For what reason should I use a real multi-Primary setup?
To be clear, not a multi-writer solution where any node can become the active writer in case of needs, as for PXC or PS-Group_replication.
No, we are talking about a multi-Primary setup where I can write at the same time on multiple nodes.
I want to insist on this “why?”.
After having excluded the possible solutions mentioned above, both covering the famous 99,995% availability, which is 26.30 minutes downtime in a year, what is left?
Disaster Recovery? Well that is something I would love to have, but to be a real DR solution we need to put several kilometers (miles for imperial) in the middle.
And we know (see here and here) that aside some misleading advertising, we cannot have a tightly coupled cluster solution across geographical regions.
So, what is left? I may need more HA, ok that is a valid reason. Or I may need to scale the number of writes, ok that is a valid reason as well.
This means, at the end, that I am looking to a multi-Primary because:
- Scale writes (more nodes more writes)
- Consistent reads (what I write on A must be visible on B)
- Gives me 0 (zero) downtime, or close to that (5 nines is a maximum downtime of 864 milliseconds per day!!)
- Allow me to shift the writer pointer at any time from A to B and vice versa, consistently.
Now, keeping myself bound to the MySQL ecosystem, my natural choice would be MySQL NDB cluster.
But my (virtual) boss was at AWS re-invent and someone mentioned to him that Aurora Multi-Primary does what I was looking for.
This (long) article is my voyage in discovering if that is true or … not.
Given I am focused on the behaviour first, and NOT interested in absolute numbers to shock the audience with millions of QPS, I will use low level Aurora instances. And will perform tests from two EC2 in the same VPC/region of the nodes.

You can find the details about the tests on GitHub here Finally I will test:
- Connection speed
- Stale read
- Write single node for baseline
- Write on both node:
- Scaling splitting the load by schema
- Scaling same schema
Tests results
Let us start to have some real fun. The first test is …
Connection Speed
The purpose of this test is to evaluate the time taken in opening a new connection and time taken to close it. The action of open/close connection can be a very expensive operation especially if applications do not use a connection pool mechanism.
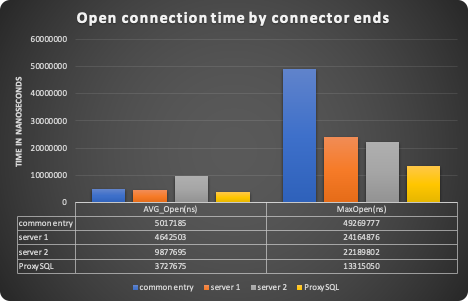
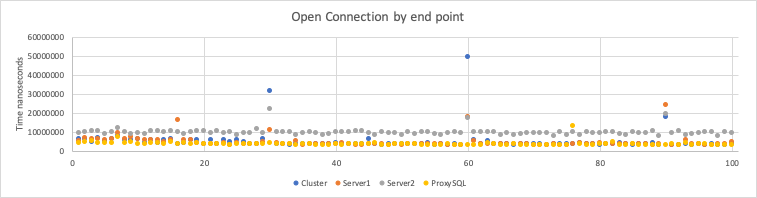
As we can see ProxySQL results to be the most efficient way to deal with opening connections, which was expected given the way it is designed to reuse open connections towards the backend.
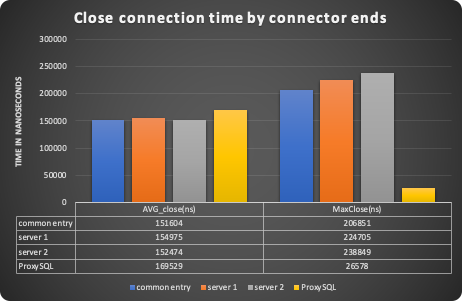
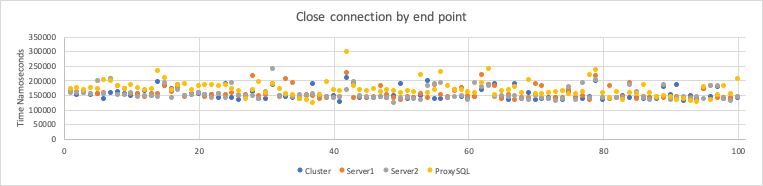
Different is the close connection operation in which ProxySQL seems to take a little bit longer. As global observation we can say that using ProxySQL we have more consistent behaviour. Of course this test is a simplistic one, and we are not checking the scalability (from 1 to N connections) but it is good enough to give us the initial feeling. Specific connection tests will be the focus of the next blog on Aurora MM.
Stale Reads
Aurora MultiPrimary use the same mechanism of the default Aurora to update the buffer pool:

Using the Page Cache update, just doing both ways. This means that the Buffer Pool of Node2 is updated with the modification performed in Node1 and vice versa.
To verify if an application would be really able to have consistent reads, I have run this test. This test is meant to measure if, and how many, stale reads we will have when writing on a node and reading from the other.
Amazon Aurora multi Primary has 2 consistency model:

As an interesting fact the result was that with the default consistency model (INSTANCE_RAW), we got 100% stale read.
Given that I focused on identifying the level of the cost that exists when using the other consistency model (REGIONAL_RAW) that allows an application to have consistent reads.
The results indicate an increase of the 44% in total execution time, and of the 95% (22 time slower) in write execution.
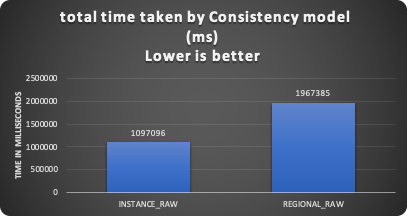

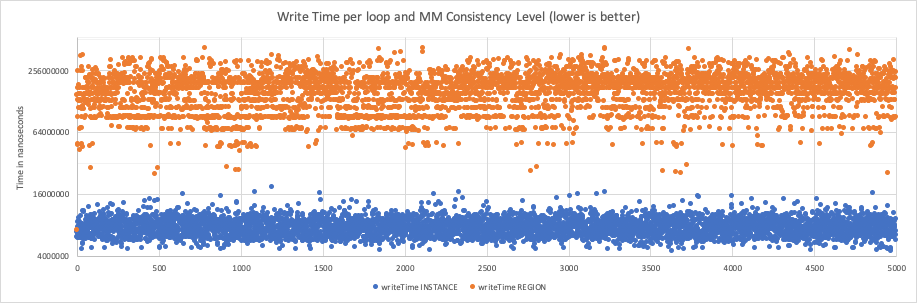
It is interesting to note that the time taken is in some way predictable and consistent between the two consistency models.
The graph below shows in yellow how long the application must wait to see the correct data on the reader node. While in blue is the amount of time the application waits to get back the same consistent read because it must wait for the commit on the writer.
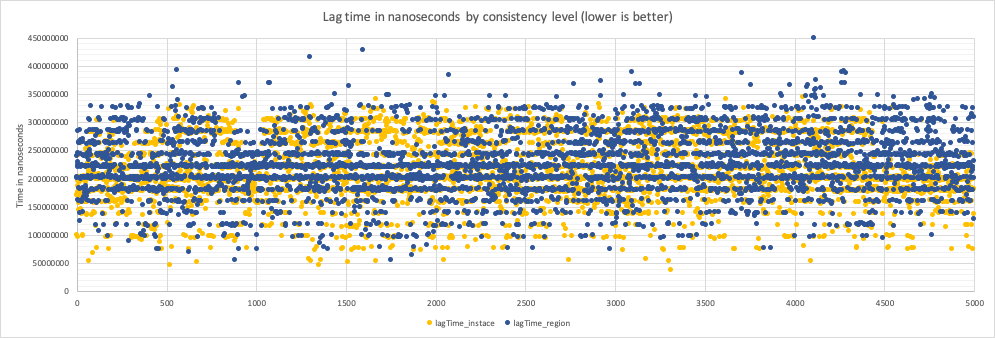
As you can see the two are more or less aligned. Given the performance cost imposed by using REGIONAL_RAW, all the other tests are done the defaut INSTANCE_RAW, unless explicitly stated.
Writing tests
All tests run in this section were done using sysbench-tpcc with the following settings:
sysbench ./tpcc.lua --mysql-host=<> --mysql-port=3306 --mysql-user=<> --mysql-password=<> --mysql-db=tpcc --time=300 --threads=32 --report-interval=1 --tables=10 --scale=15 --mysql_table_options=" CHARSET=utf8 COLLATE=utf8_bin" --db-driver=mysql prepare sysbench /opt/tools/sysbench-tpcc/tpcc.lua --mysql-host=$mysqlhost --mysql-port=$port --mysql-user=<> --mysql-password=<> --mysql-db=tpcc --db-driver=mysql --tables=10 --scale=15 --time=$time --rand-type=zipfian --rand-zipfian-exp=0 --report-interval=1 --mysql-ignore-errors=all --histogram --report_csv=yes --stats_format=csv --db-ps-mode=disable --threads=$threads run
Write Single node (Baseline)
Before starting the comparative analysis, I was looking to define what was the “limit” of traffic/load for this platform.
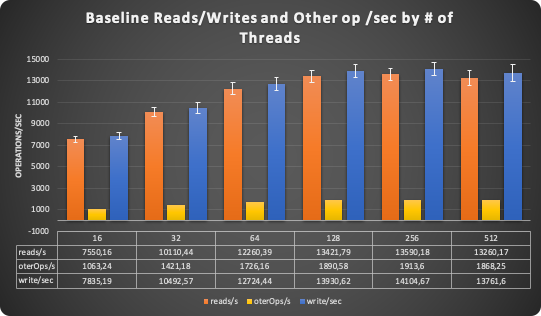
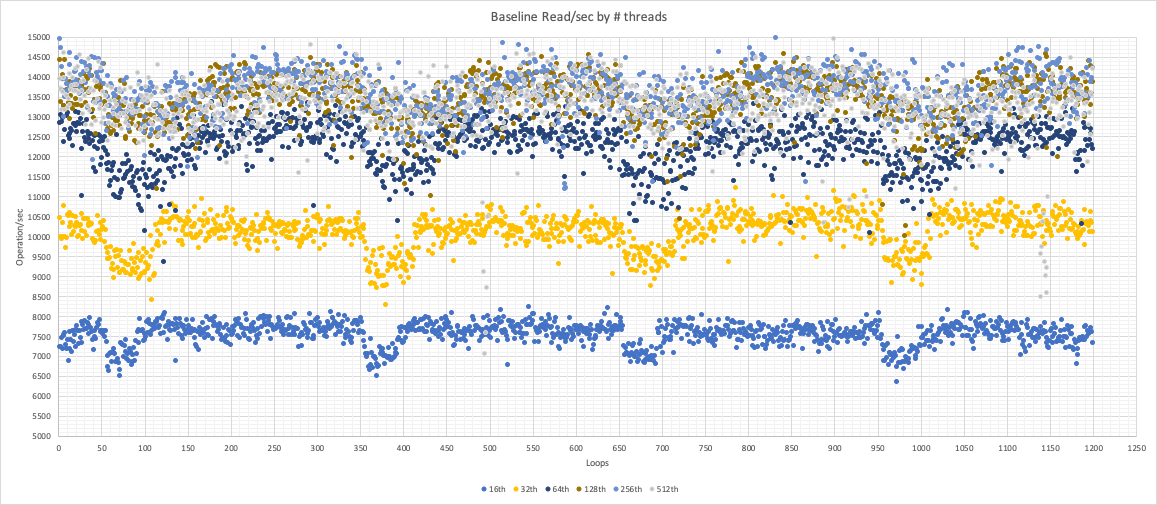
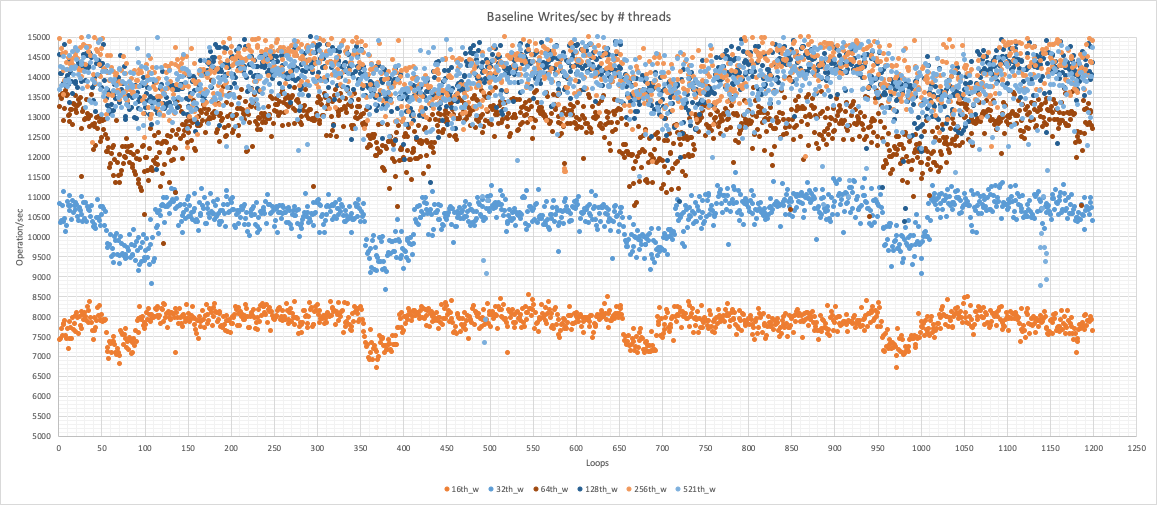
From the graph above, we can see that this setup scales up to 128 threads after that, the performance remains more or less steady.
Amazon claims that we can mainly double the performance when using both nodes in write mode and use a different schema to avoid conflict.
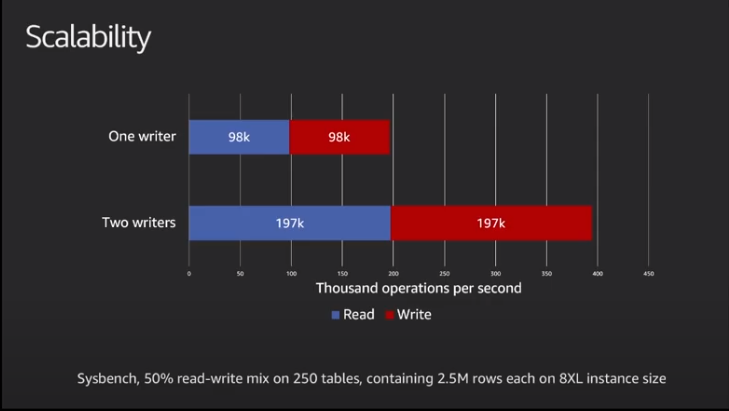
Once more remember I am not interested in the absolute numbers here, but I am expecting the same behaviour Given that our expectation is to see:
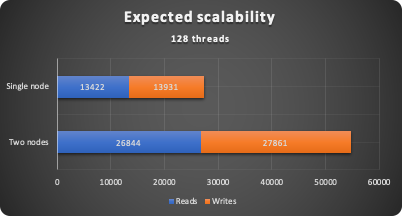
Write on both nodes different schemas
So AWS recommend this as the scaling solution:

And I diligently follow the advice.
I used 2 EC2 nodes in the same subnet of the Aurora Node, writing to a different schema (tpcc & tpcc2).
Overview
Let us make it short and go straight to the point. Did we get the expected scalability?
Well no:
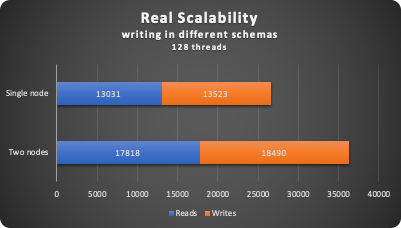
We just had 26% increase, quite far to be the expected 100% Let us see what happened in detail (if not interested just skip and go to the next test).
Node 1
Node 2
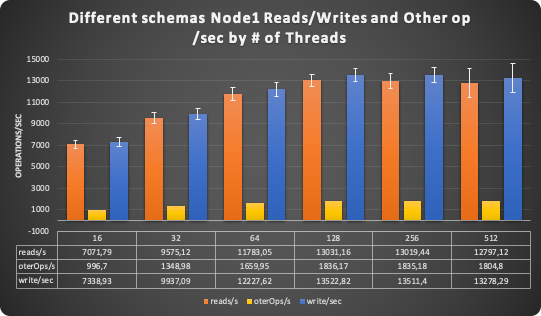
As you can see Node1 was (more or less) keeping up with the expectations and being close to the expected performance.
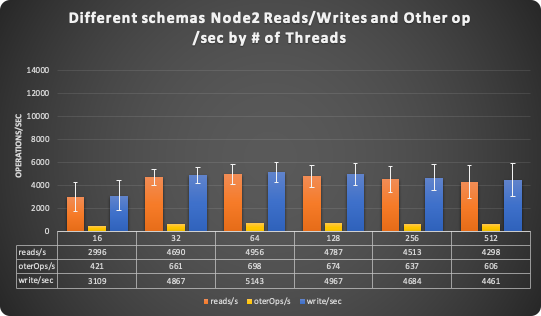
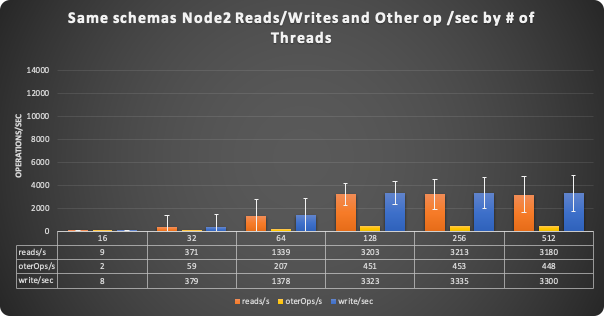
But Node2 was just not keeping up, performances there were just terrible.
The graphs below show what happened.
While Node1 was (again more or less) scaling up to the baseline expectations (128 threads), Node2 collapsed on its knees at 16 threads. Node2 was never able to scale up.
Reads
Node 1
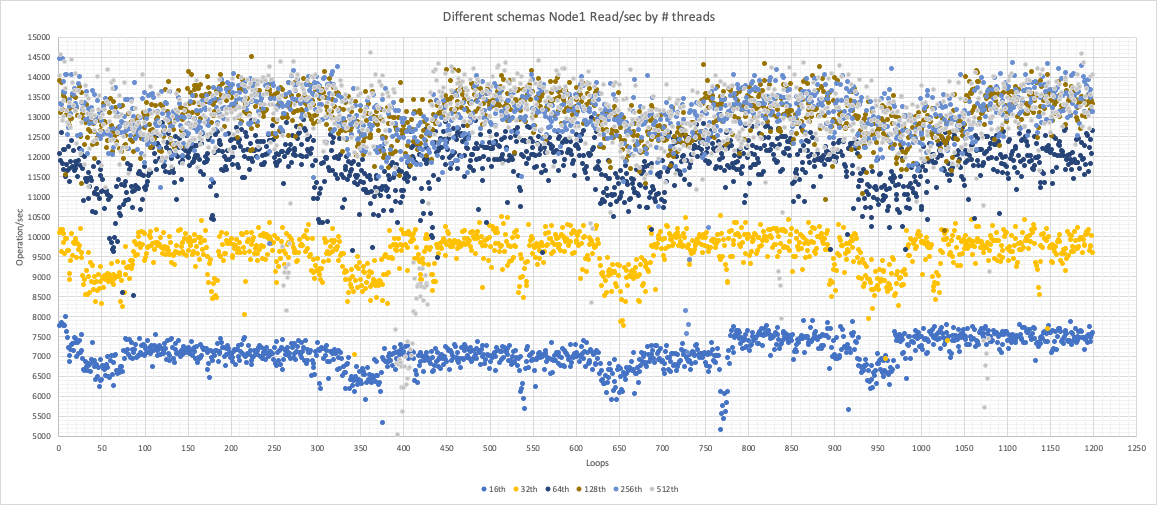
Node1 is scaling the reads as expected also if here and there we can see performance deterioration.
Node 2
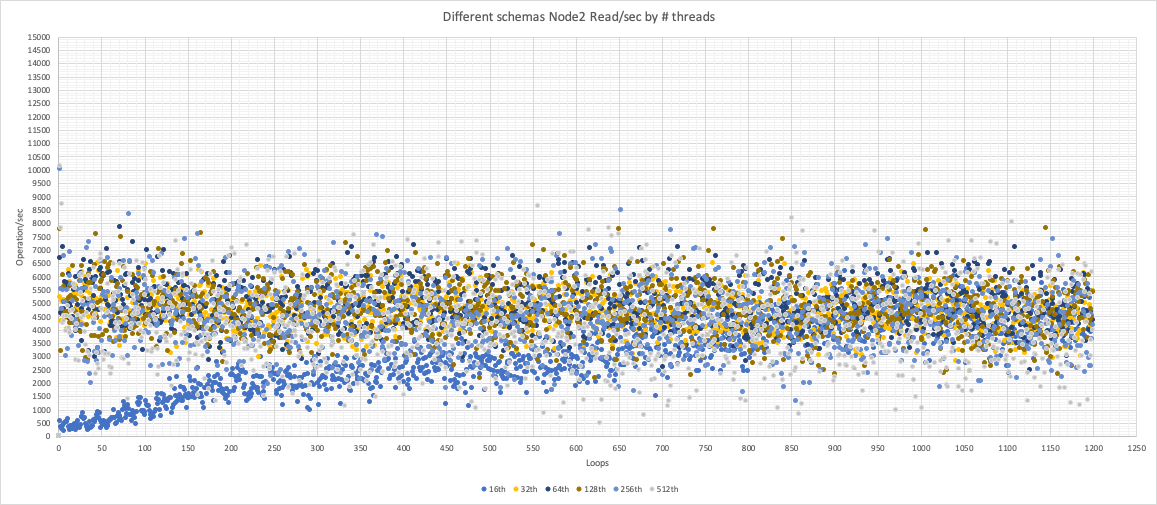
Node2 is not scaling Reads at all.
Writes
Node 1
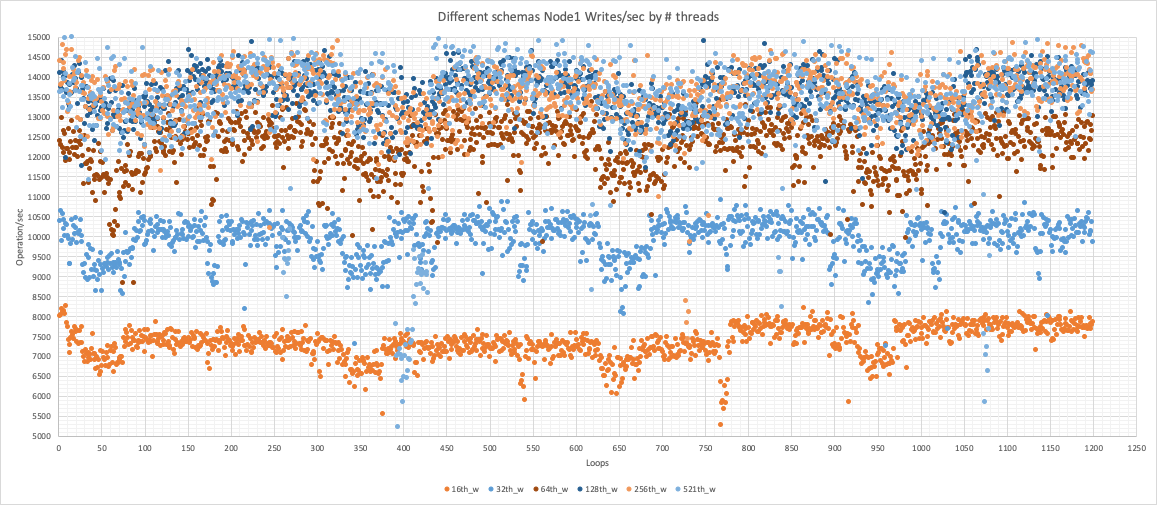
Same as Read
Node 2
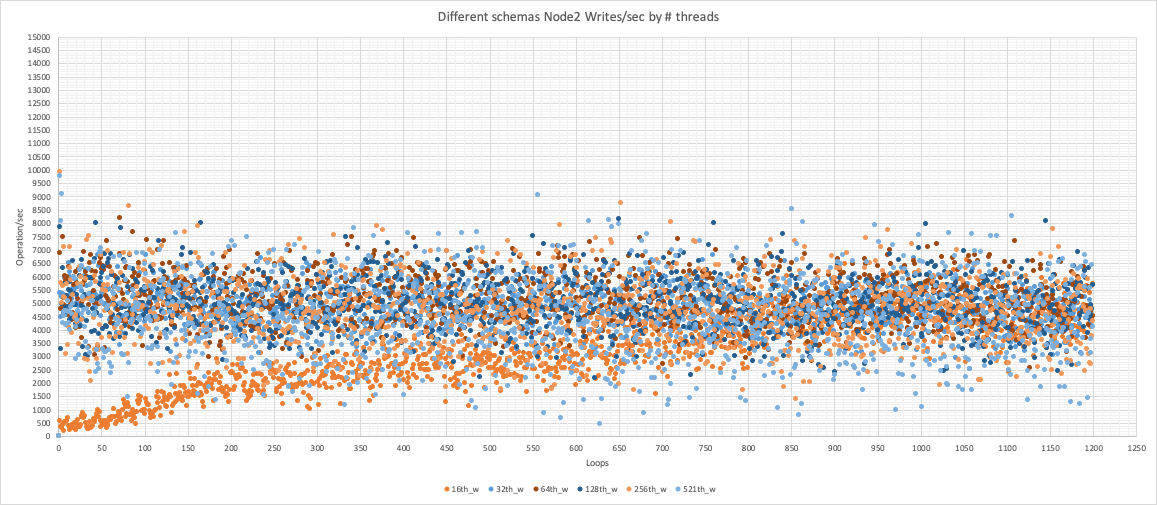
Same as read
Now someone may think I was making a mistake and I was writing on the same schema. I assure you I was not.
Check the next test to see what happened if using the same schema.
Write on both nodes same schema
Overview
Now, now Marco, this is unfair. You know this will cause contention.
Yes I do! But nonetheless I was curious to see what was going to happen and how the platform would deal with that level of contention.
My expectations were to have a lot of performance degradation and increased number of locks. About conflict I was not wrong, node2 after the test reported:
+-------------+---------+-------------------------+ | table | index | PHYSICAL_CONFLICTS_HIST | +-------------+---------+-------------------------+ | district9 | PRIMARY | 3450 | | district6 | PRIMARY | 3361 | | district2 | PRIMARY | 3356 | | district8 | PRIMARY | 3271 | | district4 | PRIMARY | 3237 | | district10 | PRIMARY | 3237 | | district7 | PRIMARY | 3237 | | district3 | PRIMARY | 3217 | | district5 | PRIMARY | 3156 | | district1 | PRIMARY | 3072 | | warehouse2 | PRIMARY | 1867 | | warehouse10 | PRIMARY | 1850 | | warehouse6 | PRIMARY | 1808 | | warehouse5 | PRIMARY | 1781 | | warehouse3 | PRIMARY | 1773 | | warehouse9 | PRIMARY | 1769 | | warehouse4 | PRIMARY | 1745 | | warehouse7 | PRIMARY | 1736 | | warehouse1 | PRIMARY | 1735 | | warehouse8 | PRIMARY | 1635 | +-------------+---------+-------------------------+
Which is obviously a strong indication something was not working right. In terms of performance gain, if we compare ONLY the result with the 128 Threads : 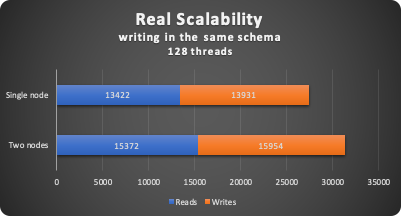
Also with the high level of conflict we still have 12% of performance gain.
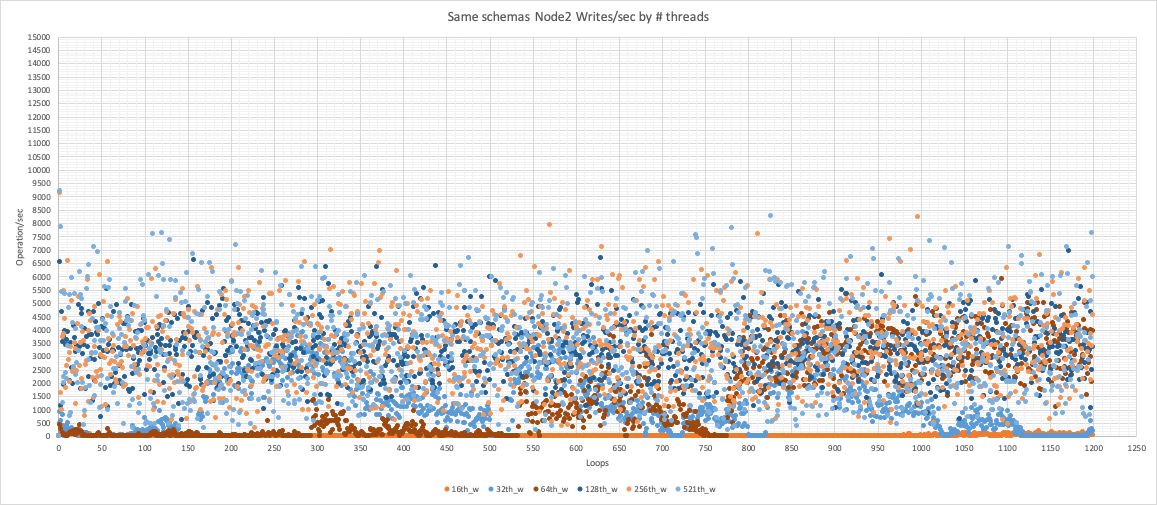
The problem is that in general we have the two nodes behave quite badly.
If you check the graph below you can see that the level of conflict is such to prevent the nodes not only to scale but to act consistently.
Node 1
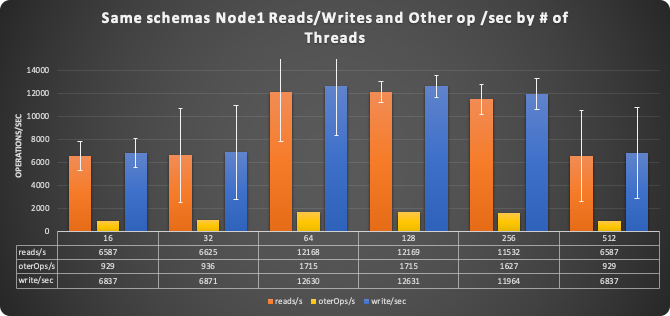
Node 2
Reads
In the following graphs we can see how node1 had issues and it actually crashed 3 times, during tests with 32/64/512 treads.
Node2 was always up but the performances were very low.
Node 1
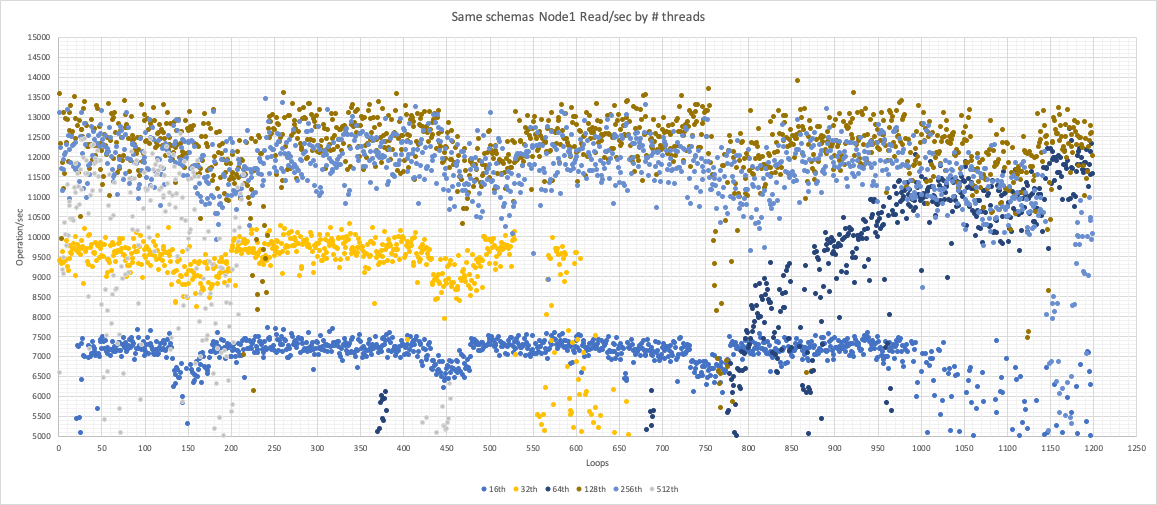
Node 2
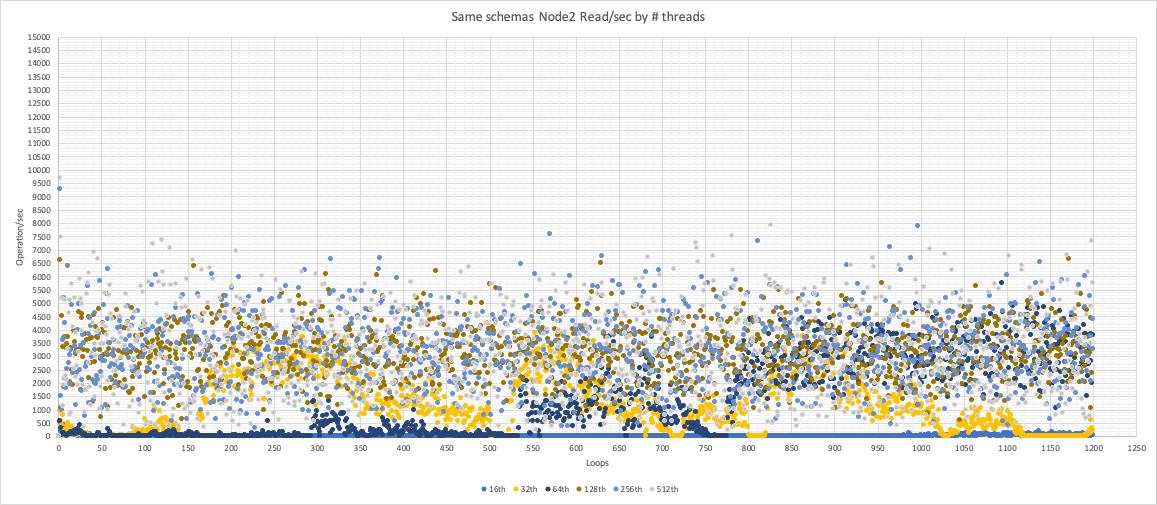
Writes
Node 1
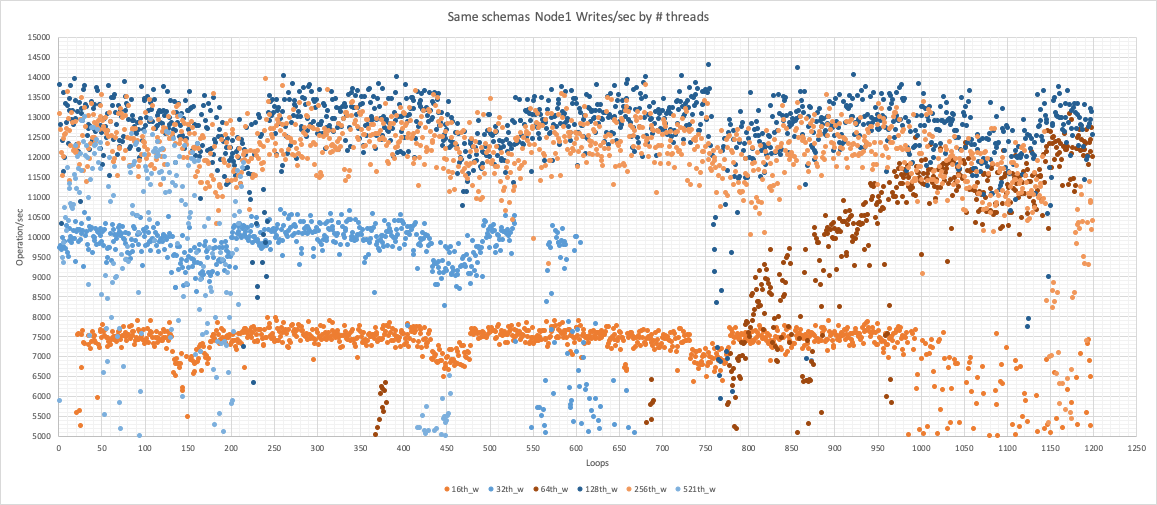
Node 2
Recovery from crashed Node
About recovery time reading the AWS documentation and listening to presentations, I often heard that Aurora Multi Primary is a 0 downtime solution.
Or other statements like: “in applications where you can't afford even brief downtime for database write operations, a multi-master cluster can help to avoid an outage when a writer instance becomes unavailable. The multi-master cluster doesn't use the failover mechanism, because it doesn't need to promote another DB instance to have read/write capability”
To achieve this the suggestion I found, was to have applications pointing directly to the Nodes endpoint and not use the Cluster endpoint.
In this context the solution pointing to the Nodes should be able to failover within a seconds or so, while the cluster endpoint:

Personally I think that designing an architecture where the application is responsible for the connection to the database and failover is some kind of refuse from 2001. But if you feel this is the way, well go for it.
What I did for testing is to use ProxySQL, as plain as possible, with nothing else then the basic monitor coming from the native monitor.
I then compare the results with the tests using the Cluster endpoint.
In this way I adopt the advice of pointing directly at the nodes, but I was doing things in our time.
The results are below and they confirm (more or less) the data coming from Amazon.
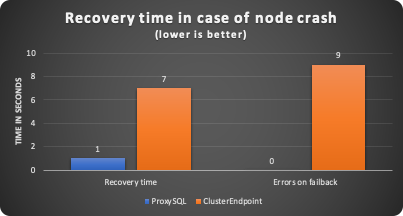
A downtime of 7 seconds is quite a long time nowadays, especially if I am targeting the 5 nines solution that I want to remember is 864 ms downtime per day.
Using ProxySQL is going closer to that, still too long to be called 0 (zero) downtime.
I also have fail-back issues when using the AWS cluster endpoint.
Given it was not able to move the connection to the joining node seamlessly.
Last but not least when using the consistency level INSTANCE_RAW, I had some data issue as well as PK conflict:
FATAL: mysql_drv_query() returned error 1062 (Duplicate entry '18828082' for key 'PRIMARY')
Conclusions
As state the beginning of this long blog the reasons expectations to go for a multi Primary solution were:
- Scale writes (more nodes more writes)
- Gives me 0 (zero) downtime, or close to that (5 nines is a maximum downtime of 864 milliseconds per day!!)
- Allow me to shift the writer pointer at any time from A to B and vice versa, consistently.
Honestly I feel we have completely failed the scaling point.

Probably if I use the largest Aurora I will get much better absolute numbers, and it will take me more to encounter the same issues, but I will.
In any case if the Multi muster solution is designed to provide that scalability, it should do that with any version.
I did not have zero downtime, but I was able to failover pretty quickly with ProxySQL.
Finally, unless the consistency model is REGIONAL_RAW, shifting from one node to the other is not prone to possible negative effects like stale reads.
Because that I consider this requirement not satisfied in full.
Given all the above, I think this solution could eventually be valid only for High Availability (close to be 5 nines), but given it comes with some limitations I do not feel comfortable in preferring it over others just for HA, at the end default Aurora is already good enough as a High available solution.
references
https://www.youtube.com/watch?v=p0C0jakzYuc
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-multi-master.html
https://www.slideshare.net/marcotusa/robust-ha-solutions-with-proxysql