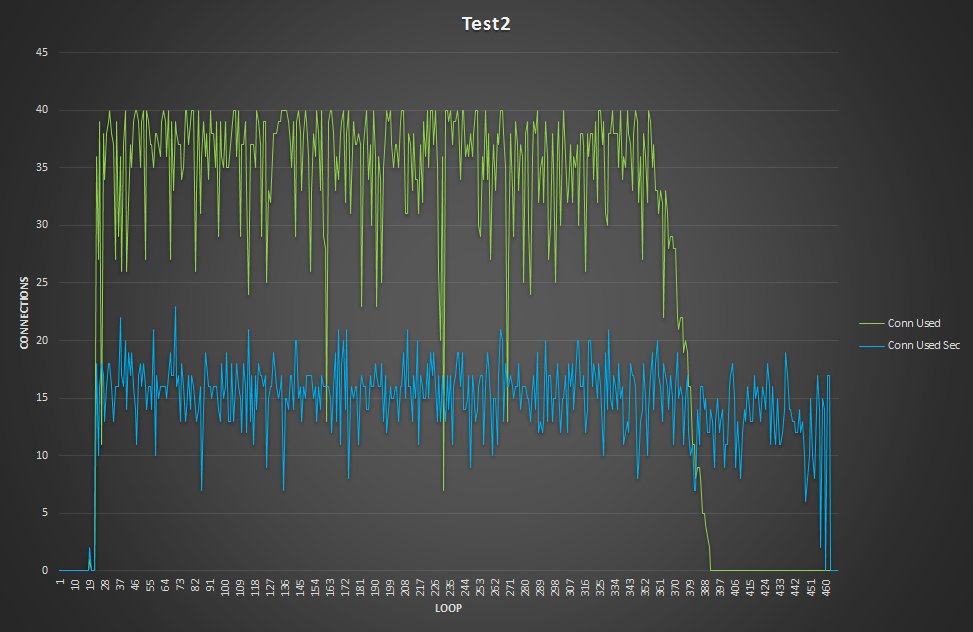
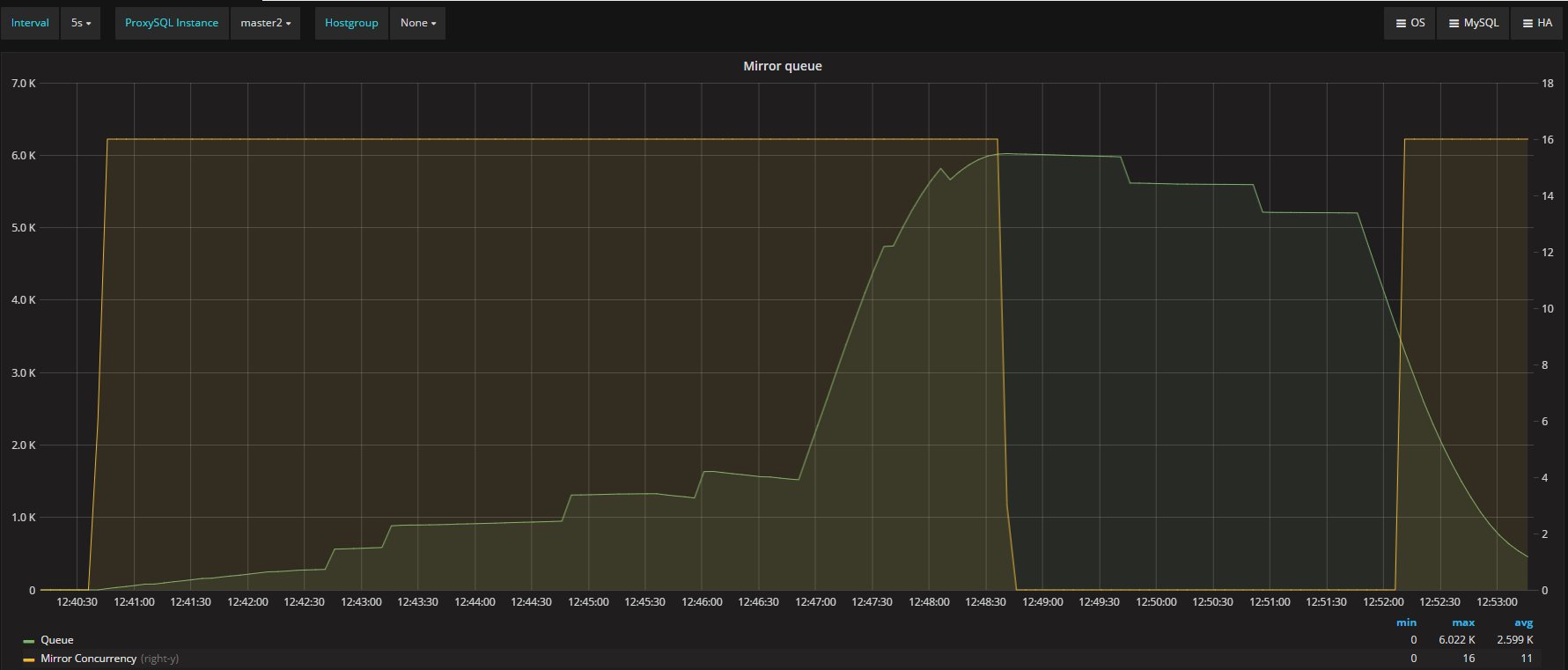
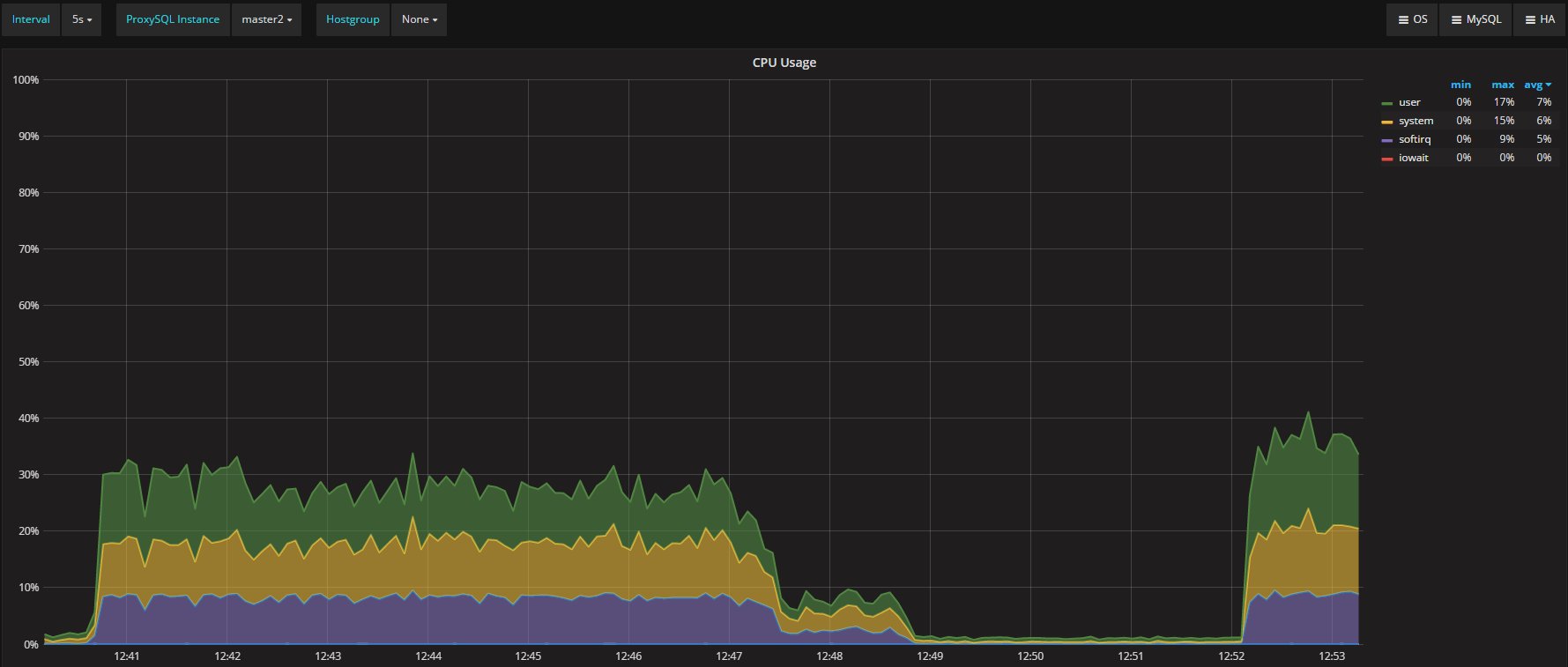
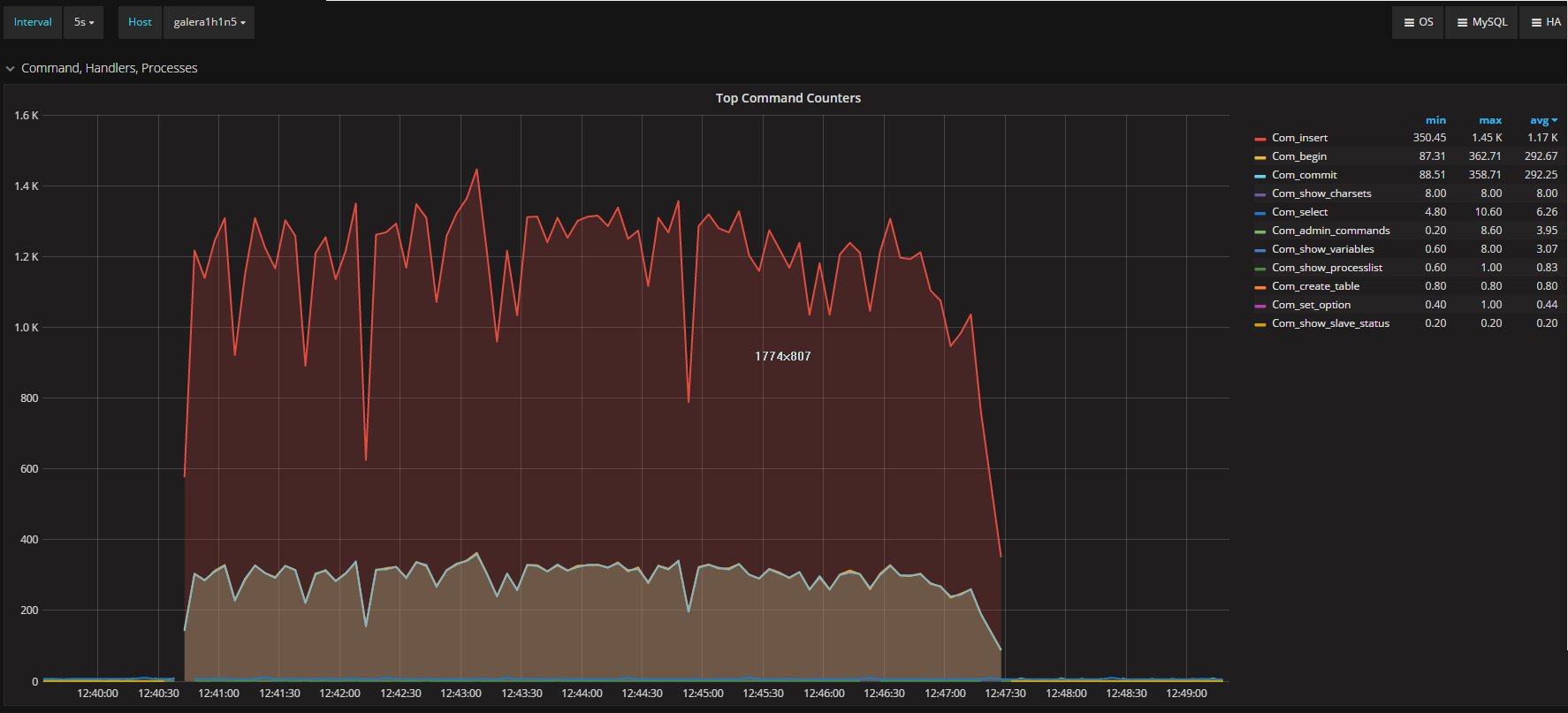
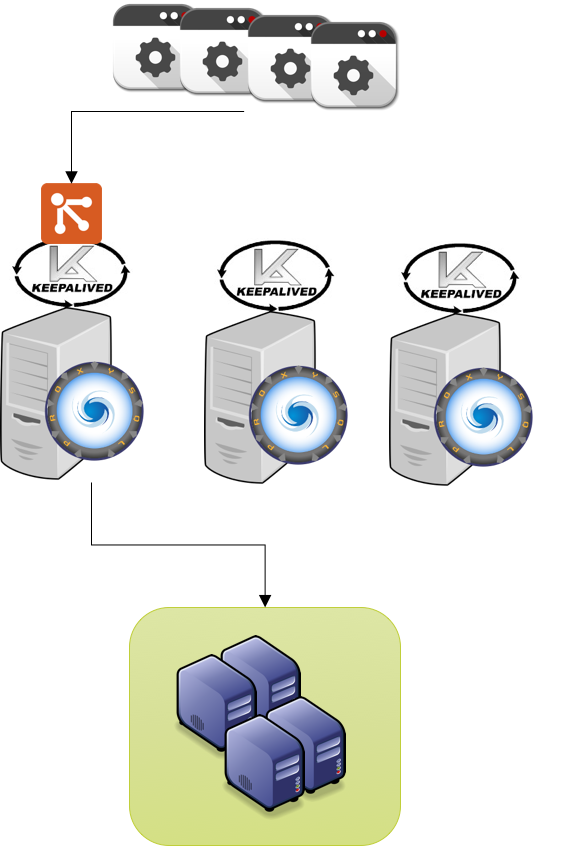
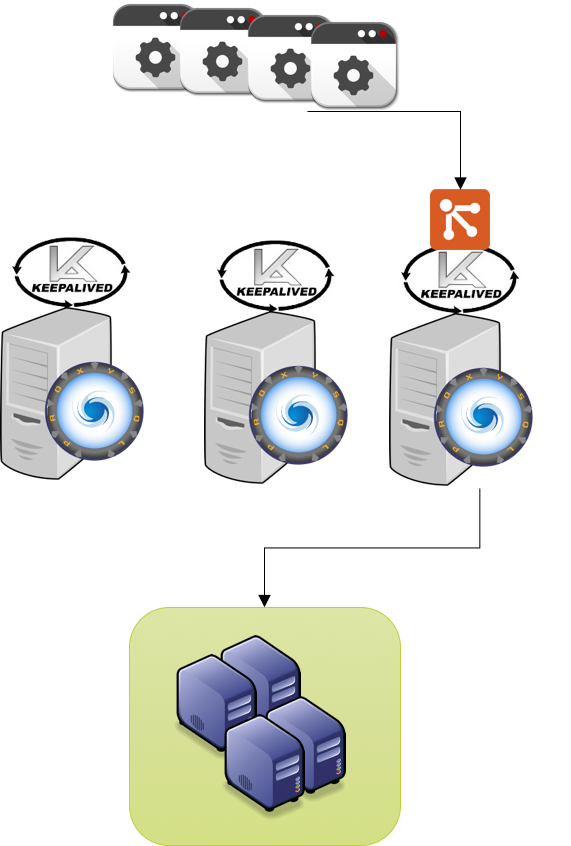
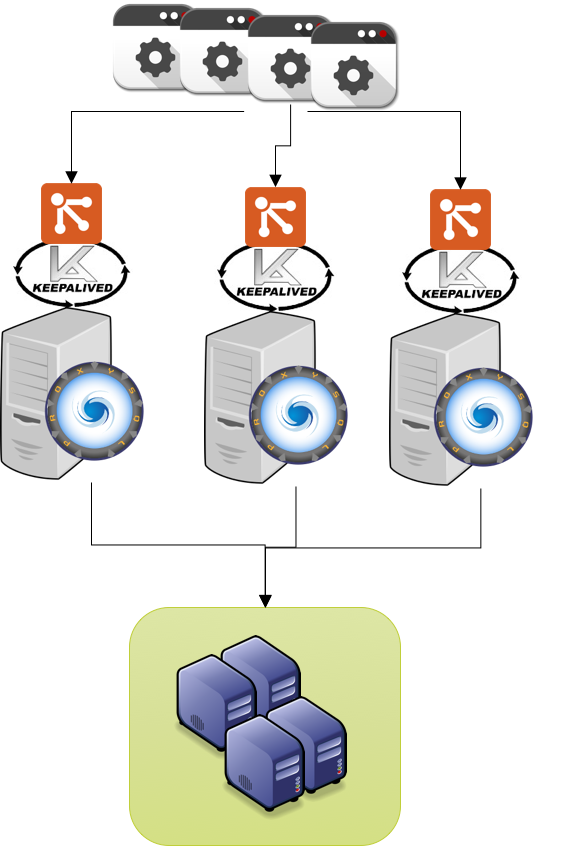
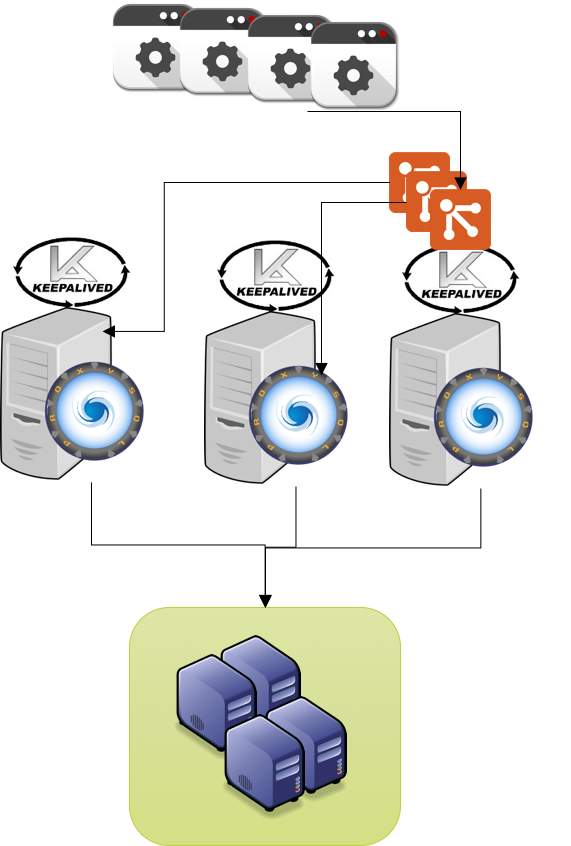
ProxySQL is design to do not perform any specialized operation in relation to the servers it communicate with.
Instead it has scheduled events that can be used to extend functionalities and cover any special need.
Given that specialized product like PXC, are not managed by ProxySQL and require the design and implementation of good/efficient extensions.
In this article I will illustrate how PXC/Galera can be integrated with ProxySQL to get the best from both.
Brief digression
Before discussing the PXC integration, we need to review a couple of very important concept in ProxySQL.ProxySQL has a very important logical component, the Hostgroup(s) (HG).
An hostgroup as a relation of :
+-----------+ +------------------------+
|Host group +------>|Server (1:N) |
+-----------+ +------------------------+
Not only, in ProxySQL you can use QueryRules (QR) that can be directly map to an HG.
Such that you can define a specific user to go ONLY to that HG, for instance you may want to have user app1_user go only on Servers A-B-C.
The only thing you need to do is to set a QR that say this user (app1_user) had destination hostgroup 5.
Where HG 5 has the servers A-B-C.
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.1.5',5,3306,10);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.1.6',5,3306,10);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.1.7',5,3306,10);
INSERT INTO mysql_query_rules (username,destination_hostgroup,active) VALUES('app1_user',5,1);
Easy isn't it?
Another important concept in ProxySQL also related to HG is ReplicationHostgroup(s) (RHG).
This is a special HG that ProxySQL use to automatically manage the nodes that are connected by replication and configured in Write/Read and Read_only mode.
What it means?
Let us say you have 4 nodes A-B-C-D, connected by standard asynchronous replication.
Where A is the master and B-C-D are the slaves.
What you want is to have you application pointing to server A for all writes, and to B-C the reads keeping off D because is a backup slave.
Also you don't want to have any read to go to B-C if the replication delay is more than 2 seconds.
Using RHG in conjunction with HG, ProxySQL will manage all these for you.
To achieve that we only have to instruct proxy to:use RHGdefine the value of the maximum latencyUsing the example above:
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_replication_lag) VALUES ('192.168.1.5',5,3306,10,2);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_replication_lag) VALUES ('192.168.1.6',5,3306,10,2);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_replication_lag) VALUES ('192.168.1.7',5,3306,10,2);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_replication_lag) VALUES ('192.168.1.8',10,3306,10,2);
INSERT INTO mysql_query_rules (username,destination_hostgroup,active) VALUES('app1_user',5,1);
INSERT INTO mysql_query_rules (username,destination_hostgroup,active) VALUES('app1_user',6,1);
INSERT INTO mysql_replication_hostgroups VALUES (5,6);
From now on ProxySQL will split the R/W using the RHG and the nodes defined in HG 5.
The flexibility that the use of the HG introduce, is obviously not limited to what I had mention here, and will play a good part in the integration between PXC and ProxySQL that I will illustrate below.
PXC/Galera integration
In a PXC cluster a node can have many different state and conditions that will affect if and if yes how, your application should operate on the node.
The most common one is when a node become a DONOR.
Whoever had install PXC or any Galera implementation, had face that when a node become a DONOR it will change it state to DESYNC, and/or if the node is heavy loaded, the DONOR process may affect the node itself.
But that is just one of the thing.
A node can be in state 3 JOINED but not sync, it can have wsrep_rejectqueries, wsrep_donorrejectqueries, wsrep_ready (off), it can be in a different segment and last but not least the number of nodes per segment is relevant.
To show what can be done, and how, we will use the following setup:
5 nodes
2 segment
Applications requiring R/W split
And finally two options:
single writer node
multiple writers node
What will analyze here is how Proxy will behave under the use of a script run by the ProxySQL scheduler.
The use of a script is necessary to have ProxySQL act correctly to PXC state modifications.
ProxySQL comes with two scripts for galera, both of them are too basic and not considering a lot of relevant conditions.
As example I have wrote a more complete script https://github.com/Tusamarco/proxy_sql_tools galera_check.pl
The script is designed to manage a X number of nodes that belong to a given Hostgroup (HG).
The script works by HG and as such it will perform isolated actions/checks by HG.
It is not possible to have more than one check running on the same HG.
The check will create a lock file {proxysql_galera_check_${hg}.pid} that will be used by the check to prevent duplicates.
Galera_check will connect to the ProxySQL node and retrieve all the information regarding the Nodes/proxysql configuration.
It will then check in parallel each node and will retrieve the status and configuration.At the moment galera_check analyze and manage the following:
Node states:
read_only
wsrep_status
wsrep_rejectqueries
wsrep_donorrejectqueries
wsrep_connected
wsrep_desinccount
wsrep_ready
wsrep_provider
wsrep_segment
Number of nodes in by segment
Retry loop
As mention the number of Nodes inside a segment is relevant, if a node is the only one in a segment, the check will behave accordingly.
IE if a node is the only one in the MAIN segment, it will not put the node in OFFLINE_SOFT when the node become donor to prevent the cluster to become unavailable for the applications.
In the script it is possible to declare a segment as MAIN, quite useful when managing prod and DR site, because the script will manage the segment acting as main in a more conservative way.
The check can be configured to perform retries after a given interval.
Where the interval is the time define in the ProxySQL scheduler.
As such if the check is set to have 2 retry for UP and 3 for down, it will loop that number before doing anything.PXC/Galera does some action behind the hood, some of them not totally correct.
This feature is useful in some not well known cases where Galera behave weird.
IE whenever a node is set to READ_ONLY=1, galera desync and resync the node.
A check not taking this into account will cause a node to be set OFFLINE and back for no reason.
Another important differentiation for this check is that it use special HGs for maintenance, all in range of 9000.
So if a node belong to HG 10 and the check needs to put it in maintenance mode, the node will be moved to HG 9010.
Once all is normal again, the Node will be put back on his original HG. This check does NOT modify any state of the Nodes.
Meaning It will NOT modify any variables or settings in the original node.
It will ONLY change node states in ProxySQL.
Multiwriter mode
The MOST and recommended way to use galera is to have it in multiwriter mode.
Then play with the weight to have a node act as MAIN node and prevent/reduce certification failures and Brutal force Abort from PXC.
The configuration to use is:
DELETE FROM mysql_replication_hostgroups WHERE writer_hostgroup=500 ;
DELETE FROM mysql_servers WHERE hostgroup_id IN (500,501);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.1.5',500,3306,1000000000);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.1.5',501,3306,100);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.1.6',500,3306,1000000);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.1.6',501,3306,1000000000);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.1.7',500,3306,100);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.1.7',501,3306,1000000000);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.1.8',500,3306,1);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.1.8',501,3306,1);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.1.9',500,3306,1);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.1.9',501,3306,1);
LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL TO DISK;
In this test we will NOT use Replication HostGroup.
We will do that later when testing single writer, for now ... focus on multi-writer.
Segment 1 cover HG 500 and 501 while segment 2 is only 501.
Weight for servers in HG 500 is progressive from 1 to 1 billion, this to reduce the possible random writes on the non main node.
As such Nodes:
HG 500
S1 192.168.1.5 - 1.000.000.000
S1 192.168.1.6 - 1.000.000
S1 192.168.1.7 - 100
S2 192.168.1.8 - 1
S2 192.168.1.9 - 1
HG 501
S1 192.168.1.5 - 100
S1 192.168.1.6 - 1000000000
S1 192.168.1.7 - 1000000000
S2 192.168.1.8 - 1
S2 192.168.1.9 - 1
The following command can be used to view what ProxySQL is doing:
watch -n 1 'mysql -h 127.0.0.1 -P 3310 -uadmin -padmin -t -e "select * from stats_mysql_connection_pool where hostgroup in (500,501,9500,9501) order by hostgroup,srv_host ;" -e " select hostgroup_id,hostname,status,weight,comment from mysql_servers where hostgroup_id in (500,501,9500,9501) order by hostgroup_id,hostname ;"'
Download the check from git (https://github.com/Tusamarco/proxy_sql_tools) and activate it in ProxySQL.
Be sure to set the parameter that match your installation:
DELETE FROM scheduler WHERE id=10;
INSERT INTO scheduler (id,active,interval_ms,filename,arg1) VALUES (10,0,2000,"/var/lib/proxysql/galera_check.pl","-u=admin -p=admin -h=192.168.1.50 -H=500:W,501:R -P=3310 --execution_time=1 --retry_down=2 --retry_up=1 --main_segment=1 --debug=0 --log=/var/lib/proxysql/galeraLog");
LOAD SCHEDULER TO RUNTIME;SAVE SCHEDULER TO DISK;
If you want activate it:
UPDATE scheduler SET active=1 WHERE id=10;
LOAD SCHEDULER TO RUNTIME;
The following is the kind of scenario we have:
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| 500 | 192.168.1.9 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 413 |
| 500 | 192.168.1.8 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 420 |
| 500 | 192.168.1.7 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 227 |
| 500 | 192.168.1.6 | 3306 | ONLINE | 0 | 10 | 10 | 0 | 12654 | 1016975 | 0 | 230 |
| 500 | 192.168.1.5 | 3306 | ONLINE | 0 | 9 | 29 | 0 | 107358 | 8629123 | 0 | 206 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 0 | 4 | 6 | 0 | 12602425 | 613371057 | 34467286486 | 413 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 0 | 6 | 7 | 0 | 12582617 | 612422028 | 34409606321 | 420 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 0 | 6 | 6 | 0 | 18580675 | 905464967 | 50824195445 | 227 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 0 | 6 | 14 | 0 | 18571127 | 905075154 | 50814832276 | 230 |
| 501 | 192.168.1.5 | 3306 | ONLINE | 0 | 1 | 10 | 0 | 169570 | 8255821 | 462706881 | 206 |
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
To generate load we will use the following commands (or whatever you like but do 2 different for read only and reads/writes)
Write
sysbench --test=/usr/share/doc/sysbench/tests/db/oltp.lua --mysql-host=192.168.1.50 --mysql-port=3311 --mysql-user=stress_RW --mysql-password=test --mysql-db=test_galera --db-driver=mysql --oltp-tables-count=50 --oltp-tablesize=50000 --max-requests=0 --max-time=9000 --oltp-point-selects=5 --oltp-read-only=off --oltp-dist-type=uniform --oltp-reconnect-mode=transaction --oltp-skip-trx=off --num-threads=10 --report-interval=10 --mysql-ignore-errors=all run
Read only
sysbench --test=/usr/share/doc/sysbench/tests/db/oltp.lua --mysql-host=192.168.1.50 --mysql-port=3311 --mysql-user=stress_RW --mysql-password=test --mysql-db=test_galera --db-driver=mysql --oltp-tables-count=50 --oltp-tablesize=50000 --max-requests=0 --max-time=9000 --oltp-point-selects=5 --oltp-read-only=on --num-threads=10 --oltp-reconnect-mode=query --oltp-skip-trx=on --report-interval=10 --mysql-ignore-errors=all run
Now the most common thing that could happen to a cluster node is to become a donor, this is a planned activity for a PXC, and it is suppose to be manage in the less harmful way.
To simulate that we will choose a node and crash it, forcing the crash node to elect as DONOR our main node (the one with highest WEIGHT).
To do so we need to have the parameter wsrep_sst_donor set in the node that will request the SST data transfer.
SHOW global VARIABLES LIKE 'wsrep_sst_donor';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| wsrep_sst_donor | node1 | <---
+-----------------+-------+
Activate the check if not already done:
UPDATE scheduler SET active=1 WHERE id=10;
And now run traffic.
Then check load:
SELECT * FROM stats_mysql_connection_pool WHERE hostgroup IN (500,501,9500,9501) ORDER BY hostgroup,srv_host ;
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| 500 | 192.168.1.5 | 3306 | ONLINE | 10 | 0 | 30 | 0 | 112662 | 9055479 | 0 | 120 | <--- our Donor
| 500 | 192.168.1.6 | 3306 | ONLINE | 0 | 10 | 10 | 0 | 12654 | 1016975 | 0 | 111 |
| 500 | 192.168.1.7 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 115 |
| 500 | 192.168.1.8 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 316 |
| 500 | 192.168.1.9 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 329 |
| 501 | 192.168.1.5 | 3306 | ONLINE | 0 | 1 | 10 | 0 | 257271 | 12533763 | 714473854 | 120 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 0 | 10 | 18 | 0 | 18881582 | 920200116 | 51688974309 | 111 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 3 | 6 | 9 | 0 | 18927077 | 922317772 | 51794504662 | 115 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 0 | 1 | 8 | 0 | 12595556 | 613054573 | 34447564440 | 316 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 1 | 3 | 6 | 0 | 12634435 | 614936148 | 34560620180 | 329 |
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
On one of the node:
kill mysql
remove the content of the data directory
restart the node
The node will go in SST and our galera_check script will manage it:
+--------------+-------------+--------------+------------+--------------------------------------------------+
| hostgroup_id | hostname | STATUS | weight | comment |
+--------------+-------------+--------------+------------+--------------------------------------------------+
| 500 | 192.168.1.5 | OFFLINE_SOFT | 1000000000 | 500_W_501_R_retry_up=0;500_W_501_R_retry_down=0; | <---- the donor
| 500 | 192.168.1.6 | ONLINE | 1000000 | |
| 500 | 192.168.1.7 | ONLINE | 100 | |
| 500 | 192.168.1.8 | ONLINE | 1 | |
| 500 | 192.168.1.9 | ONLINE | 1 | |
| 501 | 192.168.1.5 | OFFLINE_SOFT | 100 | 500_W_501_R_retry_up=0;500_W_501_R_retry_down=0; |
| 501 | 192.168.1.6 | ONLINE | 1000000000 | |
| 501 | 192.168.1.7 | ONLINE | 1000000000 | |
| 501 | 192.168.1.8 | ONLINE | 1 | |
| 501 | 192.168.1.9 | ONLINE | 1 | |
+--------------+-------------+--------------+------------+--------------------------------------------------+
We can also check the galera_check log and see what happened:
2016/09/02 16:13:27.298:[WARN] Move node:192.168.1.5;3306;500;3010 SQL: UPDATE mysql_servers SET status='OFFLINE_SOFT' WHERE hostgroup_id=500 AND hostname='192.168.1.5' AND port='3306'
2016/09/02 16:13:27.303:[WARN] Move node:192.168.1.5;3306;501;3010 SQL: UPDATE mysql_servers SET status='OFFLINE_SOFT' WHERE hostgroup_id=501 AND hostname='192.168.1.5' AND port='3306'
The node will remain in OFFLINE_SOFT while the other node (192.168.1.6 having the 2nd WEIGHT) serves the writes, untill the node is in DONOR state.
All as expected, the node was set in OFFLINE_SOFT state, which mean the existing connections where able to finish, whole the node was not accepting any NEW connection.
As soon the node ends to send data to the Joiner, it was moved back and traffic restart:
2016/09/02 16:14:58.239:[WARN] Move node:192.168.1.5;3306;500;1000 SQL: UPDATE mysql_servers SET STATUS='ONLINE' WHERE hostgroup_id=500 AND hostname='192.168.1.5' AND port='3306'
2016/09/02 16:14:58.243:[WARN] Move node:192.168.1.5;3306;501;1000 SQL: UPDATE mysql_servers SET STATUS='ONLINE' WHERE hostgroup_id=501 AND hostname='192.168.1.5' AND port='3306'
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| 500 | 192.168.1.5 | 3306 | ONLINE | 6 | 1 | 37 | 0 | 153882 | 12368557 | 0 | 72 | <---
| 500 | 192.168.1.6 | 3306 | ONLINE | 1 | 9 | 10 | 0 | 16008 | 1286492 | 0 | 42 |
| 500 | 192.168.1.7 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 1398 | 112371 | 0 | 96 |
| 500 | 192.168.1.8 | 3306 | ONLINE | 0 | 0 | 24545 | 791 | 24545 | 122725 | 0 | 359 |
| 500 | 192.168.1.9 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 15108 | 1214366 | 0 | 271 |
| 501 | 192.168.1.5 | 3306 | ONLINE | 1 | 0 | 11 | 0 | 2626808 | 128001112 | 7561278884 | 72 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 5 | 7 | 20 | 0 | 28629516 | 1394974468 | 79289633420 | 42 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 2 | 8 | 10 | 0 | 29585925 | 1441400648 | 81976494740 | 96 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 0 | 0 | 16779 | 954 | 12672983 | 616826002 | 34622768228 | 359 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 0 | 4 | 6 | 0 | 13567512 | 660472589 | 37267991677 | 271 |
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
This was easy, and more or less managed also by the standard script.
But what would happened if my donor was set to DO NOT serve query when in donor state?
Wait what?? Yes PXC (Galera in general) can be set to refuse any query when the Node goes in DONOR state.
If not managed this will cause issue because the Node will simply reject queries but ProxySQL see he node alive.
Let me show you:
SHOW global VARIABLES LIKE 'wsrep_sst_donor_rejects_queries';
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| wsrep_sst_donor_rejects_queries | ON |
+---------------------------------+-------+
For a moment let us deactivate the check.
Then, do the same stop and delete of the data dir, then restart the node... SST take place.
And sysbench will report:
ALERT: mysql_drv_query() returned error 2013 (Lost connection to MySQL server during query) for query 'BEGIN'
FATAL: failed to execute function `event': 3
ALERT: mysql_drv_query() returned error 2013 (Lost connection to MySQL server during query) for query 'BEGIN'
FATAL: failed to execute function `event': 3
But and ProxySQL?
+-----------+-------------+----------+---------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+---------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| 500 | 192.168.1.5 | 3306 | ONLINE | 0 | 0 | 101 | 0 | 186331 | 14972717 | 0 | 118 | <-- no writes in wither HG
| 500 | 192.168.1.6 | 3306 | ONLINE | 0 | 9 | 10 | 0 | 20514 | 1648665 | 0 | 171 | |
| 500 | 192.168.1.7 | 3306 | ONLINE | 0 | 1 | 3 | 0 | 5881 | 472629 | 0 | 134 | |
| 500 | 192.168.1.8 | 3306 | ONLINE | 0 | 0 | 205451 | 1264 | 205451 | 1027255 | 0 | 341 | |
| 500 | 192.168.1.9 | 3306 | ONLINE | 0 | 1 | 2 | 0 | 15642 | 1257277 | 0 | 459 | -
| 501 | 192.168.1.5 | 3306 | ONLINE | 1 | 0 | 13949 | 0 | 4903347 | 238627310 | 14089708430 | 118 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 2 | 10 | 20 | 0 | 37012174 | 1803380964 | 103269634626 | 171 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 2 | 11 | 13 | 0 | 38782923 | 1889507208 | 108288676435 | 134 |
| 501 | 192.168.1.8 | 3306 | SHUNNED | 0 | 0 | 208452 | 1506 | 12864656 | 626156995 | 34622768228 | 341 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 1 | 3 | 6 | 0 | 14451462 | 703534884 | 39837663734 | 459 |
+-----------+-------------+----------+---------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
mysql> SELECT * FROM mysql_server_connect_log WHERE hostname IN ('192.168.1.5','192.168.1.6','192.168.1.7','192.168.1.8','192.168.1.9') ORDER BY time_start_us DESC LIMIT 10;
+-------------+------+------------------+-------------------------+--------------------------------------------------------------------------------------------------------+
| hostname | port | time_start_us | connect_success_time_us | connect_error |
+-------------+------+------------------+-------------------------+--------------------------------------------------------------------------------------------------------+
| 192.168.1.9 | 3306 | 1472827444621954 | 1359 | NULL |
| 192.168.1.8 | 3306 | 1472827444618883 | 0 | Can't connect to MySQL server on '192.168.1.8' (107) |
| 192.168.1.7 | 3306 | 1472827444615819 | 433 | NULL |
| 192.168.1.6 | 3306 | 1472827444612722 | 538 | NULL |
| 192.168.1.5 | 3306 | 1472827444606560 | 473 | NULL | <-- donor is seen as up
| 192.168.1.9 | 3306 | 1472827384621463 | 1286 | NULL |
| 192.168.1.8 | 3306 | 1472827384618442 | 0 | Lost connection to MySQL server at 'handshake: reading inital communication packet', system error: 107 |
| 192.168.1.7 | 3306 | 1472827384615317 | 419 | NULL |
| 192.168.1.6 | 3306 | 1472827384612241 | 415 | NULL |
| 192.168.1.5 | 3306 | 1472827384606117 | 454 | NULL | <-- donor is seen as up
+-------------+------+------------------+-------------------------+--------------------------------------------------------------------------------------------------------+
select * from mysql_server_ping_log where hostname in ('192.168.1.5','192.168.1.6','192.168.1.7','192.168.1.8','192.168.1.9') order by time_start_us desc limit 10;
+-------------+------+------------------+----------------------+------------------------------------------------------+
| hostname | port | time_start_us | ping_success_time_us | ping_error |
+-------------+------+------------------+----------------------+------------------------------------------------------+
| 192.168.1.9 | 3306 | 1472827475062217 | 311 | NULL |
| 192.168.1.8 | 3306 | 1472827475060617 | 0 | Can't connect TO MySQL server ON '192.168.1.8' (107) |
| 192.168.1.7 | 3306 | 1472827475059073 | 108 | NULL |
| 192.168.1.6 | 3306 | 1472827475057281 | 102 | NULL |
| 192.168.1.5 | 3306 | 1472827475054188 | 74 | NULL | <-- donor is seen as up
| 192.168.1.9 | 3306 | 1472827445061877 | 491 | NULL |
| 192.168.1.8 | 3306 | 1472827445060254 | 0 | Can't connect to MySQL server on '192.168.1.8' (107) |
| 192.168.1.7 | 3306 | 1472827445058688 | 53 | NULL |
| 192.168.1.6 | 3306 | 1472827445057124 | 131 | NULL |
| 192.168.1.5 | 3306 | 1472827445054015 | 98 | NULL | <-- donor is seen as up
+-------------+------+------------------+----------------------+------------------------------------------------------+
As you can see all seems ok also if it is not :)
Let us turn on the galera_check and see what happens.
Run some load in read and write.
And now let me do the stop-delete-restart-SST process again
kill -9 <mysqld_safe_pid> <mysqld_pid>; rm -fr data/*;rm -fr logs/*;sleep 2;./start
A soon the node goes down ProxySQL Shun the node.
+-----------+-------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| 500 | 192.168.1.5 | 3306 | ONLINE | 7 | 3 | 34 | 0 | 21570 | 1733833 | 0 | 146 |
| 500 | 192.168.1.6 | 3306 | ONLINE | 1 | 8 | 12 | 0 | 9294 | 747063 | 0 | 129 |
| 500 | 192.168.1.7 | 3306 | ONLINE | 1 | 0 | 4 | 0 | 3396 | 272950 | 0 | 89 |
| 500 | 192.168.1.8 | 3306 | SHUNNED | 0 | 0 | 1 | 6 | 12 | 966 | 0 | 326 | <-- crashed
| 500 | 192.168.1.9 | 3306 | ONLINE | 1 | 0 | 2 | 0 | 246 | 19767 | 0 | 286 |
| 501 | 192.168.1.5 | 3306 | ONLINE | 0 | 1 | 2 | 0 | 772203 | 37617973 | 2315131214 | 146 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 9 | 3 | 12 | 0 | 3439458 | 167514166 | 10138636314 | 129 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 1 | 12 | 13 | 0 | 3183822 | 155064971 | 9394612877 | 89 |
| 501 | 192.168.1.8 | 3306 | SHUNNED | 0 | 0 | 1 | 6 | 11429 | 560352 | 35350726 | 326 | <-- crashed
| 501 | 192.168.1.9 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 312253 | 15227786 | 941110520 | 286 |
+-----------+-------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
Immediately after the glera_check identify the node is requesting the SST and that the DONOR is our writer, given is NOT the only writer in the HG, and given it has the variable wsrep_sst_donor_rejects_queries active, it cannot be set OFFLINE_SOFT, and we do not want to have ProxySQL consider it OFFLINE_HARD (because it is not).
As such the script will move it to a special HG:
2016/09/04 16:11:22.091:[WARN] Move node:192.168.1.5;3306;500;3001 SQL: UPDATE mysql_servers SET hostgroup_id=9500 WHERE hostgroup_id=500 AND hostname='192.168.1.5' AND port='3306'
2016/09/04 16:11:22.097:[WARN] Move node:192.168.1.5;3306;501;3001 SQL: UPDATE mysql_servers SET hostgroup_id=9501 WHERE hostgroup_id=501 AND hostname='192.168.1.5' AND port='3306'
+--------------+-------------+------+--------+------------+-------------+-----------------+---------------------+---------+----------------+--------------------------------------------------+
| hostgroup_id | hostname | port | STATUS | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment |
+--------------+-------------+------+--------+------------+-------------+-----------------+---------------------+---------+----------------+--------------------------------------------------+
| 500 | 192.168.1.6 | 3306 | ONLINE | 1000000 | 0 | 1000 | 0 | 0 | 0 | |
| 500 | 192.168.1.7 | 3306 | ONLINE | 100 | 0 | 1000 | 0 | 0 | 0 | |
| 500 | 192.168.1.8 | 3306 | ONLINE | 1 | 0 | 1000 | 0 | 0 | 0 | 500_W_501_R_retry_up=0;500_W_501_R_retry_down=0; |
| 500 | 192.168.1.9 | 3306 | ONLINE | 1 | 0 | 1000 | 0 | 0 | 0 | 500_W_501_R_retry_up=0;500_W_501_R_retry_down=0; |
| 501 | 192.168.1.6 | 3306 | ONLINE | 1000000000 | 0 | 1000 | 0 | 0 | 0 | |
| 501 | 192.168.1.7 | 3306 | ONLINE | 1000000000 | 0 | 1000 | 0 | 0 | 0 | |
| 501 | 192.168.1.9 | 3306 | ONLINE | 1 | 0 | 1000 | 0 | 0 | 0 | 500_W_501_R_retry_up=0;500_W_501_R_retry_down=0; |
| 9500 | 192.168.1.5 | 3306 | ONLINE | 1000000000 | 0 | 1000 | 0 | 0 | 0 | 500_W_501_R_retry_up=0;500_W_501_R_retry_down=0; | <-- Special HG
| 9501 | 192.168.1.5 | 3306 | ONLINE | 100 | 0 | 1000 | 0 | 0 | 0 | 500_W_501_R_retry_up=0;500_W_501_R_retry_down=0; | <-- Special HG
+--------------+-------------+------+--------+------------+-------------+-----------------+---------------------+---------+----------------+--------------------------------------------------+
In this way the Donor will continue to serve the Joiner, but applications will not see it.
What is also very important is what the applications will see.
The Applications doing WRITEs will see:
[ 10s] threads: 10, tps: 9.50, reads: 94.50, writes: 42.00, response time: 1175.77ms (95%), errors: 0.00, reconnects: 0.00
...
[ 40s] threads: 10, tps: 2.80, reads: 26.10, writes: 11.60, response time: 3491.45ms (95%), errors: 0.00, reconnects: 0.10
[ 50s] threads: 10, tps: 4.80, reads: 50.40, writes: 22.40, response time: 10062.13ms (95%), errors: 0.80, reconnects: 351.60 <--- Main writer moved to another HG
[ 60s] threads: 10, tps: 5.90, reads: 53.10, writes: 23.60, response time: 2869.82ms (95%), errors: 0.00, reconnects: 0.00
...
At the moment of the shift from one node to another the applications will have to manage the RE-TRY, but it will be a very short moment that will cause limited impact on the production flow.
Application readers will see no errors:
[ 10s] threads: 10, tps: 0.00, reads: 13007.31, writes: 0.00, response time: 9.13ms (95%), errors: 0.00, reconnects: 0.00
[ 50s] threads: 10, tps: 0.00, reads: 9613.70, writes: 0.00, response time: 10.66ms (95%), errors: 0.00, reconnects: 0.20 <-- just a glitch in reconnect
[ 60s] threads: 10, tps: 0.00, reads: 10807.90, writes: 0.00, response time: 11.07ms (95%), errors: 0.00, reconnects: 0.20
[ 70s] threads: 10, tps: 0.00, reads: 9082.61, writes: 0.00, response time: 23.62ms (95%), errors: 0.00, reconnects: 0.00
...
[ 390s] threads: 10, tps: 0.00, reads: 13050.80, writes: 0.00, response time: 8.97ms (95%), errors: 0.00, reconnects: 0.00
When the Donor had end to provide SST it comes back and the script manage it, Glara_check will put it in the right HG:
2016/09/04 16:12:34.266:[WARN] Move node:192.168.1.5;3306;9500;1010 SQL: UPDATE mysql_servers SET hostgroup_id=500 WHERE hostgroup_id=9500 AND hostname='192.168.1.5' AND port='3306'
2016/09/04 16:12:34.270:[WARN] Move node:192.168.1.5;3306;9501;1010 SQL: UPDATE mysql_servers SET hostgroup_id=501 WHERE hostgroup_id=9501 AND hostname='192.168.1.5' AND port='3306'
The crashed node, will be re-start by the SST process, as such the node will be up.
But if the level of load in the cluster is mid/high it will remain in JOINED state for sometime, becoming visible by the ProxySQL again, while ProxySQL will not correctly recognize the state.
2016-09-04 16:17:15 21035 [Note] WSREP: 3.2 (node4): State transfer from 1.1 (node1) complete.2016-09-04 16:17:15 21035 [Note] WSREP: Shifting JOINER -> JOINED (TO: 254515)
To avoid issue the script will move it to special HG, allowing it to recovery without interfering with real load.
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| 500 | 192.168.1.5 | 3306 | ONLINE | 6 | 2 | 15 | 0 | 3000 | 241060 | 0 | 141 |
| 500 | 192.168.1.6 | 3306 | ONLINE | 1 | 9 | 13 | 0 | 13128 | 1055268 | 0 | 84 |
| 500 | 192.168.1.7 | 3306 | ONLINE | 1 | 0 | 4 | 0 | 3756 | 301874 | 0 | 106 |
| 500 | 192.168.1.9 | 3306 | ONLINE | 1 | 0 | 2 | 0 | 4080 | 327872 | 0 | 278 |
| 501 | 192.168.1.5 | 3306 | ONLINE | 1 | 0 | 2 | 0 | 256753 | 12508935 | 772048259 | 141 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 4 | 8 | 12 | 0 | 5116844 | 249191524 | 15100617833 | 84 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 2 | 11 | 13 | 0 | 4739756 | 230863200 | 13997231724 | 106 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 496524 | 24214563 | 1496482104 | 278 |
| 9500 | 192.168.1.8 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 331 |<-- Joined not Sync
| 9501 | 192.168.1.8 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 331 |<-- Joined not Sync
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
Once Node fully recover, galera_check put it back IN the original HG, ready serve requests:
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| 500 | 192.168.1.5 | 3306 | ONLINE | 0 | 1 | 15 | 0 | 3444 | 276758 | 0 | 130 |
| 500 | 192.168.1.6 | 3306 | ONLINE | 0 | 9 | 13 | 0 | 13200 | 1061056 | 0 | 158 |
| 500 | 192.168.1.7 | 3306 | ONLINE | 0 | 0 | 4 | 0 | 3828 | 307662 | 0 | 139 |
| 500 | 192.168.1.8 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |<-- up again
| 500 | 192.168.1.9 | 3306 | ONLINE | 0 | 0 | 2 | 0 | 4086 | 328355 | 0 | 336 |
| 501 | 192.168.1.5 | 3306 | ONLINE | 0 | 1 | 2 | 0 | 286349 | 13951366 | 861638962 | 130 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 0 | 12 | 12 | 0 | 5239212 | 255148806 | 15460951262 | 158 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 0 | 13 | 13 | 0 | 4849970 | 236234446 | 14323937975 | 139 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |<-- up again
| 501 | 192.168.1.9 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 507910 | 24768898 | 1530841172 | 336 |
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
Summarizing the logical steps are:
+---------+
| Crash |
+----+----+
|
v
+--------+-------+
| ProxySQL |
| shun crashed |
| node |
+--------+-------+
|
|
v
+-----------------+-----------------+
| Donor has one of the following? |
| wsrep_sst_dono _rejects_queries |
| OR |
| wsrep_reject_queries |
+-----------------------------------+
|No |Yes
v v
+-----+----------+ +-----------+----+
| Galera_check | | Galera_check |
| put the donor | | put the donor |
| in OFFLINE_SOFT| | in special HG |
+---+------------+ +-----------+----+
| |
| |
v v
+---+--------------------------------+-----+
| Donor SST ends |
+---+---------------+----------------+-----+
| | |
| | |
+---+------------+ | +-----------+----+
| Galera_check | | | Galera_check |
| put the donor | | | put the donor |
| ONLINE | | | in Original HG |
+----------------+ | +----------------+
|
|
+------------------------------------------+
| crashed SST ends |
+-------------------+----------------------+
|
|
+------------+-------------+
| Crashed node back but +<------------+
| Not Sync? | |
+--------------------------+ |
|No |Yes |
| | |
| | |
+---------+------+ +------+---------+ |
| Galera_check | | Galera_check | |
| put the node | | put the node +-----+
| back orig. HG | | Special HG |
+--------+-------+ +----------------+
|
|
|
| +---------+
+------> END |
+---------+
As mention in this integration with galera_check we can manage several node states.
Another case is when we need to have the node not accepting ANY query.
We may need that for several reasons, including preparing the node for maintenance or whatever.
In PXC and other Galera implementation we can set the value of wsrep_reject_queries to:
Valid Values
NONE
ALL
ALL_KILL
Let see how it works:
run some load then on the main writer node (192.168.1.5)
SET global wsrep_reject_queries=ALL;
This will block any new queries to be executed while the running will be completed.
Do a simple select on the node :
(root@localhost:pm) [test]>select * FROM tbtest1;
ERROR 1047 (08S01): WSREP has NOT yet prepared node FOR application USE
Point is , as you should have understand by now, that ProxySQL do not see these conditions:
+-------------+------+------------------+----------------------+------------+
| hostname | port | time_start_us | ping_success_time_us | ping_error |
+-------------+------+------------------+----------------------+------------+
| 192.168.1.5 | 3306 | 1473005467628001 | 35 | NULL | <--- ping ok
| 192.168.1.5 | 3306 | 1473005437628014 | 154 | NULL |
+-------------+------+------------------+----------------------+------------+
+-------------+------+------------------+-------------------------+---------------+
| hostname | port | time_start_us | connect_success_time_us | connect_error |
+-------------+------+------------------+-------------------------+---------------+
| 192.168.1.5 | 3306 | 1473005467369575 | 246 | NULL | <--- connect ok
| 192.168.1.5 | 3306 | 1473005407369441 | 353 | NULL |
+-------------+------+------------------+-------------------------+---------------+
The script Galera check will instead manage it:
+-----------+-------------+----------+--------------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| 500 | 192.168.1.5 | 3306 | OFFLINE_SOFT | 0 | 0 | 8343 | 0 | 10821 | 240870 | 0 | 93 | <--- galera check put it OFFLINE
| 500 | 192.168.1.6 | 3306 | ONLINE | 10 | 0 | 15 | 0 | 48012 | 3859402 | 0 | 38 | <--- writer
| 500 | 192.168.1.7 | 3306 | ONLINE | 0 | 1 | 6 | 0 | 14712 | 1182364 | 0 | 54 |
| 500 | 192.168.1.8 | 3306 | ONLINE | 0 | 1 | 2 | 0 | 1092 | 87758 | 0 | 602 |
| 500 | 192.168.1.9 | 3306 | ONLINE | 0 | 1 | 4 | 0 | 5352 | 430152 | 0 | 238 |
| 501 | 192.168.1.5 | 3306 | OFFLINE_SOFT | 0 | 0 | 1410 | 0 | 197909 | 9638665 | 597013919 | 93 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 2 | 10 | 12 | 0 | 7822682 | 380980455 | 23208091727 | 38 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 0 | 13 | 13 | 0 | 7267507 | 353962618 | 21577881545 | 54 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 241641 | 11779770 | 738145270 | 602 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 756415 | 36880233 | 2290165636 | 238 |
+-----------+-------------+----------+--------------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
In this case the script will put the node in OFFLINE_SOFT, given the "set global wsrep_reject_queries=ALL" means do not accept NEW complete the existing, as OFFLINE_SOFT.
The script manage also in the case of "set global wsrep_reject_queries=ALL_KILL;" .
Which from ProxySQL point of view do not exists as well:
+-------------+------+------------------+----------------------+------------+
| hostname | port | time_start_us | ping_success_time_us | ping_error |
+-------------+------+------------------+----------------------+------------+
| 192.168.1.5 | 3306 | 1473005827629069 | 59 | NULL |<--- ping ok
| 192.168.1.5 | 3306 | 1473005797628988 | 57 | NULL |
+-------------+------+------------------+----------------------+------------+
+-------------+------+------------------+-------------------------+---------------+
| hostname | port | time_start_us | connect_success_time_us | connect_error |
+-------------+------+------------------+-------------------------+---------------+
| 192.168.1.5 | 3306 | 1473005827370084 | 370 | NULL | <--- connect ok
| 192.168.1.5 | 3306 | 1473005767369915 | 243 | NULL |
+-------------+------+------------------+-------------------------+---------------+
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| 9500 | 192.168.1.5 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |<--- galera check put it in special HG
| 9501 | 192.168.1.5 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
The difference here is that the script moves the node to the special HG to isolate it, instead let it be in the original HG.
As you can see the integration between ProxySQL and PXC(galera) in the case of multi-writer, works perfectly, if you have a script as galera_check that manage correctly the different PXC/Galera states.
ProxySQL and PXC using Replication HostGroup
Sometimes we may need to have the 100% of the write going to one node only a time.
As explain above ProxySQL use weight to redirect a % of the load to a specific node.
In most of the case it will be enough to set the weight in the main writer to a very high value, like 10 billions and on the next node to 1 thousands, to achieve an almost single writer.
But this is not 100%, it still allow ProxySQL to send a query once every X to the other node(s).
The solution to this and to keep it consistent with the ProxySQL logic, is to use replication Hostgroups.
Replication HG are special HG that Proxy see as connected for R/W operations.
ProxySQL analyze the value of the READ_ONLY variables and assign to the READ_ONLY HG the nodes that have it enable.
While the node having READ_ONLY=0, reside in both HG.
As such the first thing we need to modify is to say to ProxySQL that our two HG 500 and 501 are replication HG.
INSERT INTO mysql_replication_hostgroups VALUES (500,501,'');
LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK;
SELECT * FROM mysql_replication_hostgroups ;
+------------------+------------------+---------+
| writer_hostgroup | reader_hostgroup | comment |
+------------------+------------------+---------+
| 500 | 501 | |
+------------------+------------------+---------+
Now whenever I will set the value of READ_ONLY on a node ProxySQL will move the node accordingly.
Let see how.
Current:
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| 500 | 192.168.1.5 | 3306 | ONLINE | 6 | 1 | 7 | 0 | 16386 | 1317177 | 0 | 97 |
| 500 | 192.168.1.6 | 3306 | ONLINE | 1 | 9 | 15 | 0 | 73764 | 5929366 | 0 | 181 |
| 500 | 192.168.1.7 | 3306 | ONLINE | 1 | 0 | 6 | 0 | 18012 | 1447598 | 0 | 64 |
| 500 | 192.168.1.8 | 3306 | ONLINE | 1 | 0 | 2 | 0 | 1440 | 115728 | 0 | 341 |
| 501 | 192.168.1.5 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 1210029 | 58927817 | 3706882671 | 97 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 1 | 11 | 12 | 0 | 16390790 | 798382865 | 49037691590 | 181 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 1 | 12 | 13 | 0 | 15357779 | 748038558 | 45950863867 | 64 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 1247662 | 60752227 | 3808131279 | 341 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 1766309 | 86046839 | 5374169120 | 422 |
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
Set global READ_ONLY=1;
on the following nodes 192.168.1.6/7/8/9
After:
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| 500 | 192.168.1.5 | 3306 | ONLINE | 10 | 0 | 20 | 0 | 25980 | 2088346 | 0 | 93 |
| 501 | 192.168.1.5 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 1787979 | 87010074 | 5473781192 | 93 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 4 | 8 | 12 | 0 | 18815907 | 916547402 | 56379724890 | 79 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 1 | 12 | 13 | 0 | 17580636 | 856336023 | 52670114510 | 131 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 15324 | 746109 | 46760779 | 822 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 16210 | 789999 | 49940867 | 679 |
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
In this scenario, IF a reader node crash, the application will not suffer at all given the redundancy.
But if the writer is going to crash THEN the issue exists, because there will be NO node available to manage the failover.
The solution is either do the node election manually, or to have the script elect the node with the lowest read weight in the same segment as new writer.
The one below is what is going to happen when a node crash (bird-eye view):
+---------+
| Crash |
+----+----+
|
v
+--------+-------+
| ProxySQL |
| shun crashed |
| node |
+--------+-------+
|
|
v
+-----------------+-----------------+
+-----------> HostGroup has another active |
| | Node in HG writer? |
| +--+--------------+---------------+-+
| | | |
| | | |
| |No | |Yes
| | | |
| +-----v----------+ | +-----------v----+
| |ProxySQL will | | |ProxySQL will |
| |stop serving | | |redirect load >--------+
| |writes | | |there | |
| +----------------+ | +----------------+ |
| | |
| v |
| +-------+--------+ |
| |ProxySQL checks | |
| |READ_ONLY on | |
| |Reader HG | |
| | | |
| +-------+--------+ |
| | |
| v |
| +-------+--------+ |
| |Any Node with | |
| |READ_ONLY = 0 ? | |
| +----------------+ |
| |No |Yes |
| | | |
| +----------v------+ +--v--------------+ |
| |ProxySQL will | |ProxySQL will | |
| |continue to | |Move node to | |
+<---------<+do not serve | |Writer HG | |
| |Writes | | | |
| +-----------------+ +--------v--------+ |
| | |
+-------------------------------------------+ |
+---------+ |
| END <------------------------+
+---------+
The script should act in the step immediately after ProxySQL SHUNNED the node, just replacing the READ_ONLY=1 with READ_ONLY=0, on the reader node with the lowest READ WEIGHT.
ProxySQL will do the rest, copying the Node into the WRITER HG, keeping low weight, such that WHEN/IF the original node will comeback, the new node will not compete for traffic.
I had included that special function in the check, the feature will allow automatic fail-over.
This experimental feature is active only if explicitly set in the parameter that the scheduler will pass to the script.
To activate it just add --active_failover list of arguments that is pass over the script in the scheduler.
My recommendation is to have two entries in the scheduler and activate the one with --active_failover for test, remember to deactivate the other.
Let see the manual procedure first
Process will be:
1 Generate some load
2 Kill the writer node
3 Manually elect a reader as writer
4 Recover crashed node
Current load:
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| 500 | 192.168.1.5 | 3306 | ONLINE | 10 | 0 | 10 | 0 | 30324 | 2437438 | 0 | 153 |
| 501 | 192.168.1.5 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 1519612 | 74006447 | 4734427711 | 153 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 4 | 8 | 12 | 0 | 7730857 | 376505014 | 24119645457 | 156 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 2 | 10 | 12 | 0 | 7038332 | 342888697 | 21985442619 | 178 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 612523 | 29835858 | 1903693835 | 337 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 611021 | 29769497 | 1903180139 | 366 |
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
Kill the main node 192.168.1.5
+-----------+-------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| 501 | 192.168.1.5 | 3306 | SHUNNED | 0 | 0 | 1 | 11 | 1565987 | 76267703 | 4879938857 | 119 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 1 | 11 | 12 | 0 | 8023216 | 390742215 | 25033271548 | 112 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 1 | 11 | 12 | 0 | 7306838 | 355968373 | 22827016386 | 135 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 638326 | 31096065 | 1984732176 | 410 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 636857 | 31025014 | 1982213114 | 328 |
+-----------+-------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
+-------------+------+------------------+----------------------+------------------------------------------------------+
| hostname | port | time_start_us | ping_success_time_us | ping_error |
+-------------+------+------------------+----------------------+------------------------------------------------------+
| 192.168.1.5 | 3306 | 1473070640798571 | 0 | Can't connect to MySQL server on '192.168.1.5' (107) |
| 192.168.1.5 | 3306 | 1473070610798464 | 0 | Can't connect TO MySQL server ON '192.168.1.5' (107) |
+-------------+------+------------------+----------------------+------------------------------------------------------+
+-------------+------+------------------+-------------------------+------------------------------------------------------+
| hostname | port | time_start_us | connect_success_time_us | connect_error |
+-------------+------+------------------+-------------------------+------------------------------------------------------+
| 192.168.1.5 | 3306 | 1473070640779903 | 0 | Can't connect to MySQL server on '192.168.1.5' (107) |
| 192.168.1.5 | 3306 | 1473070580779977 | 0 | Can't connect TO MySQL server ON '192.168.1.5' (107) |
+-------------+------+------------------+-------------------------+------------------------------------------------------+
When the node is killed ProxySQL Shun it and also report issues with the checks (connect and ping)
During this time frame the Application will experience issues, and if is not designed to manage the retry, and eventually a queue, it will crash.
Sysbench report the errors:
Writes
[ 10s] threads: 10, tps: 6.70, reads: 68.50, writes: 30.00, response time: 1950.53ms (95%), errors: 0.00, reconnects: 0.00
...
[1090s] threads: 10, tps: 4.10, reads: 36.90, writes: 16.40, response time: 2226.45ms (95%), errors: 0.00, reconnects: 1.00 <-+ killing the node
[1100s] threads: 10, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 1.00, reconnects: 0.00 |
[1110s] threads: 10, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 1.00, reconnects: 0.00 |
[1120s] threads: 10, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 1.00, reconnects: 0.00 |
[1130s] threads: 10, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 1.00, reconnects: 0.00 |-- Gap waiting for a node to become
[1140s] threads: 10, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 1.00, reconnects: 0.00 | READ_ONLY=0
[1150s] threads: 10, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 1.00, reconnects: 0.00 |
[1160s] threads: 10, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 1.00, reconnects: 0.00 |
[1170s] threads: 10, tps: 4.70, reads: 51.30, writes: 22.80, response time: 80430.18ms (95%), errors: 0.00, reconnects: 0.00 <-+
[1180s] threads: 10, tps: 8.90, reads: 80.10, writes: 35.60, response time: 2068.39ms (95%), errors: 0.00, reconnects: 0.00
...
[1750s] threads: 10, tps: 5.50, reads: 49.80, writes: 22.80, response time: 2266.80ms (95%), errors: 0.00, reconnects: 0.00 -- No additional errors
I decided to promote node 192.168.1.6 given in this setup the weight for readers was equal and as such no difference.
(root@localhost:pm) [(none)]>set global read_only=0;
Query OK, 0 rows affected (0.00 sec)
Checking proxySQL:
+-----------+-------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| 500 | 192.168.1.6 | 3306 | ONLINE | 10 | 0 | 10 | 0 | 1848 | 148532 | 0 | 40 |
| 501 | 192.168.1.5 | 3306 | SHUNNED | 0 | 0 | 1 | 72 | 1565987 | 76267703 | 4879938857 | 38 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 2 | 10 | 12 | 0 | 8843069 | 430654903 | 27597990684 | 40 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 1 | 11 | 12 | 0 | 8048826 | 392101994 | 25145582384 | 83 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 725820 | 35371512 | 2259974847 | 227 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 723582 | 35265066 | 2254824754 | 290 |
+-----------+-------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
As the READ_ONLY value is modified, ProxySQL move it to the writer Hostgroup and writes can take place again.
At this point in time production activities are recovered.
Reads had just a minor glitch:
Reads
[ 10s] threads: 10, tps: 0.00, reads: 20192.15, writes: 0.00, response time: 6.96ms (95%), errors: 0.00, reconnects: 0.00
...
[ 410s] threads: 10, tps: 0.00, reads: 16489.03, writes: 0.00, response time: 9.41ms (95%), errors: 0.00, reconnects: 2.50
...
[ 710s] threads: 10, tps: 0.00, reads: 18789.40, writes: 0.00, response time: 6.61ms (95%), errors: 0.00, reconnects: 0.00
when node 192.168.1.6 was copied over to HG 500, but no interruptions or errors.
At this point let us put back the crashed node, which coming back elect Node2 (192.168.1.6) as donor.
This was a PXC/Galera choice and we have to accept and manage it.
Note that the other basic scripts ( will put the node in OFFLINE_SOFT, given the node will become a DONOR).
Galera_check will recognize that Node2 (192.168.1.6) is the only active node in the segment for that specific HG (writer), while is not the only present for the READER HG.
As such it will put the node in OFFLINE_SOFT only for the READER HG, trying to reduce load on the node, but it will keep it active in the WRITER HG, to prevent service interruption.
Node restart and ask for a donor:
2016-09-05 12:21:43 8007 [Note] WSREP: Flow-control interval: [67, 67]
2016-09-05 12:21:45 8007 [Note] WSREP: Member 1.1 (node1) requested state transfer from '*any*'. Selected 0.1 (node2)(SYNCED) as donor.
2016-09-05 12:21:46 8007 [Note] WSREP: (ef248c1f, 'tcp://192.168.1.8:4567') turning message relay requesting off
2016-09-05 12:21:52 8007 [Note] WSREP: New cluster view: global state: 234bb6ed-527d-11e6-9971-e794f632b140:324329, view# 7: Primary, number of nodes: 5, my index: 3, protocol version 3
Galera_check will set OFFLINE_SOFT 192.168.1.6 only for the READER HG, and ProxySQL will use the others to serve reads.
+-----------+-------------+----------+--------------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| 500 | 192.168.1.6 | 3306 | ONLINE | 10 | 0 | 10 | 0 | 7746 | 622557 | 0 | 86 |
| 501 | 192.168.1.5 | 3306 | ONLINE | 0 | 0 | 1 | 147 | 1565987 | 76267703 | 4879938857 | 38 |
| 501 | 192.168.1.6 | 3306 | OFFLINE_SOFT | 0 | 0 | 12 | 0 | 9668944 | 470878452 | 30181474498 | 86 | <-- Node offline
| 501 | 192.168.1.7 | 3306 | ONLINE | 9 | 3 | 12 | 0 | 10932794 | 532558667 | 34170366564 | 62 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 816599 | 39804966 | 2545765089 | 229 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 814893 | 39724481 | 2541760230 | 248 |
+-----------+-------------+----------+--------------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
When SST donor task is over and Galera_check moves the 192.168.1.6 back ONLINE as expected.
But at the same time, it moves the recovering node to the special HG to avoid to have it included in any activity until ready.
2016-09-05 12:22:36 27352 [Note] WSREP: 1.1 (node1): State transfer FROM 0.1 (node2) complete.
2016-09-05 12:22:36 27352 [Note] WSREP: Shifting JOINER -> JOINED (TO: 325062)
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| 500 | 192.168.1.6 | 3306 | ONLINE | 10 | 0 | 10 | 0 | 1554 | 124909 | 0 | 35 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 2 | 8 | 22 | 0 | 10341612 | 503637989 | 32286072739 | 35 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 3 | 9 | 12 | 0 | 12058701 | 587388598 | 37696717375 | 13 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 890102 | 43389051 | 2776691164 | 355 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 887994 | 43296865 | 2772702537 | 250 |
| 9500 | 192.168.1.5 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 57 | <-- Special HG for recover
| 9501 | 192.168.1.5 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 57 | <-- Special HG for recover
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
Once finally the node is in SYNC with the group it is put back online in the READER HG and in the writer HG:
2016-09-05 12:22:36 27352 [Note] WSREP: 1.1 (node1): State transfer FROM 0.1 (node2) complete.
2016-09-05 12:22:36 27352 [Note] WSREP: Shifting JOINER -> JOINED (TO: 325062)
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
| 500 | 192.168.1.5 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | <-- Back on line
| 500 | 192.168.1.6 | 3306 | ONLINE | 10 | 0 | 10 | 0 | 402 | 32317 | 0 | 68 |
| 501 | 192.168.1.5 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 6285 | 305823 | 19592814 | 312 | <-- Back on line
| 501 | 192.168.1.6 | 3306 | ONLINE | 4 | 6 | 22 | 0 | 10818694 | 526870710 | 33779586475 | 68 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 0 | 12 | 12 | 0 | 12492316 | 608504039 | 39056093665 | 26 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 942023 | 45924082 | 2940228050 | 617 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 939975 | 45834039 | 2935816783 | 309 |
+-----------+-------------+----------+--------+----------+----------+--------+---------+----------+-----------------+-----------------+------------+
+--------------+-------------+------+--------+------------+
| hostgroup_id | hostname | port | STATUS | weight |
+--------------+-------------+------+--------+------------+
| 500 | 192.168.1.5 | 3306 | ONLINE | 100 |
| 500 | 192.168.1.6 | 3306 | ONLINE | 1000000000 |
| 501 | 192.168.1.5 | 3306 | ONLINE | 100 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 1000000000 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 1000000000 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 1 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 1 |
+--------------+-------------+------+--------+------------+
But given is coming back with its READER WEIGHT, it will NOT compete with the previously elected WRITER.
The recovered node will stay on "hold" waiting for a DBA to act and eventually put it back, or be set as READ_ONLY and as such be fully removed from the WRITER HG.
Let see the Automatic procedure now
As such let for the moment just stay stick to the MANUAL failover process.
Process will be:
1 Generate some load
2 Kill the writer node
3 Script will do auto-failover
4 Recover crashed node
Check our scheduler config:
+----+--------+-------------+-----------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------+------+------+------+---------+
| id | active | interval_ms | filename | arg1 | arg2 | arg3 | arg4 | arg5 | comment |
+----+--------+-------------+-----------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------+------+------+------+---------+
| 10 | 1 | 2000 | /var/lib/proxysql/galera_check.pl | -u=admin -p=admin -h=192.168.1.50 -H=500:W,501:R -P=3310 --execution_time=1 --retry_down=2 --retry_up=1 --main_segment=1 --active_failover --debug=0 --log=/var/lib/proxysql/galeraLog | NULL | NULL | NULL | NULL | | <--- Active
| 20 | 0 | 1500 | /var/lib/proxysql/galera_check.pl | -u=admin -p=admin -h=192.168.1.50 -H=500:W,501:R -P=3310 --execution_time=1 --retry_down=2 --retry_up=1 --main_segment=1 --debug=0 --log=/var/lib/proxysql/galeraLog | NULL | NULL | NULL | NULL | |
+----+--------+-------------+-----------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------+------+------+------+---------+
Active is the one with auto-failover
Start load and check Current load:
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| 500 | 192.168.1.5 | 3306 | ONLINE | 10 | 0 | 10 | 0 | 952 | 76461 | 0 | 0 |
| 501 | 192.168.1.5 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 53137 | 2587784 | 165811100 | 167 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 5 | 5 | 11 | 0 | 283496 | 13815077 | 891230826 | 109 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 3 | 7 | 10 | 0 | 503516 | 24519457 | 1576198138 | 151 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 21952 | 1068972 | 68554796 | 300 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 21314 | 1038593 | 67043935 | 289 |
+-----------+-------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
Kill the main node 192.168.1.5
+-----------+-------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | STATUS | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+-------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| 500 | 192.168.1.6 | 3306 | ONLINE | 10 | 0 | 10 | 0 | 60 | 4826 | 0 | 0 |
| 501 | 192.168.1.5 | 3306 | SHUNNED | 0 | 0 | 1 | 11 | 177099 | 8626778 | 552221651 | 30 |
| 501 | 192.168.1.6 | 3306 | ONLINE | 3 | 7 | 11 | 0 | 956724 | 46601110 | 3002941482 | 49 |
| 501 | 192.168.1.7 | 3306 | ONLINE | 2 | 8 | 10 | 0 | 1115685 | 54342756 | 3497575125 | 42 |
| 501 | 192.168.1.8 | 3306 | ONLINE | 0 | 1 | 1 | 0 | 76289 | 3721419 | 240157393 | 308 |
| 501 | 192.168.1.9 | 3306 | ONLINE | 1 | 0 | 1 | 0 | 75803 | 3686067 | 236382784 | 231 |
+-----------+-------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
When the node is killed the node is SHUNNED, but this time the script had already set the new node 192.168.1.6 ONLINE
See script log
2016/09/08 14:04:02.494:[INFO] END EXECUTION Total Time:102.347850799561
2016/09/08 14:04:04.478:[INFO] This Node Try to become a WRITER set READ_ONLY to 0 192.168.1.6:3306:HG501
2016/09/08 14:04:04.479:[INFO] This Node NOW HAS READ_ONLY = 0 192.168.1.6:3306:HG501
2016/09/08 14:04:04.479:[INFO] END EXECUTION Total Time:71.8140602111816
More important the application experience
Writes
[ 10s] threads: 10, tps: 9.40, reads: 93.60, writes: 41.60, response time: 1317.41ms (95%), errors: 0.00, reconnects: 0.00
[ 20s] threads: 10, tps: 8.30, reads: 74.70, writes: 33.20, response time: 1350.96ms (95%), errors: 0.00, reconnects: 0.00
[ 30s] threads: 10, tps: 8.30, reads: 74.70, writes: 33.20, response time: 1317.81ms (95%), errors: 0.00, reconnects: 0.00
[ 40s] threads: 10, tps: 7.80, reads: 70.20, writes: 31.20, response time: 1407.51ms (95%), errors: 0.00, reconnects: 0.00
[ 50s] threads: 10, tps: 6.70, reads: 60.30, writes: 26.80, response time: 2259.35ms (95%), errors: 0.00, reconnects: 0.00
[ 60s] threads: 10, tps: 6.60, reads: 59.40, writes: 26.40, response time: 3275.78ms (95%), errors: 0.00, reconnects: 0.00
[ 70s] threads: 10, tps: 5.70, reads: 60.30, writes: 26.80, response time: 1492.56ms (95%), errors: 0.00, reconnects: 1.00 <-- just a reconnect experience
[ 80s] threads: 10, tps: 6.70, reads: 60.30, writes: 26.80, response time: 7959.74ms (95%), errors: 0.00, reconnects: 0.00
[ 90s] threads: 10, tps: 6.60, reads: 59.40, writes: 26.40, response time: 2109.03ms (95%), errors: 0.00, reconnects: 0.00
[ 100s] threads: 10, tps: 6.40, reads: 57.60, writes: 25.60, response time: 1883.96ms (95%), errors: 0.00, reconnects: 0.00
[ 110s] threads: 10, tps: 5.60, reads: 50.40, writes: 22.40, response time: 2167.27ms (95%), errors: 0.00, reconnects: 0.00
No errors no huge delay, our application (managing reconnect) had only glitch, and had to reconnect.
Read had no errors or reconnects.
The connection errors were managed by ProxySQL and given it found 5 in 1sec it SHUNNED the node.
The galera_script was able to promote a reader, and given it is a failover no delay with retry loop.
The whole thing is done in such brief time that application barely see it.
Obviously an application with thousands of connections/sec will experience more impact, but the time-window will be very narrow, and that was our scope.
Once the failed node is ready to come back, either we choose to start it with READ_ONLY=1, as such it will come back as reader.
Or we will keep it as it is and it will come back as writer.
No matter what the script will manage the case as it had done in the previous (manual) exercise.
Conclusions
As shown ProxySQL and galera_check working together are quite efficient in managing the cluster and its different scenario.
When using the Single-Writer mode, solving the manual part of the failover dramatically improve the efficiency in performing the recovery of the production state, going from few minutes to seconds or less.
The Multiwriter mode remain the preferred and most recommended way to use ProxySQL/PXC given it will perform failover without the need of additional scripts or extension, also if a script is still required to manage the integration with ProxySQL.
In both cases the use of a script able to identify the multiple state of PXC and the mutable node scenario, is a crucial part of the implementation without which ProxySQL may not behave correctly.