If you met one of the (few) MySQL consultants around the globe and asked him/her to review your queries and/or schemas, I am sure that he/she would tell you something regarding the importance of good primary key(s) design. Especially in the case of InnoDB, I’m sure they started to explain to you about index merges and page splits. These two notions are closely related to performance, and you should take this relationship into consideration when designing any index (not just PKs).
That may sound like mumbo jumbo to you, and you may be right. This is not easy stuff, especially when talking about internals. This is not something you deal with on a regular basis, and often you don’t want to deal with it at all.
But sometimes it’s a necessity. If so, this article is for you.
In this article, I want to shed some light in explaining some of the most unclear, behind the scenes operations in InnoDB: page index creation, page merging and page splitting.
In Innodb all data is an index. You’ve probably heard that as well right? But what exactly does that mean?
File-Table Components
Let's say you have MySQL installed, the latest 5.7 version (Percona Server for MySQL, right? ), and you have a table named wmills in the schema windmills. In the data directory (normally /var/lib/mysql/) you will see that it contains:
data/
windmills/
wmills.ibd
wmills.frm
This is because the parameter innodb_file_per_table is set to 1 since MySQL 5.6. With that setting, each table in your schema is represented by one file (or many files if the table is partitioned).
What is important here is that the physical container is a file named wmills.ibd. This file is broken up into and contains N number of segments. Each segment is associated with an index.
While a file’s dimensions do not shrink with row-deletions, a segment itself can grow or shrink in relation to a sub-element named extent. An extent can only exist inside a segment and has a fixed dimension of 1MB (in the case of default page size). A page is a sub-element of an extent and has a default size of 16KB.
Given that, an extent can contain a maximum of 64 pages. A page can contain two to N number of rows. The number of rows a page can contain is related to the size of the row, as defined by your table schema. There is a rule within InnoDB that says, at minimum, two rows must fit into a page. Therefore, we have a row-size limit of 8000 bytes.
If you think this sounds like Matryoshka dolls, you are right! An image might help:

InnoDB uses B-trees to organize your data inside pages across extents, within segments.
Roots, Branches, and Leaves
Each page (leaf) contains 2-N rows(s) organized by the primary key. The tree has special pages to manage the different branch(es). These are known as internal nodes (INodes).
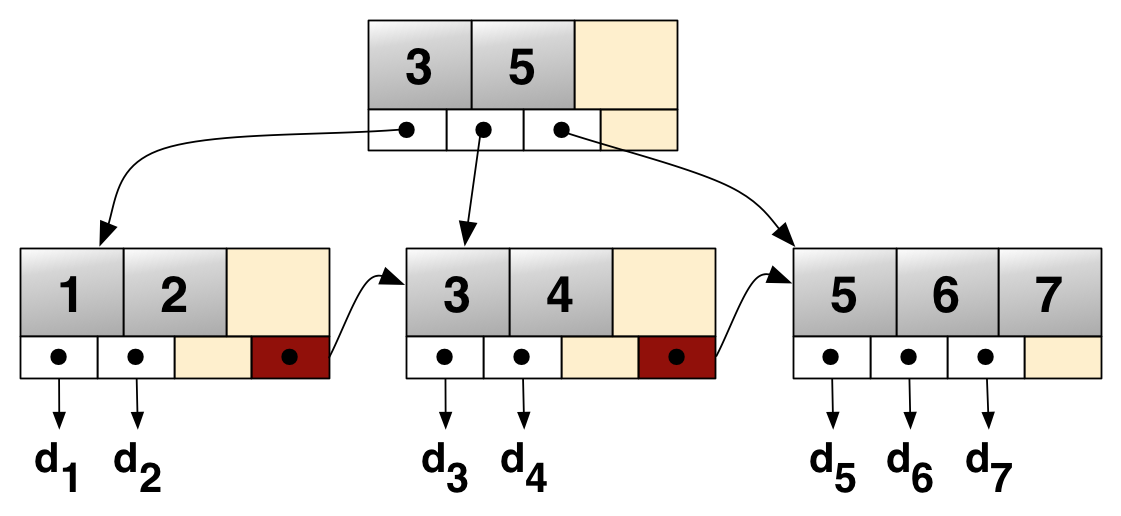
This image is just an example, and is not indicative of the real-world output below.
Let’s see the details:
ROOT NODE #3: 4 records, 68 bytes NODE POINTER RECORD ≥ (id=2) → #197 INTERNAL NODE #197: 464 records, 7888 bytes NODE POINTER RECORD ≥ (id=2) → #5 LEAF NODE #5: 57 records, 7524 bytes RECORD: (id=2) → (uuid="884e471c-0e82-11e7-8bf6-08002734ed50", millid=139, kwatts_s=1956, date="2017-05-01", lo
Below is the table structure:
CREATE TABLE `wmills` ( `id` bigint(11) NOT NULL AUTO_INCREMENT, `uuid` char(36) COLLATE utf8_bin NOT NULL, `millid` smallint(6) NOT NULL, `kwatts_s` int(11) NOT NULL, `date` date NOT NULL, `location` varchar(50) COLLATE utf8_bin DEFAULT NULL, `active` tinyint(2) NOT NULL DEFAULT '1', `time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `strrecordtype` char(3) COLLATE utf8_bin NOT NULL, PRIMARY KEY (`id`), KEY `IDX_millid` (`millid`) ) ENGINE=InnoDB;
All styles of B-trees have a point of entry known as the root node. We’ve identified that here as page #3. The root page contains information such as index ID, number of INodes, etc. INode pages contain information about the pages themselves, their value ranges, etc. Finally, we have the leaf nodes, which is where we can find our data. In this example, we can see that leaf node #5 has 57 records for a total of 7524 bytes. Below that line is a record, and you can see the row data.
The concept here is that while you organize your data in tables and rows, InnoDB organizes it in branches, pages, and records. It is very important to keep in mind that InnoDB does not work on a single row basis. InnoDB always operates on pages. Once a page is loaded, it will then scan the page for the requested row/record.
Is that clear up to now? Good. Let’s continue.
Page Internals
A page can be empty or fully filled (100%). The row-records will be organized by PK. For example, if your table is using an AUTO_INCREMENT, you will have the sequence ID = 1, 2, 3, 4, etc.

A page also has another important attribute: MERGE_THRESHOLD. The default value of this parameter is 50% of the page, and it plays a very important role in InnoDB merge activity:

While you insert data, the page is filled up sequentially if the incoming record can be accommodated inside the page.
When a page is full, the next record will be inserted into the NEXT page:

Given the nature of B-trees, the structure is browsable not only top-down following the branches, but also horizontally across the leaf nodes. This is because each leaf node page has a pointer to the page that contains the NEXT record value in the sequence.
For example, Page #5 has a reference to the next page, Page #6. Page #6 has references backward to the previous page (Page #5) and a forward to the next page (Page #7).
This mechanism of a linked list allows for fast, in-order scans (i.e., Range Scans). As mentioned before, this is what happens when you are inserting and have a PK based on AUTO_INCREMENT. But what happens if I start to delete values?
Page Merging
When you delete a record, the record is not physically deleted. Instead, it flags the record as deleted and the space it used becomes reclaimable.

When a page has received enough deletes to match the MERGE_THRESHOLD (50% of the page size by default), InnoDB starts to look to the closest pages (NEXT and PREVIOUS) to see if there is any chance to optimize the space utilization by merging the two pages.
In this example, Page #6 is utilizing less than half of its space. Page #5 received many deletes and is also now less than 50% used. From InnoDB’s perspective, they are mergeable:

The merge operation results in Page #5 containing its previous data plus the data from Page #6. Page #6 becomes an empty page, usable for new data.

The same process also happens when we update a record and the size of the new record brings the page below the threshold.
The rule is: Merges happen on delete and update operations involving close linked pages.
If a merge operation is successful, the index_page_merge_successful metric in INFORMATION_SCHEMA.INNODB_METRICS is incremented.
Page Splits
As mentioned above, a page can be filled up to 100%. When this happens, the next page takes new records.
But what if we have the following situation?

Page #10 doesn’t have enough space to accommodate the new (or updated) record. Following the next page logic, the record should go on Page #11. However:

Page #11 is also full, and data cannot be inserted out of order. So what can be done?
Remember the linked list we spoke about? At this moment Page #10 has Prev=9 and Next=11.
What InnoDB will do is (simplifying):
- Create a new page
- Identify where the original page (Page #10) can be split (at the record level)
- Move records
- Redefine the page relationships

A new Page #12 is created:

Page #11 stays as it is. The thing that changes is the relationship between the pages:
- Page #10 will have Prev=9 and Next=12
- Page #12 Prev=10 and Next=11
- Page #11 Prev=12 and Next=13
The path of the B-tree still sees consistency since it is following a logical organization. However, physically the page is located out of order, and in most cases in a different extent.
As a rule we can say: Page splits happens on Insert or Update, and cause page dislocation (in many cases on different extents).
InnoDB tracks the number of page splits in INFORMATION_SCHEMA.INNODB_METRICS. Look for index_page_splits and index_page_reorg_attempts/successful metrics.
Once the split page is created, the only way to move back is to have the created page drop below the merge threshold. When that happens, InnoDB moves the data from the split page with a merge operation.
The other way is to reorganize the data by OPTIMIZE the table. This can be a very heavy and long process, but often is the only way to recover from a situation where too many pages are located in sparse extents.
Another aspect to keep in mind is that during merge and split operations, InnoDB acquires an x-latch to the index tree. On a busy system, this can easily become a source of concern. This can cause index latch contention. If no merges and splits (aka writes) touch only a single page, this is called an “optimistic” update in InnoDB, and the latch is only taken in S. Merges and splits are called “pessimistic” updates, and take the latch in X.
My Primary Key
A good Primary Key (PK) is not only important for retrieving data, but also correctly distributing the data inside the extents while writing (which is also relevant in the case of split and merge operations).
In the first case, I have a simple auto-increment. In the second my PK is based on an ID (1-200 range) and an auto-increment value. In my third, I have the same ID (1-200 range) but associate with a UUID.
When inserting, InnoDB must add pages. This is read as a SPLIT operation:
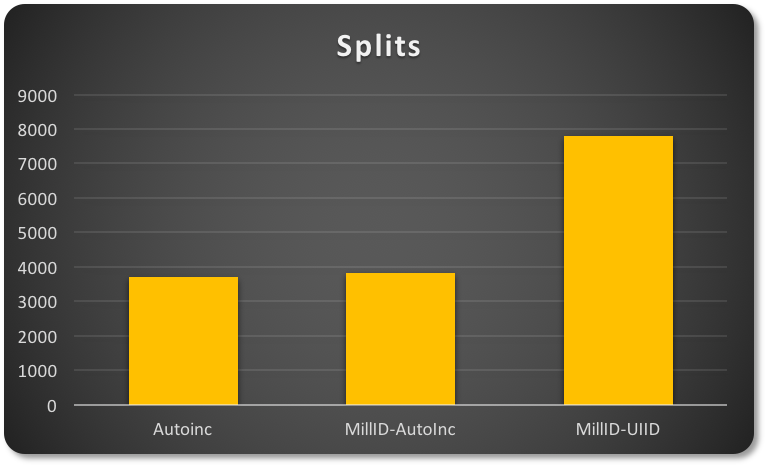
The behavior is quite different depending on the kind of Primary Key I use.
The first two cases will have more “compact” data distribution. This means they will also have better space utilization, while the semi-random nature of the UUID will cause a significant “sparse” page distribution (causing a higher number of pages and related split operations).
In the case of merges, the number of attempts to merge is even more different by PK type.
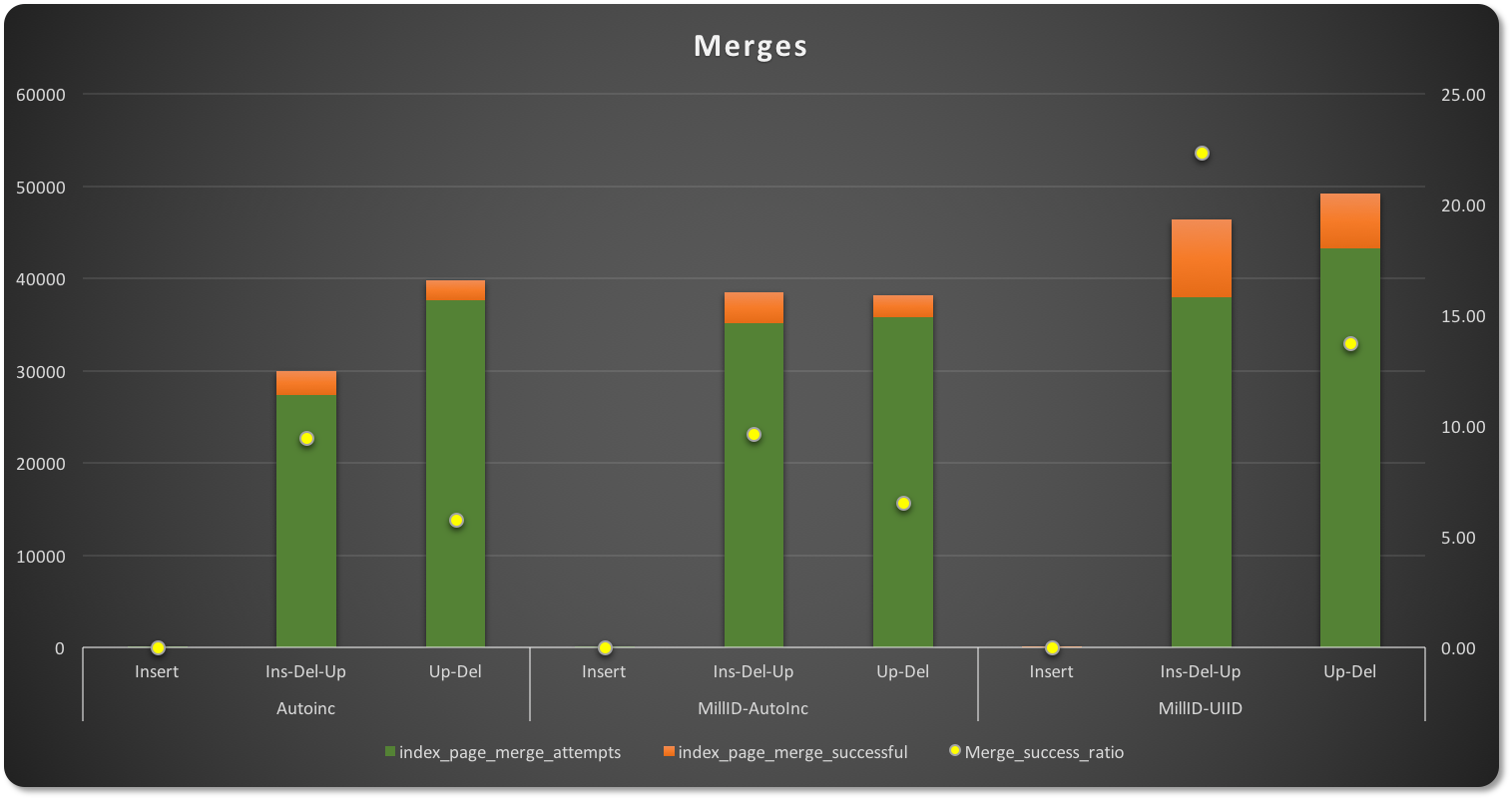
On Insert-Update-Delete operations, auto-increment has less page merge attempts and 9.45% less of a success ratio than the other two types. The PK with UUID (on the side other of the spectrum) has a higher number of merge attempts, but at the same time also a significantly higher success ratio at 22.34%, given that the “sparse” distribution left many pages partially empty.
The PK values with similar numbers also come from a secondary index.
Conclusion
MySQL/InnoDB constantly performs these operations, and you have very limited visibility of them. But they can bite you, and bite hard, especially if using a spindle storage VS SSD (which have different issues, by the way).
The sad story is there is also very little we can do to optimize this on the server side using parameters or some other magic. But the good news is there is A LOT that can be done at design time.
Use a proper Primary Key and design a secondary index, keeping in mind that you shouldn’t abuse of them. Plan proper maintenance windows on the tables that you know will have very high levels of inserts/deletes/updates.
This is an important point to keep in mind. In InnoDB you cannot have fragmented records, but you can have a nightmare at the page-extent level. Ignoring table maintenance will cause more work at the IO level, memory and InnoDB buffer pool.
You must rebuild some tables at regular intervals. Use whatever tricks it requires, including partitioning and external tools (pt-osc). Do not let a table to become gigantic and fully fragmented.
Wasting disk space? Need to load three pages instead one to retrieve the record set you need? Each search causes significantly more reads?
That’s your fault; there is no excuse for being sloppy!
Happy MySQL to everyone!
Acknowledgments
Laurynas Biveinis: who had the time and patience to explain some internals to me.
Jeremy Cole: for his project InnoDB_ruby (that I use constantly).