If you have a business no matter how small, you are collecting data, and you need to have your data accessible to make informed decisions about how to make your business better. The more successful you become the more data you are producing and the more you become dependent by it. This is when you start to realize your must have your data in a safe place like a database instead some spreadsheet.
But to put your data in a database is not enough, you must be sure the database will be robust, resilient, and always available when you or your customers need it.
When design architectures for robust database architectures, we always discuss about High Availability (HA) and Disaster Recovery (DR). These two concepts are elements of the larger umbrella that is the Business continuity plan.
To cover the different needs, we (Database Architects) use/apply two main models: Tightly Coupled cluster, and Loosely Coupled cluster (latest presentation https://www.slideshare.net/marcotusa/best-practicehigh-availabilitysolutiongeodistributedfinal).
The combination of the two different model allow us to build solid, resilient, scalable HA solution geographically distributed.
Like this:
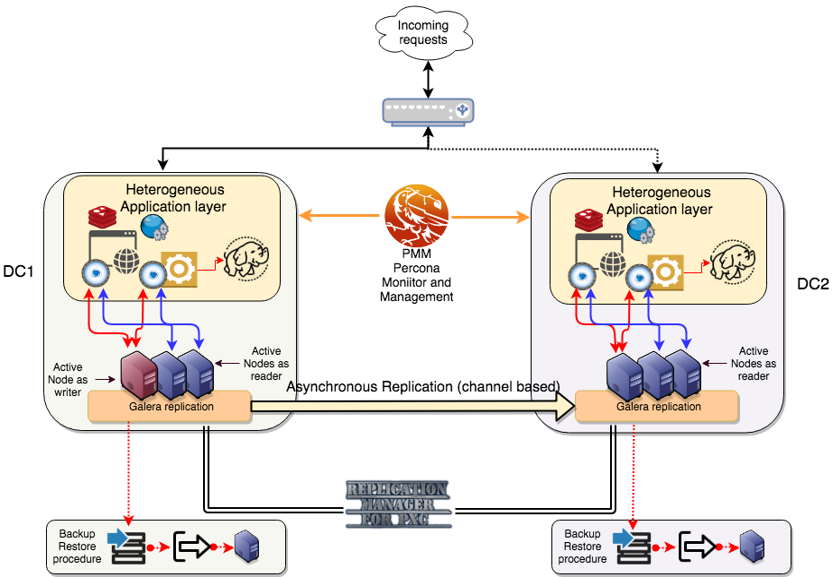
Until now the part that was NOT natively supported in the architecture above was how to failover the replication channel from a node to another node in case of crash.
This element is currently cover by custom script(https://github.com/y-trudeau/Mysql-tools/tree/master/PXC) develop by my colleague Yves Trudeau.
But Oracle in MySQL 8.0.22 introduced the Asynchronous failover feature. In this blog I am going to check if this feature is enough to cover what we need to avoid using external movable/custom script or if instead there is still work to do.
My scenario is the following:
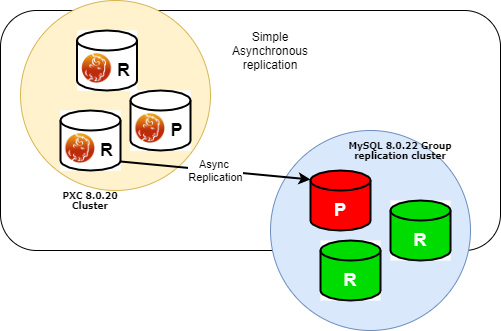
I have a PXC 8.0.20 cluster on DC1 and I am going to replicate towards a Group Replication cluster 8.0.22.
First, I need to establish the replication, to do so I follow the standard steps:
- Take a backup from one PXC node
- Copy over to DC2 and have a SINGLE MySQL 8.0.22 node start.
- Once all the internal upgrades are done, I am ready to create the Group Replication cluster as for https://dev.mysql.com/doc/refman/8.0/en/group-replication-deploying-in-single-primary-mode.html
Once I am up and running and have a situation like this:
[code]+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| group_replication_applier | 38809616-e149-11ea-b0cc-080027d0603e | gr1 | 3306 | ONLINE | PRIMARY | 8.0.22 |
| group_replication_applier | 959cc074-e14b-11ea-b90c-080027d0603e | gr2 | 3306 | ONLINE | SECONDARY | 8.0.22 |
| group_replication_applier | a56b38ec-e14b-11ea-b9ce-080027d0603e | gr3 | 3306 | ONLINE | SECONDARY | 8.0.22 |
| group_replication_applier | b7039e3b-f744-11ea-854c-08002734ed50 | gr4 | 3306 | ONLINE | SECONDARY | 8.0.22 |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+[/code]
Then I am ready to create the replication channel.
To do so I am first doing keeping the OLD style without Auto-failover. To do so:
On one of the PCX nodes:
Create user replica_dc@’192.168.4.%’ identified by ‘secret’;
Grant REPLICATION SLAVE on *.* to replica_dc@’192.168.4.%’;On the PRIMARY of my Grou Replication cluster:
CHANGE MASTER to
master_user='<user>',
master_password='<secret>',
master_host='192.168.4.22',
master_auto_position=1,
source_connection_auto_failover=0,
master_retry_count=6,
master_connect_retry=10
for channel "dc1_to_dc2";
A brief explanation about the above:
- source_connection_auto_failover=0, <--This enable/disable auto-failover
- master_retry_count=6, <-- The number of attempts
- master_connect_retry=10 <-- Specifies the interval between reconnection attempts
Once Replication is up, we will have this scenario:
Now in case of a crash of the PXC node from which I replicate for, my Group replication cluster will stop replicating:
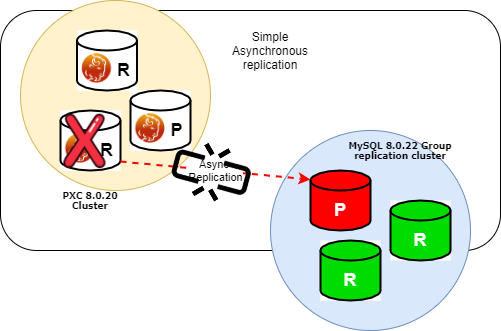
To prevent this to happen I will use the new functionality to allow Asynchronous replication failover.
To do so the first thing I have to do is to add the list of possible SOURCE in the new table that is locate in MySQL (mysql.replication_asynchronous_connection_failover), to do it I don’t need to use an insert command but instead a function:
asynchronous_connection_failover_add_source(channel, host, port, network_namespace, weight)
where:
- channel: The replication channel for which this replication source server is part of the source list.
- host: The host name for this replication source server.
- port: The port number for this replication source server.
- network_namespace: The network namespace for this replication source server (when specified).
- weight: The priority of this replication source server
In my case I will have:
SELECT asynchronous_connection_failover_add_source('dc1_to_dc2', '192.168.4.22', 3306, null, 100);
SELECT asynchronous_connection_failover_add_source('dc1_to_dc2', '192.168.4.23', 3306, null, 80);
SELECT asynchronous_connection_failover_add_source('dc1_to_dc2', '192.168.4.233', 3306, null, 50);
Now, and this is important, given the information is located in a table in the mysql.schema , the information present in the Primary is automatically replicated all over the cluster. Given that all nodes SEE the list of potential Source.
But given we are running our Group Replication cluster in Single Primary mode we can have only the Primary acting as REPLICA, because only the Primary can write. Hope that is clear.
To activate the failover we just need to pass the command:
First let us check the status:
SELECT CHANNEL_NAME, SOURCE_CONNECTION_AUTO_FAILOVER FROM performance_schema.replication_connection_configuration where CHANNEL_NAME = 'dc1_to_dc2';
+--------------+---------------------------------+
| CHANNEL_NAME | SOURCE_CONNECTION_AUTO_FAILOVER |
+--------------+---------------------------------+
| dc1_to_dc2 | 0 |
+--------------+---------------------------------+
Ok all good I can activate the auto_failover:
stop slave for channel 'dc1_to_dc2';
CHANGE MASTER TO source_connection_auto_failover=1 for channel "dc1_to_dc2";
start slave for channel 'dc1_to_dc2';
SELECT CHANNEL_NAME, SOURCE_CONNECTION_AUTO_FAILOVER FROM performance_schema.replication_connection_configuration where CHANNEL_NAME = 'dc1_to_dc2';
+--------------+---------------------------------+
| CHANNEL_NAME | SOURCE_CONNECTION_AUTO_FAILOVER |
+--------------+---------------------------------+
| dc1_to_dc2 | 1 |
+--------------+---------------------------------+
Perfect all is running, and this is my layout now:
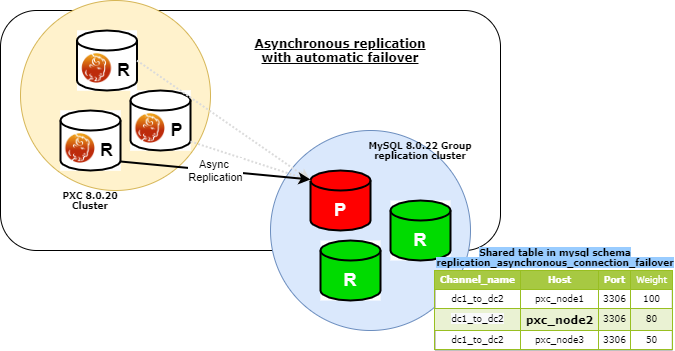
At this point if something happens to my current SOURCE the auto-failover will be triggered, and I should see my GR Primary move to the other node.
After I kill the pxc_node2 the error log of the primary will present:
[ERROR] [MY-010584] [Repl] Slave I/O for channel 'dc1_to_dc2': error reconnecting to masterThis email address is being protected from spambots. You need JavaScript enabled to view it. :3306' - retry-time: 10 retries: 1 message: Can't connect to MySQL server on '192.168.4.23' (111), Error_code: MY-002003 ... [ERROR] [MY-010584] [Repl] Slave I/O for channel 'dc1_to_dc2': error reconnecting to masterThis email address is being protected from spambots. You need JavaScript enabled to view it. :3306' - retry-time: 10 retries: 6 message: Can't connect to MySQL server on '192.168.4.23' (111), Error_code: MY-002003 [System] [MY-010562] [Repl] Slave I/O thread for channel 'dc1_to_dc2': connected to masterThis email address is being protected from spambots. You need JavaScript enabled to view it. :3306',replication started in log 'FIRST' at position 53656167 [Warning] [MY-010549] [Repl] The master's UUID has changed, although this should not happen unless you have changed it manually. The old UUID was 28ae74e9-12c7-11eb-8d57-08002734ed50.
The Primary identify the SOURCE failed, try N time as asked waiting for each try T seconds. After that it try to change the master choosing it form the given list. If we use a different weight value, the node that will be elected will be the active one with the highest weight value.
Once a node is elected as SOURCE, the replication channel WILL NOT fail back also if a node with higher weight value will become available. The replication SOURCE change only if there is a failure in the communication between SOURCE-REPLICA pair.
This is what I have now:
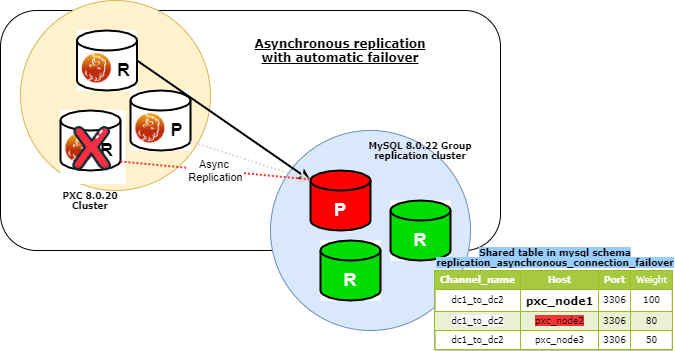
Is this enough?
Well let us say that we are very close, but no this is not enough.
Why?
Because this cover ONLY a side of the picture. Which is the REPLICA node able to change the SOURCE. But if we are talking of a cluster like Group Replication, we need to have a mechanism that will allow the CLUSTER (and not only the single node) to fail-over.
What does it mean?
Here I mean that IF the Primary fails (remember only a Primary can become a REPLICA because only a Primary can write), another Primary will be elected by the cluster, and I would expect that if my previous Primary was replicating from a SOURCE, then the new one will do the same starting from the last valid applied position.
I am sure Oracle had already identified this as a possible issue, given to me this new feature sounds something done to make the architecture based on MySQL more resilient. As such the above looks like the most logic step forward when thinking to Tightly Coupled cluster like Group Replication.
Summary of commands
Set the source:
change master to master_user='replica_dc', master_password=<secret>, master_host='192.168.4.22', master_auto_position=1, source_connection_auto_failover=0, master_retry_count=6, master_connect_retry=10 for channel "dc1_to_dc2";Set the list:
SELECT asynchronous_connection_failover_add_source('dc1_to_dc2', '192.168.4.22', 3306, null, 100);
SELECT asynchronous_connection_failover_add_source('dc1_to_dc2', '192.168.4.23', 3306, null, 80);
SELECT asynchronous_connection_failover_add_source('dc1_to_dc2', '192.168.4.233', 3306, null, 50);Delete an entry from the list
SELECT asynchronous_connection_failover_delete_source('dc1_to_dc2', '192.168.4.22', 3306, '');Check if a replication channel is using automatic failover:
SELECT CHANNEL_NAME, SOURCE_CONNECTION_AUTO_FAILOVER FROM performance_schema.replication_connection_configuration where CHANNEL_NAME = 'dc1_to_dc2';To change the SOURCE setting:
stop slave for channel 'dc1_to_dc2';
CHANGE MASTER TO source_connection_auto_failover=1 for channel "dc1_to_dc2";
start slave for channel 'dc1_to_dc2';
Conclusions
This is a very nice feature that will significantly increase the architecture resilience when using asynchronous replication in the architecture.
Still I think we need to wait to have it fully cover what is needed. This is a great first step but not enough, we still must manage the replication if a node in the REPLICA cluster fails.
I really hope we will see the evolution of that soon.
In the meantime, GREAT WORK MySQL/Oracle team, really!!
References
https://dev.mysql.com/doc/refman/8.0/en/replication-functions-source-list.html
https://www.slideshare.net/marcotusa/best-practicehigh-availabilitysolutiongeodistributedfinal
https://github.com/y-trudeau/Mysql-tools/tree/master/PXC
https://dev.mysql.com/doc/refman/8.0/en/change-master-to.html