 MySQL High Availability. Shutterstock.com[/caption] In this article, we'll look at an example of an on-premises, geographically distributed MySQL high availability solution. It's part of a longer series on some high availability reference architecture solutions over geographically distributed areas. Part 1: Reference Architecture(s) for High Availability Solutions in Geographic Distributed Scenarios: Why Should I Care? Percona consulting's main aim is to identify simple solutions to complex problems. We try to focus on identifying the right tool, a more efficient solution, and what can be done to make our customers' lives easier. We believe in doing the work once, doing it well and have more time afterward for other aspects of life. In our journey, we often receive requests for help – some simple, some complicated.
MySQL High Availability. Shutterstock.com[/caption] In this article, we'll look at an example of an on-premises, geographically distributed MySQL high availability solution. It's part of a longer series on some high availability reference architecture solutions over geographically distributed areas. Part 1: Reference Architecture(s) for High Availability Solutions in Geographic Distributed Scenarios: Why Should I Care? Percona consulting's main aim is to identify simple solutions to complex problems. We try to focus on identifying the right tool, a more efficient solution, and what can be done to make our customers' lives easier. We believe in doing the work once, doing it well and have more time afterward for other aspects of life. In our journey, we often receive requests for help – some simple, some complicated.
Scenario
The company "ACME Inc." is moving its whole business from a monolithic application to a distributed application, split into services. Each different service deals with the requests independently from each other. Some services follow the tightly-bounded transactional model, and others work/answer asynchronously. Each service can access the data storage layer independently. In this context, ACME Inc. identified the need to distribute the application services over wide geographic regions, focusing on each region achieving scale independently. The identified regions are:
- North America
- Europe
- China
ACME Inc. is also aware of the fact that different legislation acts on each region. As such, each region requires independent information handling about sales policies, sales campaigns, customers, orders, billing and localized catalogs, but will share the global catalog and some historical aggregated data. While most of the application services will work feeding and reading local distributed caches, the basic data related to the catalog, sales and billing is based on an RDBMS. Historical data is instead migrated to a “Big Data” platform, and aggregated data is elaborated and push to a DWH solution at HQ. The application components are developed using multiple programming languages, depending on the service. The RDBMS identified by ACME Inc. in collaboration with the local authorities was MySQL-oriented. There were several solutions like:
- PostgreSQL
- Oracle DB
- MS SQL server
We excluded closed-source RDBMSs given that some countries imposed a specific audit plugin. This plugin was only available for the mentioned platforms. The cost of parallel development and subsequent maintenance in case of RDBMS diversification was too high. As such all the regions must use the same major RDBMS component. We excluded PostgreSQL given that compared to the adoption of MySQL, utilization cases were higher and MySQL had a well-defined code producer. Finally, the Business Continuity team of ACME Inc., had defined an ITSC (Information Technology Service Continuity) plan that defined the RPO (Recovery Point Objective), the RTO (Recovery Time Objective) and system redundancy. That’s it. To fulfill the ITSCP, each region must have the critical system redundantly replicated in the same region, but not on the proximity.
Talking About the Components
This is a not-so-uncommon scenario, and it also presents a lot of complexity if you try to address it with one solution. But let's analyze it and see how we can simplify the approach while still meeting the needs and requirements of ACME Inc. When using MySQL-based solutions, the answer to "what should we use?" is use what best fits your business needs. The "nines" availability reference table for the MySQL world (most RDBMSs) can be summarized below:
9 0. 0 0 0 % (36 days) MySQL Replication
9 9. 9 0 0 % (8 hours) Linux Heartbeat with DRBD (Obsolete DRBD)
9 9. 9 0 0 % (8 hours) RHCS with Shared Storage (Active/Passive)
9 9. 9 9 0 % (52 minutes) MHA/Orchestrator with at least three nodes
9 9. 9 9 0 % (52 minutes) DRBD and Replication (Obsolete DRBD)
9 9 .9 9 5 % (26 minutes) Multi-Master (Galera replication) 3 node minimum
9 9. 9 9 9 % (5 minutes) MySQL Cluster
An expert will tell you that it always doesn't make sense to go for the most "nines" in the list. This because each solution comes with a tradeoff: the more high availability (HA) you get, the higher the complexity of the solution and in managing the solution. For instance, the approach used in MySQL Cluster (NDB) makes this solution not suitable for generic utilization. It requires proper analysis of the application needs, data utilization and archiving before being selected. It also requires in-depth knowledge to properly manage the cluster, as it is more complex than other similar solutions. This indirectly makes a solution based on MySQL+Galera replication the one with the highest HA level a better choice, since it is close to the defaults generalized utilizations. This is why MySQL+Galera replication has become in the last six years the most used solution for platform looking for very high HA, without the need to diverge from standard MySQL/InnoDB approach. You can read more about Galera replication: http://galeracluster.com/products/ Read more about Percona XtraDB Cluster. There are several distributions implementing Galera replication:
- Codership (Galera software producer/owner): http://galeracluster.com/downloads/#downloads
- *MariaDB: https://mariadb.com/kb/en/library/what-is-mariadb-galera-cluster/
- Percona XtraDB Cluster: https://www.percona.com/downloads/Percona-XtraDB-Cluster-LATEST/
*Note that MariaDB Cluster/Server and all related solutions coming from MariaDB have significantly diverged from the MySQL mainstream. This often means that once migrated to MariaDB; your database will not be compatible with other MySQL solutions. In short, you are locked-in to MariaDB. It is recommended that you carefully evaluate the move to MariaDB before making that move.
Choosing the Components
RDBMS
Our advice is to use Percona XtraDB Cluster (PXC), because at the moment it is one of the most flexible and reliable and compatible solutions. PXC is composed of three main components:
- Percona Server for MySQL
- Percona XtraBackup
- Galera Replication library
The cluster is normally composed of three nodes or more. Each node can be used as a Master, but the preferred and recommended way is to use one node as a Writer and the other as Readers. Application-wise, accessing the right node can be challenging since this means you need to be aware of which node is the writer, which is the reader, and be able to shift from one to the other if necessary.
Proxy
To simplify this process, it helps to have an additional component that works as a “proxy” connecting the application layer to the desired node(s). The most popular solutions are:
- HAProxy
- ProxySQL
There are several important differences between the two. But in summary, ProxySQL is a Level 7 proxy and is MySQL protocol aware. So, while HAProxy is just passing the connection over as a forward proxy (level 4), ProxySQL is aware of what is going through it and acts as reverse proxy. With ProxySQL is possible to decide, based on several parameters, where to send traffic (read/write split and more), what must be stopped, or if we should rewrite an incoming SQL command. A lot of information is available on the ProxySQL website https://github.com/sysown/proxysql/wiki and on the Percona Database Performance Blog .
Backup/Restore
No RDBMS platform is safe without a well-tested procedure for backup and recovery. The Percona XtraDB Cluster package distribution comes with Percona XtraBackup as the default method for node provisioning. A good backup and restore (B/R) policy start from the consideration of ACME's ITSCP, to have full and incremental backups, perfectly covering the RPO, and a good recovery procedure to keep the recovery time inside RTO whenever possible. There are several tools that allow you to plan and execute backup/restore procedure, some coming from vendors other than open source and community-oriented. In respect to being a fully open source and community-oriented, we in consulting normally suggest using: https://github.com/dotmanila/pyxbackup. Pyxbackup is a wrapper around XtraBackup that helps simplify the B/R operations, including the preparation of a full and incremental set. This helps significantly reduce the recovery time.
Disaster Recovery
Another very important aspect of the ITSC Plan is the capacity of the system to survive to major disasters. The disaster and recovery (DR) solution must be able to act as the main production environment. Therefore, it must be designed and scaled as the main production site in resources. It must be geographically separated, normally hundreds of kilometers or more. It must be completely independent of the main site. It must be as much as possible in sync with the main production site. While the first three “musts” are easy to understand, the fourth one is often the object of misunderstanding. The concept of be as much in sync with the production site as possible creates confusion in designing HA solutions with Galera replication involved. The most common misunderstanding is the misuse of the Galera replication layer. Mainly the conceptual confusion between tightly coupled database cluster and loosely coupled database cluster. Any solution based on Galera replication is a tightly coupled database cluster, because the whole idea is to be data-centric, synchronously distributed and consistent. The price is that this solution cannot be geographically distributed. Solutions like standard MySQL replication are instead loosely coupled database cluster and they are designed to be asynchronous. Given that, the nodes connected by it are completely independent in processing/apply the transaction, and the solution fits perfectly into ANY geographically distributed replication solution. The price is that data on the receiving front might not be up to date with the one from the source in that specific instant. The point is that for the DR site the ONLY valid solution is the asynchronous link (loosely coupled database cluster), because by design and requirement the two sites must be separated by a significant number of kilometers. For better understanding about why synchronous replication cannot work in a geographically distributed scenario, see "Misuse of Geographic Node distribution with Galera-based replication". In our scenario, the use of Percona XtraDB Cluster helps to create a most robust asynchronous solution. This is because each tightly coupled database cluster, no matter if source or destination, will be seen by the other tightly coupled database cluster as a single entity. What it means is that we can shift from one node to another inside the two clusters, still confident we will have the same data available and the same asynchronous stream passing from one source to the other. To ensure this procedure is fully automated, we add to our architecture the last block: replication manager for Percona XtraDB Cluster (https://github.com/y-trudeau/Mysql-tools/tree/master/PXC). RMfP is another open source tool that simplifies and automates failover inside each PXC cluster such that our asynchronous solution doesn't suffer if the node is currently acting as Master fails.
How to Link the Components
Summarizing all the different components of our solution:
- Application stack
- Load balancer
- Application nodes by service
- Distributed caching
- Data access service
- Database stack
- Data proxy (ProxySQL)
- RDBMS (Percona XtraDB Cluster)
- Backup/Restore
- Xtrabackup
- Pyxbackup
- Custom scripts
- DR
- Replication Manager for Percona XtraDB Cluster
- Monitoring
- PMM (not covered here see <link> for detailed information)
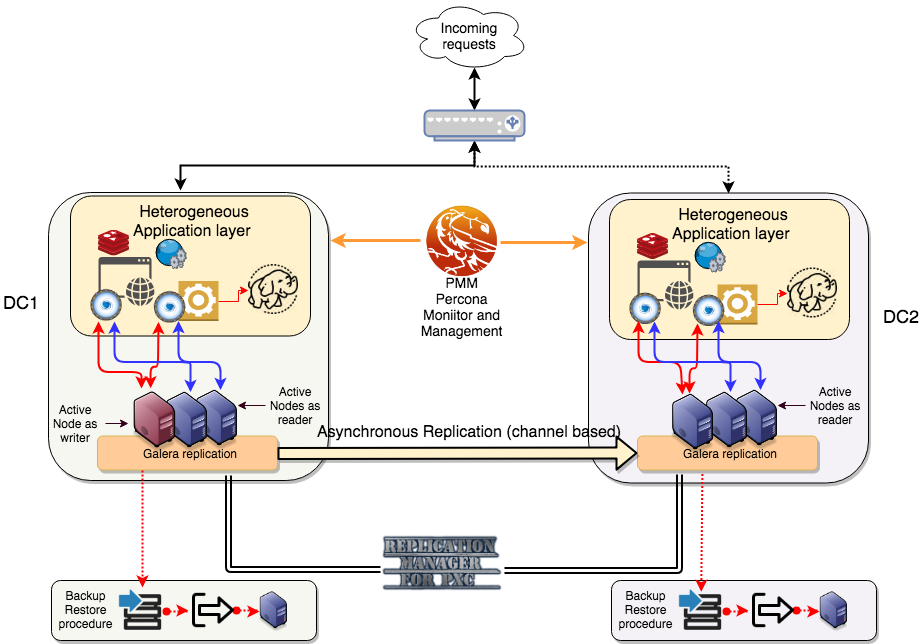
In the solution above, we have two locations separated by several kilometers. On top of them, the load balancer(s)/DNS resolution redirects the incoming traffic to the active site. Each site hosts a full application stack, and applications connect to local ProxySQL. ProxySQL has read/write enabled to optimize the platform utilization, and is configured to shift writes from one PXC node to another in case of node failure. Asynchronous replication connects the two locations and transmits data from master to slave. Note that with this solution, it is possible to have multiple geographically distributed sites. Backups are taken at each site independently and recovery test is performed. RMfP oversees and modifies the replication channels in the case of a node failure. Finally, Percona Monitoring and Management (PMM) is in place to perform in-depth monitoring of the whole database platform.
Conclusions
We always look for the most efficient, manageable, user-friendly combination of products, because we believe in providing and supporting the community with simple but efficient solutions. What we have presented here is the most robust and stable high availability solution in the MySQL space (except for MySQL NDB that we have excluded). It is conceptualized to provide maximum service continuity, with limited bonding between the platforms/sites. It also is a well-tested solution, that has been adopted and adapted in many different scenarios where performance and real HA are a must. I have preferred to keep this digression at a high level, given the details of the implementation have already been discussed elsewhere (see reference section for more reading). Still, Percona XtraDB Cluster (as any other solution implementing Galera replication) might not fit the final use. Given that, it is important to understand where it does and doesn’t fit. This article is a good summary with examples: Is Synchronous Replication right for your app?. Check out the next article on How Not to do MySQL High Availability.
References
https://www.percona.com/blog/2016/06/07/choosing-mysql-high-availability-solutions/
https://dev.mysql.com/doc/mysql-ha-scalability/en/ha-overview.html
https://www.percona.com/blog/2014/11/17/typical-misconceptions-on-galera-for-mysql/
http://galeracluster.com/documentation-webpages/limitations.html
http://tusacentral.net/joomla/index.php/mysql-blogs/183-proxysql-percona-cluster-galera-integration.html https://github.com/sysown/proxysql/wiki