What you may not know about random number generation in sysbench
Sysbench is a well known and largely used tool to perform benchmarking. Originally written by Peter Zaitsev in early 2000, it has become a de facto standard when performing testing and benchmarking. Nowadays it is maintained by Alexey Kopytov and can be found in Github at https://github.com/akopytov/sysbench.
What I have noticed though, is that while widely-used, some aspects of sysbench are not really familiar to many. For instance, the easy way to expand/modify the MySQL tests is using the lua extension, or the embedded way it handles the random number generation.
Why this article?
I wrote this article with the intent to show how easy it can be to customize sysbench to make it what you need. There are many different ways to extend sysbench use, and one of these is through proper tuning of the random IDs generation.
By default, sysbench comes with five different methods to generate random numbers. But very often, (in fact, almost all the time), none is explicitly defined, and even more rare is seeing some parametrization when the method allows it.
If you wonder “Why should I care? Most of the time defaults are good”, well, this blog post is intended to help you understand why this may be not true.
Let us start.
What methods do we have in sysbench to generate numbers? Currently the following are implemented and you can easily check them invoking the --help option in sysbench:
- Special
- Gaussian
- Pareto
- Zipfian
- Uniform
Of them Special is the default with the following parameters:
- rand-spec-iter=12 number of iterations for the special distribution [12]
- rand-spec-pct=1 percentage of the entire range where 'special' values will fall in the special distribution [1]
- rand-spec-res=75 percentage of 'special' values to use for the special distribution [75]
Given I like to have simple and easy reproducible tests and scenarios, all the following data has being collected using the sysbench commands:
- sysbench ./src/lua/oltp_read.lua --mysql_storage_engine=innodb --db-driver=mysql --tables=10 --table_size=100 prepare
- sysbench ./src/lua/oltp_read_write.lua --db-driver=mysql --tables=10 --table_size=100 --skip_trx=off --report-interval=1 --mysql-ignore-errors=all --mysql_storage_engine=innodb --auto_inc=on --histogram --stats_format=csv --db-ps-mode=disable --threads=10 --time=60 --rand-type=XXX run
Feel free to play by yourself with script instruction and data here (https://github.com/Tusamarco/blogs/tree/master/sysbench_random).
What is sysbench doing with the random number generator? Well, one of the ways it is used is to generate the IDs to be used in the query generation. So for instance in our case, it will look for numbers between 1 and 100, given we have 10 tables with 100 rows each.
What will happen if I run the sysbench RUN command as above, and change only the random –rand-type?
I have run the script and used the general log to collect/parse the generated IDs and count their frequencies, and here we go:
|
Special |
|
|
Uniform |
|
|
Zipfian |
|
|
Pareto |
|
|
Gaussian |
|
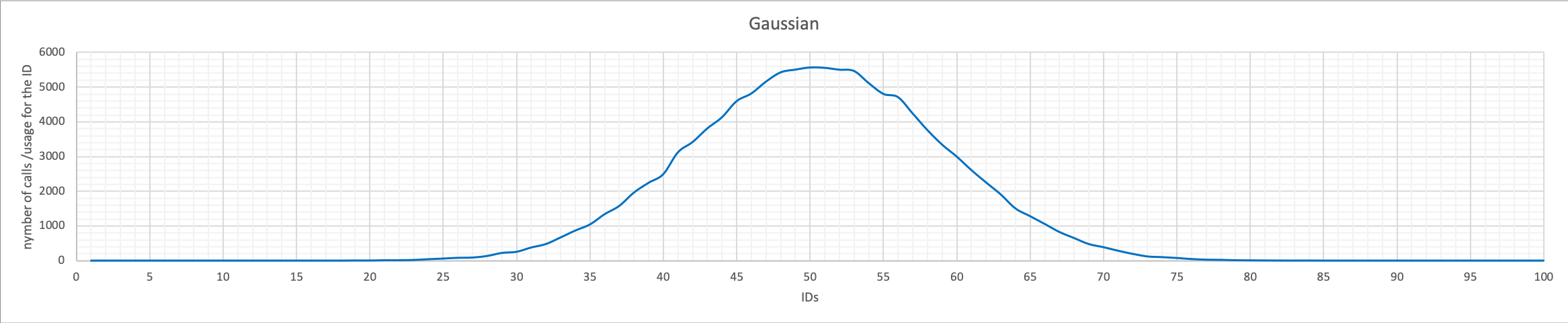
Makes a lot of sense right? Sysbench is, in the end, doing exactly what we were expecting.
Let us check one by one and do some reasoning around them.
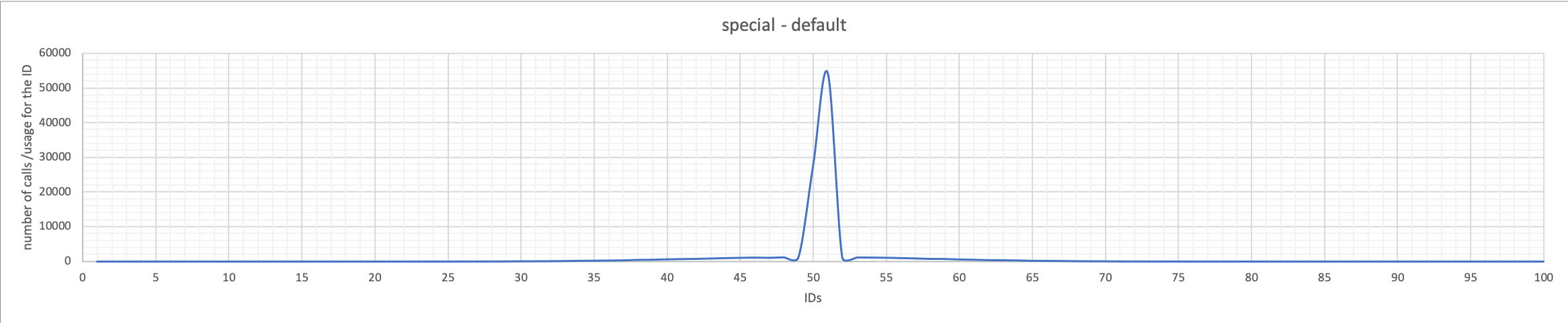
Special
The default is Special, so whenever you DO NOT specify a random-type to use, sysbench will use special. What special does is to use a very, very limited number of IDs for the query operations. Here we can actually say it will mainly use IDs 50-51 and very sporadically a set between 44-56, and the others are practically irrelevant. Please note, the values chosen are in the middle range of the available set 1-100.
In this case, the spike is focused on two IDs representing 2 percent of the sample. If I increase the number of records to one million, the spike still exists and is focused on 7493, which is 0.74% of the sample. Given that’s even more restrictive, the number of pages will probably be more than one.
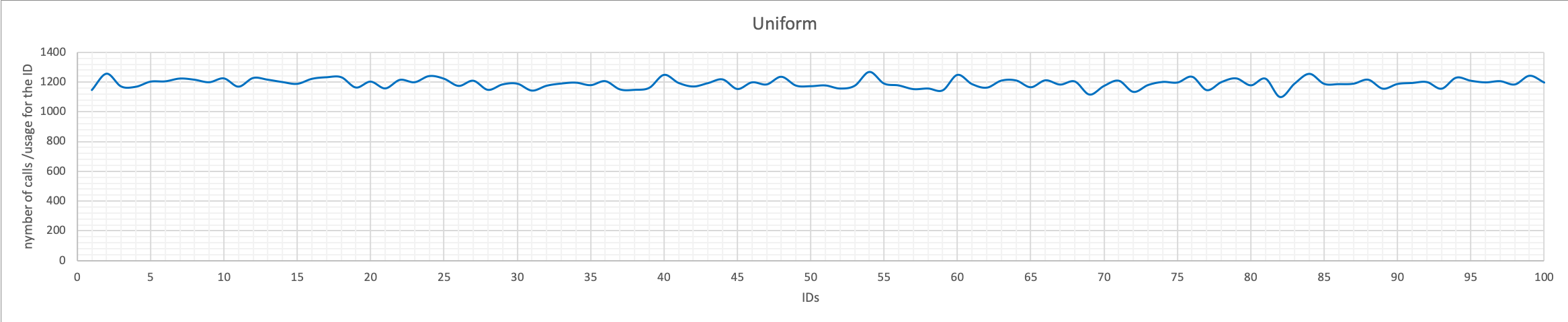
Uniform
As declared by the name, if we use Uniform, all the values are going to be used for the IDs and the distribution will be … Uniform.
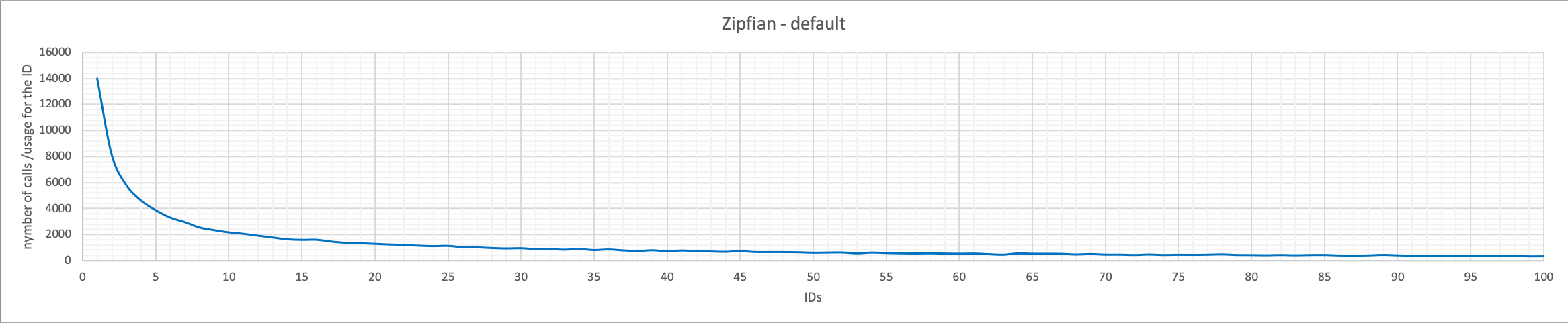
Zipfian
The Zipf distribution, sometimes referred to as the zeta distribution, is a discrete distribution commonly used in linguistics, insurance, and the modeling of rare events. In this case, sysbench will use a set of numbers starting from the lower (1) and reducing the frequency in a very fast way while moving towards bigger numbers.
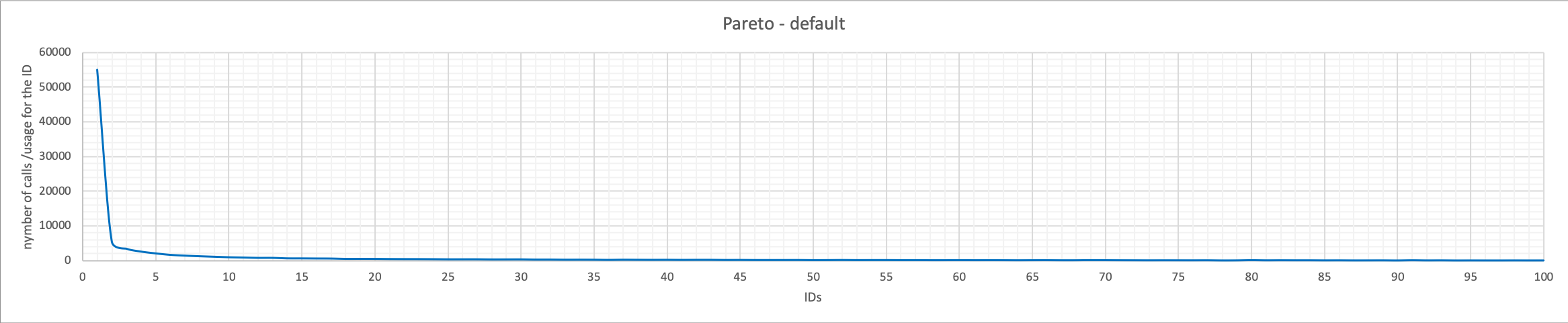
Pareto
With Pareto that applies the rule of 80-20 (read https://en.wikipedia.org/wiki/Pareto_distribution), the IDs we will use are even less distributed and more concentrated in a small segment. 52 percent of all IDs used were using the number 1, while 73 percent of IDs used were in the first 10 numbers.
Gaussian
Gaussian distribution (or normal distribution) is well known and familiar (see https://en.wikipedia.org/wiki/Normal_distribution) and mostly used in statistics and prediction around a central factor. In this case, the used IDs are distributed in a bell curve starting from the mid-value and slowly decreases towards the edges.
The point now is, what for?
Each one of the above cases represents something, and if we want to group them we can say that Pareto and Special can be focused on hot-spots. In that case, an application is using the same page/data over and over. This can be fine, but we need to know what we are doing and be sure we do not end up there by mistake.
For instance, IF we are testing the efficiency of InnoDB page compression in read, we should avoid using the Special or Pareto default, which means we must change sysbench defaults. This is in case we have a dataset of 1Tb and bufferpool of 30Gb, and we query over and over the same page. That page was already read from the disk-uncompressed-available in memory.
In short, our test is a waste of time/effort.
Same if we need to check the efficiency in writing. Writing the same page over and over is not a good way to go.
What about testing the performance?
Well again, are we looking to identify the performance, and against what case? It is important to understand that using a different random-type WILL impact your test dramatically. So your “defaults should be good enough” may be totally wrong.
The following graphs represent differences existing when changing ONLY the rand-type value, test type, time, additional option, and the number of threads are exactly the same.
Latency differs significantly from type to type:
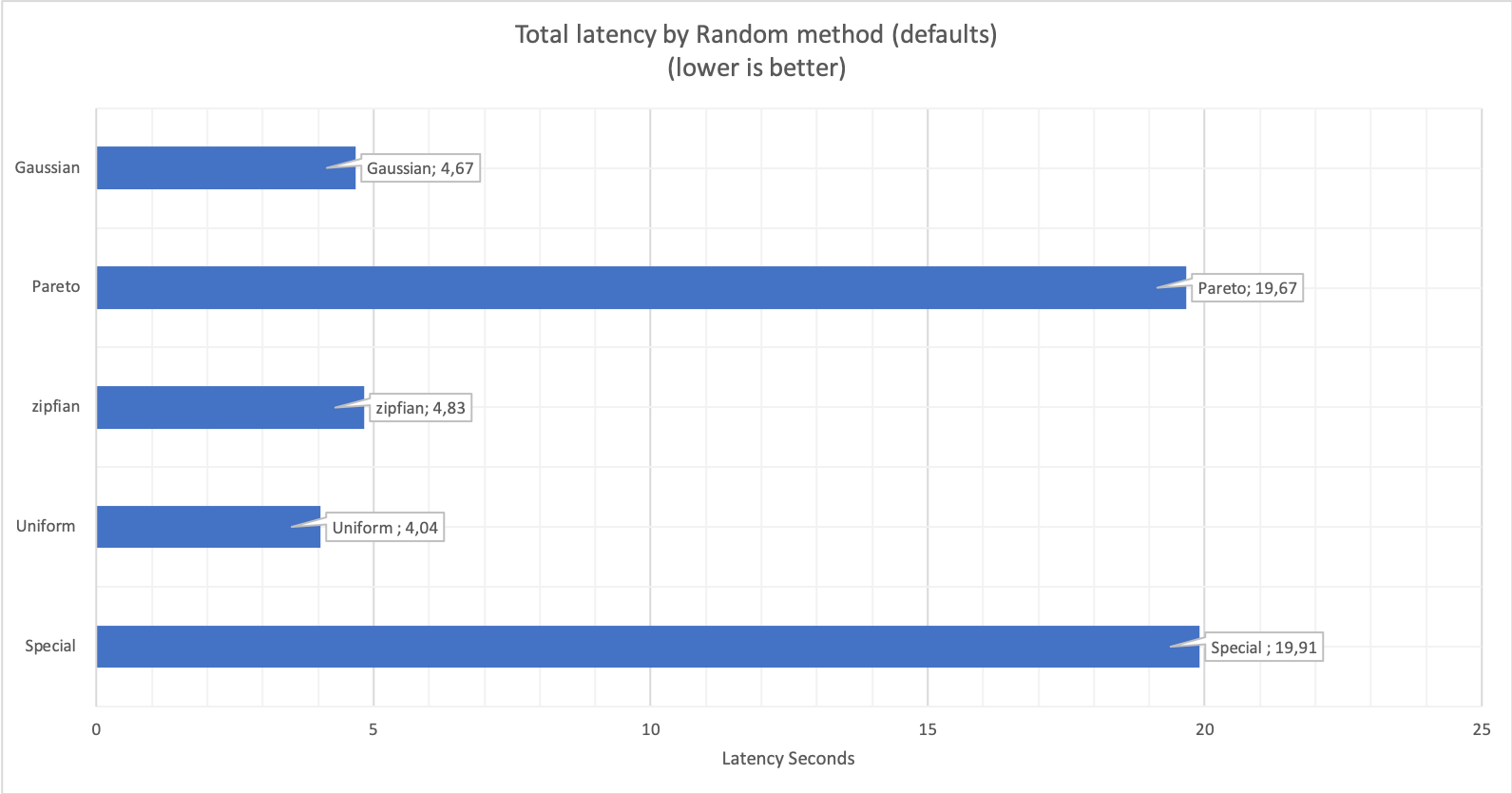
Here I was doing read and write, and data comes from the Performance Schema query by sys schema (sys.schema_table_statistics). As expected, Pareto and Special are taking much longer than the others given the system (MySQL-InnoDB) is artificially suffering for contention on one hot spot.
Changing the rand-type affects not only latency but also the number of processed rows, as reported by the performance schema.
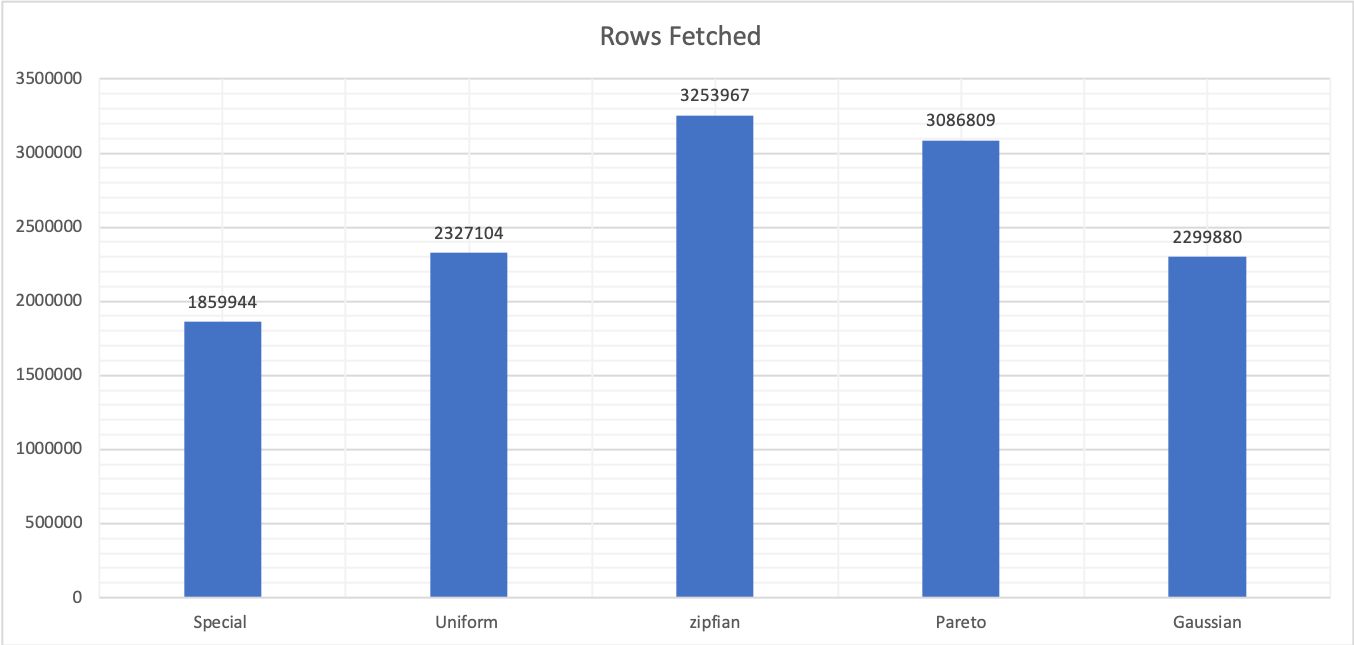
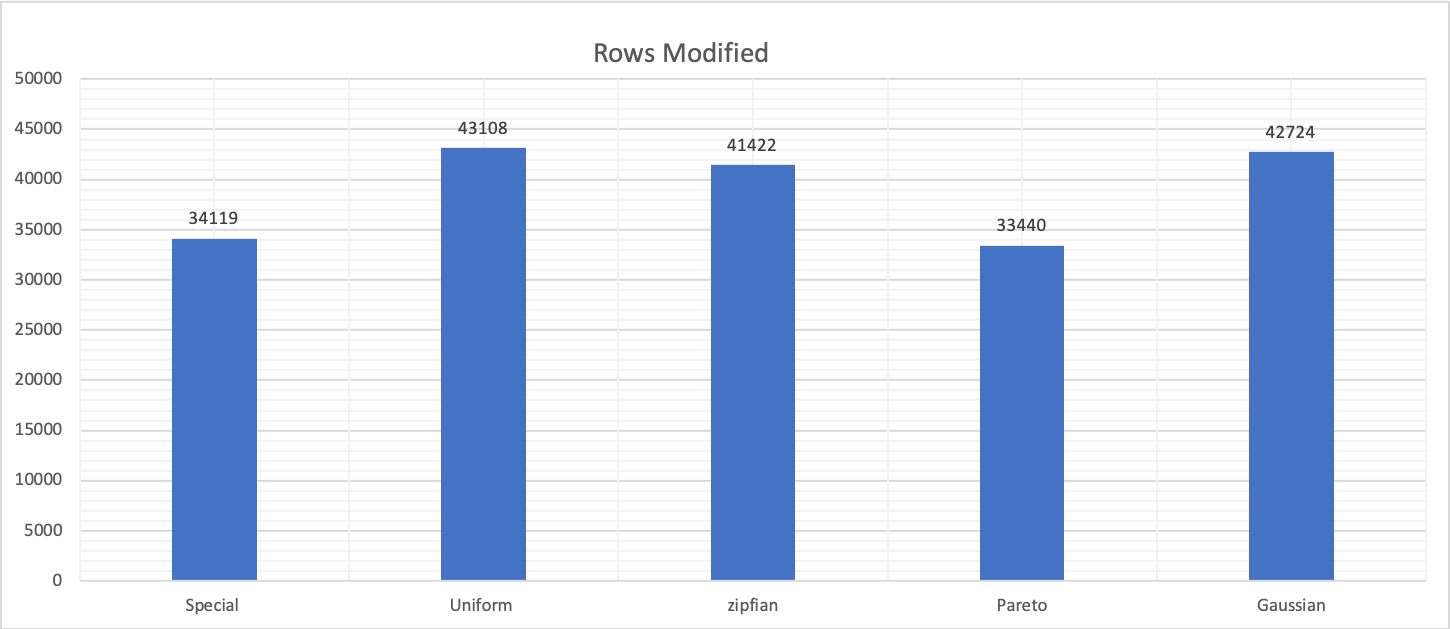
Given all the above, it is important to classify what we are trying to determine, and what we are testing.
If my scope is to test the performance of a system, at all levels, I may prefer to use Uniform, which will equally stress the dataset/DB Server/System and will have more chances to read/load/write all over the place.
If my scope is to identify how to deal with hot-spots, then probably Pareto and Special are the right choices.
But when doing that, do not go blind with the defaults. Defaults may be good, but they are probably recreating edge cases. That is my personal experience, and in that case, you can use the parameters to tune it properly.
For instance, you may still want to have sysbench hammering using the values in the middle, but you want to relax the interval so that it will not look like a spike (Special-default) but also not a bell curve (Gaussian).
You can customize Special and have something like :
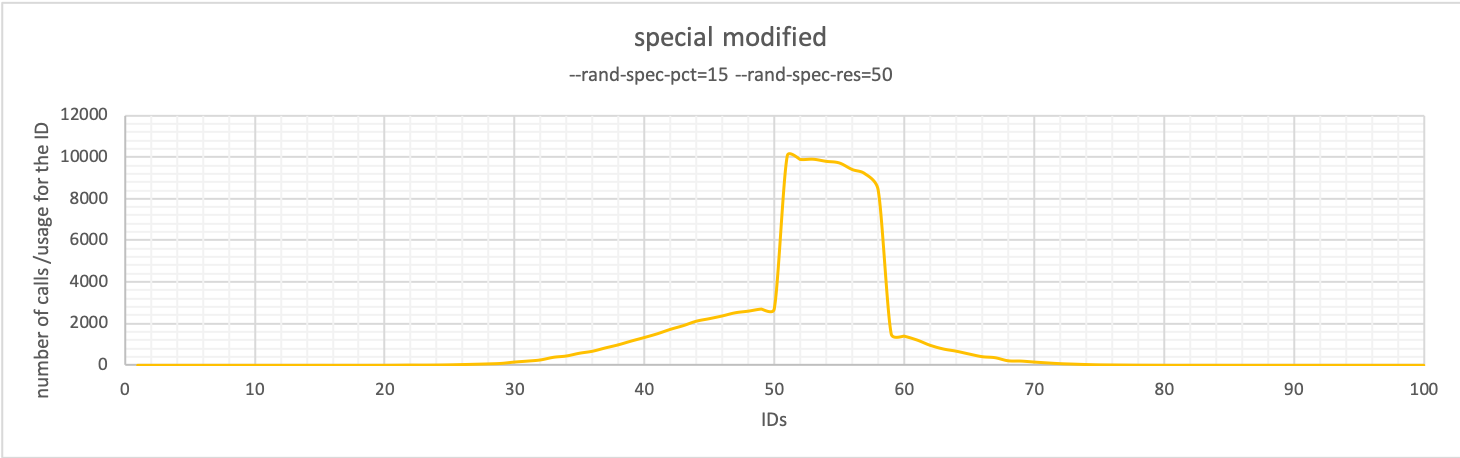
In this case, the IDs are still grouped and we still have possible contention, but less impact by a single hot-spot, so the range of possible contention is now on a set of IDs that can be on multiple pages, depending on the number of records by page.
Another possible test case is based on Partitioning. If, for instance, you want to test how your system will work with partitions and focus on the latest live data while archiving the old one, what can you do?
Easy! Remember the graph of the Pareto distribution? You can modify that as well to fit your needs.
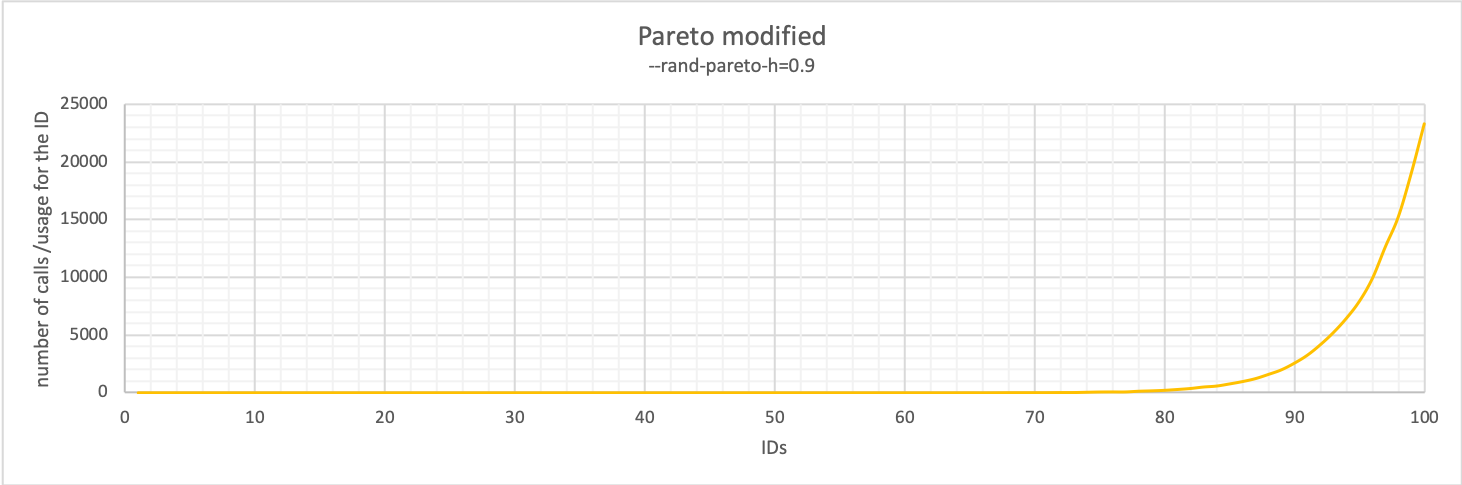
Just tuning the –rand-pareto value, you can easily achieve exactly what you were looking for and have sysbench focus the queries on the higher values of the IDs.
Zipfian can also be tuned, and while you cannot obtain an inversion as with Pareto, you can easily get from spiking on one value to equally distributed scenarios. A good example is the following:
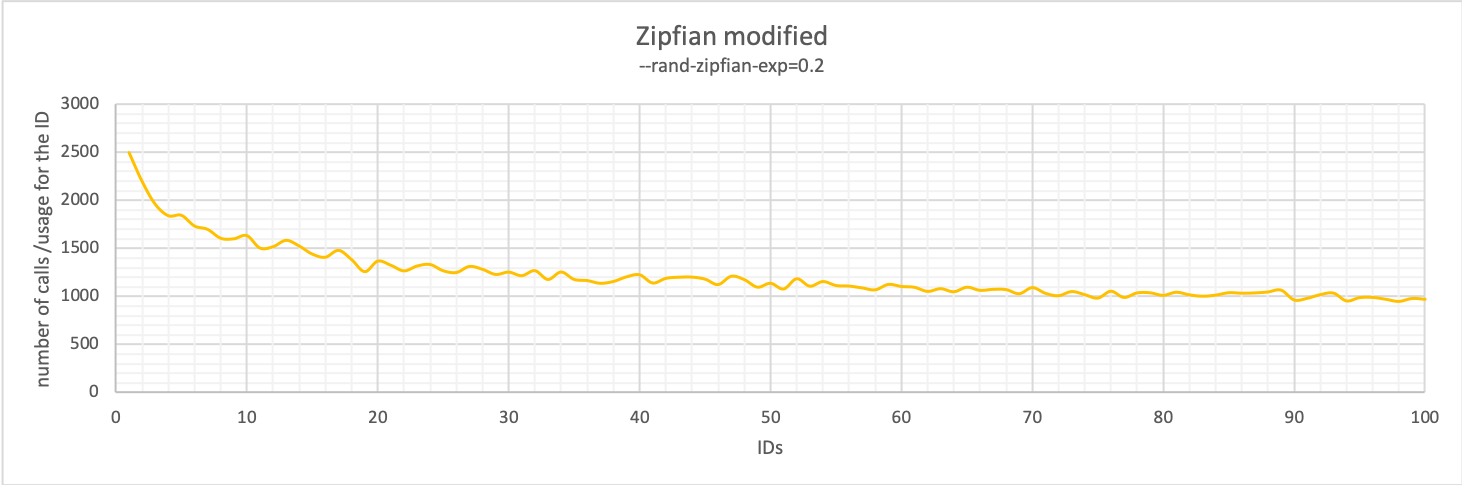
The last thing to keep in mind, and it looks to me that I am stating the obvious but better to say that than omit it, is that while you change the random specific parameters, the performance will also change.
See latency details:
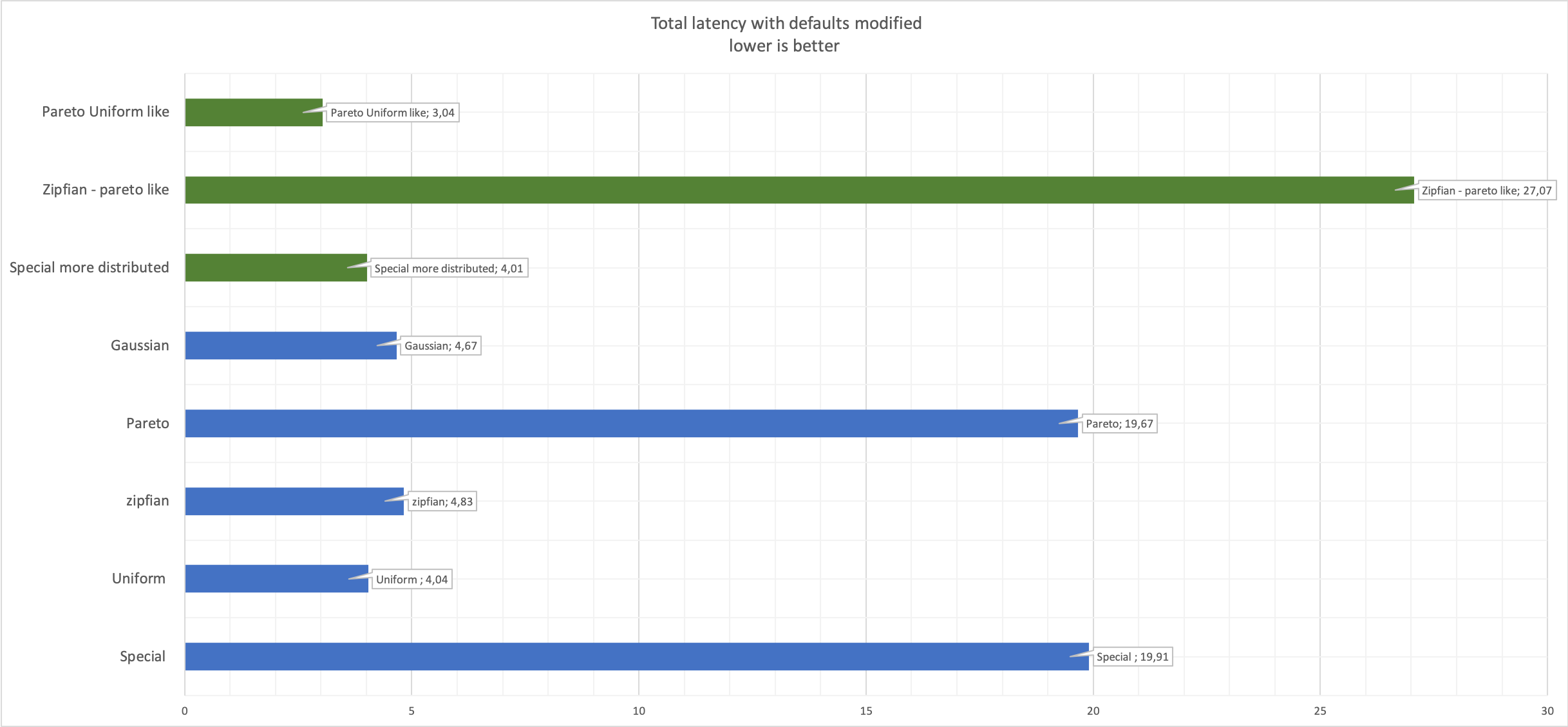
Here you can see in green the modified values compared with the original in blue.
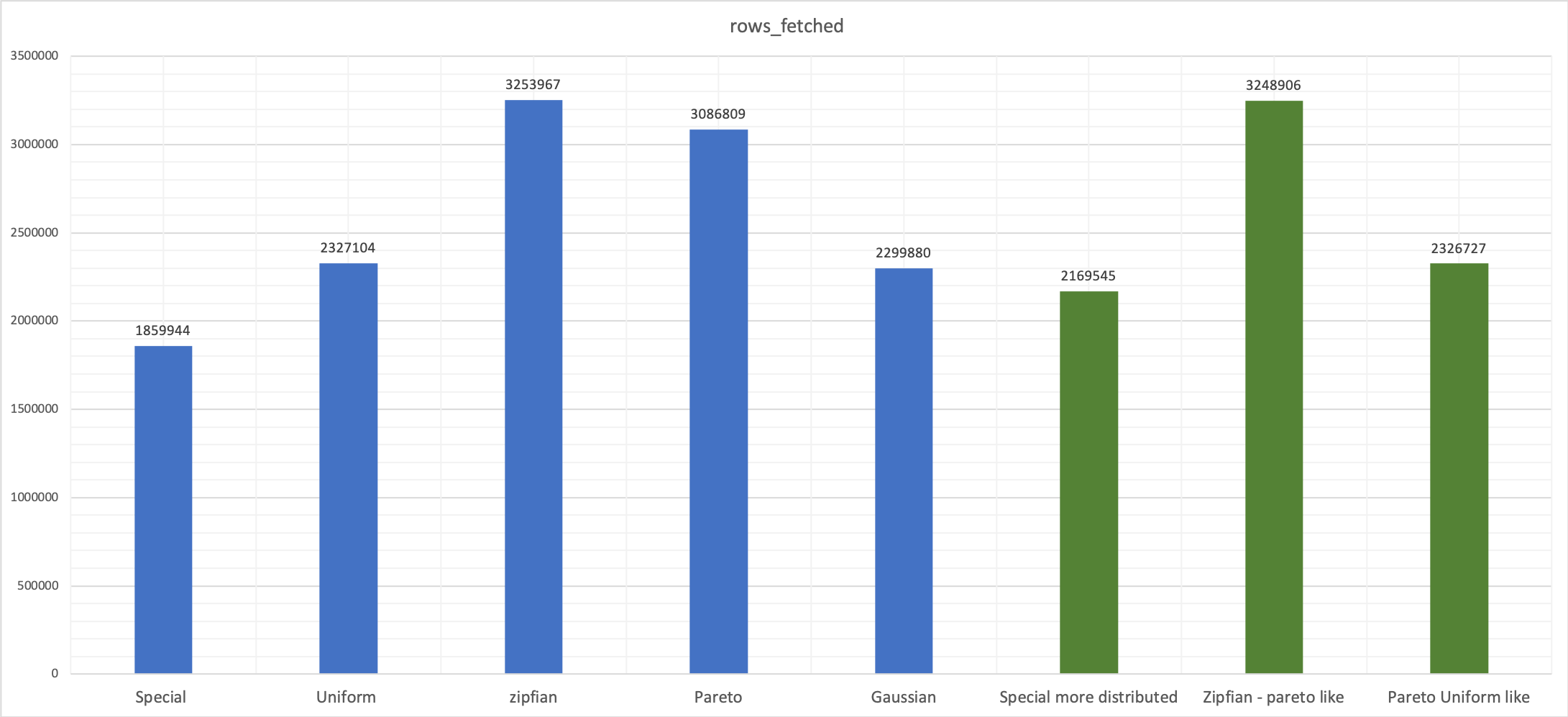
Conclusion
At this point, you should have realized how easy it can be to adjust the way sysbench works/handles the random generation, and how effective it can be to match your needs. Keep in mind that what I have mentioned above is valid for any call like the following, such as when we use the sysbench.rand.default call:
local function get_id()
return sysbench.rand.default(1, sysbench.opt.table_size)
End
Given that, do not just copy and paste strings from other people’s articles, think and understand what you need and how to achieve it.
Before running your tests, check the random method/settings to see how it comes up and if it fits your needs. To make it simpler for me, I use this simple test (https://github.com/Tusamarco/sysbench/blob/master/src/lua/test_random.lua). The test runs and will print a quite clear representation of the IDs distribution.
My recommendation is, identify what matches your needs and do your testing/benchmarking in the right way.
References
First and foremost reference is for the great work Alexey Kopytov is doing in working on sysbench https://github.com/akopytov/sysbench
Zipfian articles:
- https://www.percona.com/blog/2012/05/09/new-distribution-of-random-generator-for-sysbench-zipf/
- https://en.wikipedia.org/wiki/Zipf%27s_law
Pareto:
Percona article on how to extend tests in sysbench https://www.percona.com/blog/2019/04/25/creating-custom-sysbench-scripts/
The whole set material I used for this article is on github (https://github.com/Tusamarco/blogs/tree/master/sysbench_random)