D /usr/local/mysql/bin/'; do chmod +x /usr/bin/$bin; done for bin in 'ls -D /usr/local/xtrabackup/bin/'; do chmod +x /usr/local/xtrabackup/bin/$bin /usr/bin/$bin; done
8) Move the service script from the original directory
mv /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld or /etc/init.d/mysql/mysqld
Edit the file filling the basedir and datadir variables, this is not always needed.
9) Edit my.cnf to match the path and set initial values
10) Reset security
chown -R mysql:mysql /opt/mysql_templates chmod +x /usr/local/mysql
Configure HAProxy check
Require:
xinetd
/usr/bin/clustercheck
the file clustercheck comes directly with the Percona distribution, you just to be sure that is in the path for the execution.
1) set haproxy check
prepared file (mysqlchk):
vi /etc/xinext.d/mysqlchk
# default: on # description: mysqlchk service mysqlchk { # this is a config for xinetd, place it in /etc/xinetd.d/ disable = no flags = REUSE socket_type = stream port = 3311 wait = no user = nobody server = /usr/bin/clustercheck log_on_failure += USERID only_from = 0.0.0.0 # recommended to put the IPs that need # to connect exclusively (security purposes) per_source = UNLIMITED }
2) check for free port
cat /etc/services |grep 3311
add service mysqlchk /etc/services
echo "mysqlchk 3311/tcp # mysqlchk" >> /etc/services
3) add to /etc/xinetd.d/ the configuration for mysqlchk services
restart xinetd
4) Check it
telnet 127.0.0.1 3311 Trying 127.0.0.1... Connected to localhost.localdomain (127.0.0.1). Escape character is '^]'. HTTP/1.1 200 OK Content-Type: text/plain Connection: close Content-Length: 40 Percona XtraDB Cluster Node is synced. Connection closed by foreign host.
Perl setup
You should do this the way you are more comfortable, anyhow be carefull on not doing double installation between yum/apt-get and cpan. These two way by default install library in different places, and will give you a nightmare in cleaning the mess and library conflict.
Be sure to have DBI and DBD installed where DBD::mysql should be version perl-DBD-MySQL-4.019 or newer.
Deploy the first MySQL Galera node
1) Create initial MySQL database FOR BINARY INSTALL ONLY:
su - mysql cd /usr/local/mysql/ ./scripts/mysql_install_db --defaults-file=/etc/my.cnf
Carefully check the output you should see OK twice, if not check the error log.
2) Start mysql
/etc/init.d/mysqld start --wsrep_cluster_address=gcomm://
Check the error log for possible errors
tail -fn 200
3) connect for the first time and change security
Grant access for xtrabackup
Grant access to haproxy checks
Remove generic users:
4) collect statistics and informations:
5) Stop server
6) restart server
/etc/init.d/mysqld start --wsrep_cluster_address=gcomm://
Deploy all other nodes
On each node:
1) modify the server identification in the my.cnf
wsrep_node_name=pchgny1 <------------ server-id=1 <----------------
2) start the node checking the mysql log
/etc/init.d/mysqld start
Deploy HAProxy
Connect on the appliction servers and perform the HAProxy installation.
wget the HAProxy package related to the host OS rpm -iUvh haproxy-1.4.22-4.el6_4.x86_64.rpm
1) Set the configuration file on each HAProxy node
In line of principle HAProxy is quite efficient to monitor and report the status of the nodes on his HTML interface when using the HTTP protocol, this is not true when using the TCP.
Given that, I was using the trick to use the HTTP protocol on a different port, just with the scope of reporting.
#--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global # to have these messages end up in /var/log/haproxy.log you will # need to: # # 1) configure syslog to accept network log events. This is done # by adding the '-r' option to the SYSLOGD_OPTIONS in # /etc/sysconfig/syslog # # 2) configure local2 events to go to the /var/log/haproxy.log # file. A line like the following can be added to # /etc/sysconfig/syslog # # local1.* /var/log/haproxy.log # log 127.0.0.1 local1 notice maxconn 40096 user haproxy group haproxy daemon # turn on stats unix socket #stats socket /var/lib/haproxy/stats #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode http log global option tcplog option dontlognull option redispatch retries 3 maxconn 4096 contimeout 160000 clitimeout 240000 srvtimeout 240000 #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- listen stats 0.0.0.0:3308 mode http stats enable # stats hide-version stats scope . stats realm Haproxy\ Statistics stats uri /haproxy?stats stats refresh 5s # stats auth xxxxx:xxxxx option contstats option httpchk # option mysql-check user test server node1 10.5.1.6:3306 check port 3311 inter 2000 rise 3 fall 3 server node3 10.5.1.8:3306 check port 3311 inter 2000 rise 3 fall 3 server node4 10.5.1.9:3306 check port 3311 inter 2000 rise 3 fall 3 server node5 10.5.1.10:3306 check port 3311 inter 2000 rise 3 fall 3 listen galera_cluster 0.0.0.0:3307 #Logging log global option dontlognull #mode mode tcp # balancer balance roundrobin #options # option abortonclose # option forceclose option clitcpka option tcpka option httpchk # option mysql-check user testserver node1 10.5.1.6:3306 check port 3311 inter 2000 rise 3 fall 3 server node3 10.5.1.8:3306 check port 3311 inter 2000 rise 3 fall 3 server node4 10.5.1.9:3306 check port 3311 inter 2000 rise 3 fall 3 server node5 10.5.1.10:3306 check port 3311 inter 2000 rise 3 fall 3
2) add logging
to add logging using rsyslog
vim /etc/rsyslog.conf
Modify enabling, the following:
# Provides UDP syslog reception $ModLoad imudp.so $UDPServerRun 514
and add
#HAProxy log local1.* /var/log/haproxy.log
Finally restart rsyslog
/etc/init.d/rsyslog restart
2) start HAProxy
/etc/init.d/haproxy start
3) check sever status using the web interface
Using a web browser check from:
http://:3308/haproxy?stats
You will see, or you SHOULD see, the HTML page reporting the status of your nodes.
Quick check for the connection
Connect to MySQL using mysql client and simple whatch to cycle the servers.
watch -n1 -d 'mysql -udbaadmin -p -h -e "Show global status"| grep -E
"wsrep_ready|wsrep_last_committed|wsrep_replicated|wsrep_received|wsrep_local_commits|wsrep_local_cert_failures|wsrep_local_bf_aborts|wsrep_local_send_queue|wsrep_local_recv_queue|wsrep_local_state_comment"'
To see how HAProxy redirect the connections from the APPLICATION NODE:
watch -n1 -d 'mysql -h127.0.0.1 -P3307 -u -p -e "Show global variables"| grep -i -E "server_id|wsrep_node_name"'
You will see the values changing at each request.
Try to put down one node and see what happen on the web interface of HAProxy and at the running command.
If all is fine it will be quite fun to see how easy and fast it manage the shutting down node.
POC steps
Finally this is just an example of what we do cover when doing the POC, it obviously vary from customer to customer.
POC Tests
Functional tests:
- perform data read on all nodes
No difference in the result sets between nodes.
Recovery perform by SST if bigger then cache
Performance/capacity tests (including difference in using ONE single node, Three to seven nodes, full capacity):
- threads contention
- threads contention
Same test as 1.2 and 1.3
Additional article about galera
There are few forthcoming articles I am writing following the same serie:
Galera understanding what to monitor and how
Galera tests and numbers, what I have prove is it possible to achieve in numbers and graphs.
Reference
Jay (Percona)
https://www.percona.com/live/mysql-conference-2013/users/jay-janssen
Oli (FromDual)
http://www.fromdual.com/mysql-and-galera-load-balancer
http://www.fromdual.com/galera-load-balancer-documentation
http://www.fromdual.com/unbreakable-mysql-cluster-with-galera-and-lvs
http://www.fromdual.com/switching-from-mysql-myisam-to-galera-cluster
http://www.fromdual.com/galera-cluster-nagios-plugin-en
Codership
http://www.codership.com/wiki/doku.php?id=mysql_options_0.8
http://www.codership.com/wiki/doku.php?id=galera_parameters
http://www.codership.com/wiki/doku.php?id=galera_status_0.8
http://www.codership.com/wiki/doku.php?id=flow_control
http://www.codership.com/wiki/doku.php?id=galera_arbitrator
http://www.codership.com/wiki/doku.php?id=sst_mysql
http://www.codership.com/wiki/doku.php?id=ist
Several Nines
http://www.severalnines.com/clustercontrol-mysql-galera-tutorial
http://www.severalnines.com/blog/migrating-mysql-galera-cluster-new-data-center-without-downtime