Where x is >= 22 ;)
The Problem
There are few things your data does not like. One is water and another is fire. Well, guess what:

If you think that everything will be fine after all, take a look:

Given my ISP had part of its management infrastructure on OVH, they had been impacted by the incident.
As you can see from the highlight, the ticket number in three years changes very little (2k cases) and the date jumps from 2018 to 2021. On top of that, I have to mention I had opened several tickets the month before that disappeared.
So either my ISP was very lucky and had very few cases in three years and sent all my tickets to /dev/null... or they have lost THREE YEARS of data.
Let us go straight to the chase; they have lost their data, period.
After the fire at the OVH, these guys did not have a good backup to use for data restoring and did not even have a decent Disaster Recovery solution. Their platform remained INACCESSIBLE for more than five days, during which they also lost visibility of their own network/access point/clients and so on.
Restoring data has brought them back online, but it takes them more than a month to review and fix the internal management system and bring the service back to acceptable standards. Needless to say, complaints and more costly legal actions had been raised against them.
All this because they missed two basic Best Practices when designing a system:
- Good backup/restore procedure
- Always have a Disaster Recovery solution in place
Yeah, I know... I should change ISP.
Anyhow, a Disaster Recovery (DR) solution is a crucial element in any production system. It is weird we still have to cover this in 2021, but apparently, it still is something being underestimated that requires our attention.
This is why in this (long) article, I will illustrate how to implement another improved DR solution utilizing Percona Server for MySQL and standard MySQL features as group replication and asynchronous replication automatic failover (AAF).
Asynchronous Replication Automatic Failover
I have already covered the new MySQL feature here (http://www.tusacentral.net/joomla/index.php/mysql-blogs/227-mysql-asynchronous-source-auto-failover) but let us recap.
From MySQL 8.0.22 and Percona Server for MySQL 8.0.22 you can take advantage of AAF when designing distributed solutions. What does this mean?
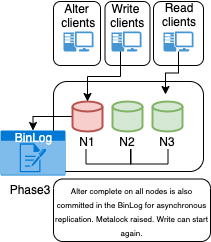
When using simple Async-replication you have this:

Whereas, a Highly Available (HA) solution in DC2 is pulling data out from another HA solution in DC1 with the relation 1:1, meaning the connection is one node against another node.
If you have this:

Your data replication is interrupted and the two DCs diverge. Also you need to manually (or by script) recover the interrupted link. With AAF you can count on a significant improvement:

The link now is NOT 1:1, but a node in DC2 can count on AAF to recover the link on the other remaining nodes:

If a node in the DC2 (the replica side) fails, then the link is broken again and it requires manual intervention. This solves a quite large chunk of problems, but it does not fix all, as I mentioned in the article above.

If a node in the DC2 (the replica side) fails, then the link is broken again and it requires manual intervention.
GR Failover
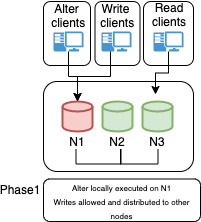
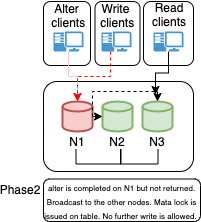
I was hoping to have this fixed in MySQL 8.0.23, but unfortunately, it is not. So I decided to develop a Proof Of Concept and see if it would fix the problem, and more importantly what needs to be done to do it safely.
The result is a very basic (and I need to refine the code) Stored Procedure called grfailover, which manages the shift between primaries inside a Group Replication cluster:

I borrowed the concept from Yves' Replication Manager for Percona XtraDB Cluster (https://github.com/y-trudeau/Mysql-tools/tree/master/PXC), but as we will see for GR and this use we need much less.
Why Can This Be a Simplified Version?
Because in GR we already have a lot of information and we also have the autofailover for async replication. Given that, what we need to do is only manage the start/stop of the Replica. Auto-failover will take care of the shift from one source to the other, while GR will take care of which node should be the preferred Replica (Primary on replica site).
In short, the check just needs to see if the node is a Primary, and if so, start the replication if it is not already active while eventually stopping it if the node IS NOT a primary.
We can also maintain a table of what is going on, to be sure that we do not have two nodes replicating at the same time.
The definition will be something like this:
+--------------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+---------------+------+-----+---------+-------+
| server_uuid | char(36) | NO | PRI | NULL | |
| HOST | varchar(255) | NO | | NULL | |
| PORT | int | NO | | 3306 | |
| channel_name | varchar(100) | NO | | NULL | |
| gr_role | varchar(30) | NO | | NULL | |
| STATUS | varchar(50) | YES | | NULL | |
| started | timestamp(6) | YES | | NULL | |
| lastupdate | timestamp(6) | YES | | NULL | |
| active | tinyint | YES | | 0 | |
| COMMENT | varchar(2000) | YES | | NULL | |
+--------------+---------------+------+-----+---------+-------+
The full code can be found in GitHub here: https://github.com/Tusamarco/blogs/tree/master/asyncAutoFailOver.
How-To
The first thing you need to do is deploy Percona Server Distribution for MySQL (8.0.22 or greater) using Group Replication as a HA solution. To do so, refer to the extensive guide here: Percona Distribution for MySQL: High Availability with Group Replication Solution.
Once you have it running on both DCs, you can configure AAF on both DCs Primary node following either MySQL 8.0.22: Asynchronous Replication Automatic Connection (IO Thread) Failover or this MySQL Asynchronous SOURCE auto failover.
Once you have the AAF replication up and running, it is time for you to create the procedure and the management table in your DC-Source Primary.
First of all, be sure you have a `percona` schema, and if not, create it:
Create schema percona;
Then create the table:
CREATE TABLE `group_replication_failover_manager` (
`server_uuid` char(36) NOT NULL,
`HOST` varchar(255) NOT NULL,
`PORT` int NOT NULL DEFAULT '3306',
`channel_name` varchar(100) NOT NULL,
`gr_role` varchar(30) NOT NULL,
`STATUS` varchar(50) DEFAULT NULL,
`started` timestamp(6) NULL DEFAULT NULL,
`lastupdate` timestamp(6) NULL DEFAULT NULL,
`active` tinyint DEFAULT '0',
`COMMENT` varchar(2000) DEFAULT NULL,
PRIMARY KEY (`server_uuid`)
) ENGINE=InnoDB;
Last, create the procedure. Keep in mind you may need to change the DEFINER or simply remove it. The code will be replicated on all nodes. To be sure, run the command below on all nodes:
select ROUTINE_SCHEMA,ROUTINE_NAME,ROUTINE_TYPE from information_schema.ROUTINES where ROUTINE_SCHEMA ='percona' ;
+----------------+--------------+--------------+
| ROUTINE_SCHEMA | ROUTINE_NAME | ROUTINE_TYPE |
+----------------+--------------+--------------+
| percona | grfailover | PROCEDURE |
+----------------+--------------+--------------+
You should get something as above.
If not, then check your replication, something probably needs to be fixed. If instead, it all works out, this means you are ready to go.
To run the procedure you can use any kind of approach you like, the only important thing is that you MUST run it FIRST on the current PRIMARY node of each DCs.
This is because the PRIMARY node must be the first one to register in the management table. Personally, I like to run it from cron when in “production” while manually when testing:
IE:/opt/mysql_templates/PS-8P/bin/mysql -h 127.0.0.1 -P 3306 -D percona -e "call grfailover(5,\"dc2_to_dc1\");"
Where:
- grfailover is the name of the procedure.
- 5 is the timeout in minutes after which the procedure will activate the replication in the Node.
- dc2_to_dc1 Is the name of the channel in the current node, the procedure needs to manage.
Given two clusters as:
DC1-1(root@localhost) [(none)]>SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| group_replication_applier | e891d1b4-9793-11eb-92ac-08002734ed50 | gr3 | 3306 | ONLINE | SECONDARY | 8.0.23 |
| group_replication_applier | ebff1ab8-9793-11eb-ba5f-08002734ed50 | gr1 | 3306 | ONLINE | SECONDARY | 8.0.23 |
| group_replication_applier | f47df54e-9793-11eb-a60b-08002734ed50 | gr2 | 3306 | ONLINE | PRIMARY | 8.0.23 |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
DC2-2(root@localhost) [percona]>SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| group_replication_applier | 79ede65d-9797-11eb-9963-08002734ed50 | gr4 | 3306 | ONLINE | SECONDARY | 8.0.23 |
| group_replication_applier | 7e214802-9797-11eb-a0cf-08002734ed50 | gr6 | 3306 | ONLINE | PRIMARY | 8.0.23 |
| group_replication_applier | 7fddf04f-9797-11eb-a193-08002734ed50 | gr5 | 3306 | ONLINE | SECONDARY | 8.0.23 |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
If you query the management table after you have run the procedure ONLY on the two Primaries:
>select * from percona.group_replication_failover_manager order by host\G
*************************** 1. row ***************************
server_uuid: f47df54e-9793-11eb-a60b-08002734ed50
HOST: gr2
PORT: 3306
channel_name: dc2_to_dc1
gr_role: PRIMARY
STATUS: ONLINE
started: 2021-04-08 10:22:40.000000
lastupdate: 2021-04-08 10:22:53.000000
active: 1
COMMENT: Just inserted
*************************** 2. row ***************************
server_uuid: 7e214802-9797-11eb-a0cf-08002734ed50
HOST: gr6
PORT: 3306
channel_name: dc1_to_dc2
gr_role: PRIMARY
STATUS: ONLINE
started: 2021-04-08 09:17:50.000000
lastupdate: 2021-04-08 09:17:50.000000
active: 1
COMMENT: Just inserted
Given the replication link was already active, the nodes will report only “Just Inserted” in the comment.
While if one of the two channels was down and the node NOT deactivated (set the active flag in the management table to 0), the comment will change to “COMMENT: REPLICA restarted for the channel <channel name>”
At this point, you can run the procedure also on the other nodes and after that, if you query the table by channel:
DC1-1(root@localhost) [(none)]>select * from percona.group_replication_failover_manager where channel_name ='dc2_to_dc1' order by host\G
*************************** 1. row ***************************
server_uuid: ebff1ab8-9793-11eb-ba5f-08002734ed50
HOST: gr1
PORT: 3306
channel_name: dc2_to_dc1
gr_role: SECONDARY
STATUS: ONLINE
started: NULL
lastupdate: NULL
active: 1
COMMENT: Just inserted
*************************** 2. row ***************************
server_uuid: f47df54e-9793-11eb-a60b-08002734ed50
HOST: gr2
PORT: 3306
channel_name: dc2_to_dc1
gr_role: PRIMARY
STATUS: ONLINE
started: 2021-04-08 10:22:40.000000
lastupdate: 2021-04-08 10:22:53.000000
active: 1
COMMENT: REPLICA restarted for the channel dc2_to_dc1
*************************** 3. row ***************************
server_uuid: e891d1b4-9793-11eb-92ac-08002734ed50
HOST: gr3
PORT: 3306
channel_name: dc2_to_dc1
gr_role: SECONDARY
STATUS: ONLINE
started: NULL
lastupdate: NULL
active: 1
COMMENT: Just inserted
3 rows in set (0.00 sec)
What happens if I now change my Primary, or if the Primary goes down? Well let say we “just” shift our PRIMARY:
stop slave for channel 'dc2_to_dc1';SELECT group_replication_set_as_primary('ebff1ab8-9793-11eb-ba5f-08002734ed50');
Query OK, 0 rows affected, 1 warning (0.01 sec)
+--------------------------------------------------------------------------+
| group_replication_set_as_primary('ebff1ab8-9793-11eb-ba5f-08002734ed50') |
+--------------------------------------------------------------------------+
| Primary server switched to: ebff1ab8-9793-11eb-ba5f-08002734ed50 |
+--------------------------------------------------------------------------+
Please note that given I have an ACTIVE replication channel, to successfully shift the primary, I MUST stop the replication channel first.
C1-2(root@localhost) [percona]>DC1-2(root@localhost) [percona]>SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| group_replication_applier | e891d1b4-9793-11eb-92ac-08002734ed50 | gr3 | 3306 | ONLINE | SECONDARY | 8.0.23 |
| group_replication_applier | ebff1ab8-9793-11eb-ba5f-08002734ed50 | gr1 | 3306 | ONLINE | PRIMARY | 8.0.23 |
| group_replication_applier | f47df54e-9793-11eb-a60b-08002734ed50 | gr2 | 3306 | ONLINE | SECONDARY | 8.0.23 |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
Reading the management table we will see that grFailOver had started the shift:
DC1-1(root@localhost) [(none)]>select * from percona.group_replication_failover_manager where channel_name ='dc2_to_dc1' order by host\G
*************************** 1. row ***************************
server_uuid: ebff1ab8-9793-11eb-ba5f-08002734ed50
HOST: gr1
PORT: 3306
channel_name: dc2_to_dc1
gr_role: PRIMARY
STATUS: ONLINE
started: NULL
lastupdate: NULL
active: 1
COMMENT: Need to wait 5 minutes, passed: 0
*************************** 2. row ***************************
server_uuid: f47df54e-9793-11eb-a60b-08002734ed50
HOST: gr2
PORT: 3306
channel_name: dc2_to_dc1
gr_role: PRIMARY
STATUS: ONLINE
started: 2021-04-08 10:22:40.000000
lastupdate: 2021-04-08 10:22:53.000000
active: 1
COMMENT: REPLICA restarted for the channel dc2_to_dc1
*************************** 3. row ***************************
server_uuid: e891d1b4-9793-11eb-92ac-08002734ed50
HOST: gr3
PORT: 3306
channel_name: dc2_to_dc1
gr_role: SECONDARY
STATUS: ONLINE
started: NULL
lastupdate: NULL
active: 1
COMMENT: Just inserted
Checking the new PRIMARY node gr1, we can see that:
- Gr_role is PRIMARY
- COMMENT reports the countdown (in minutes) the node waits
After the 5 minutes:
DC1-1(root@localhost) [(none)]>select * from percona.group_replication_failover_manager where channel_name ='dc2_to_dc1' order by host\G
*************************** 1. row ***************************
server_uuid: ebff1ab8-9793-11eb-ba5f-08002734ed50
HOST: gr1
PORT: 3306
channel_name: dc2_to_dc1
gr_role: PRIMARY
STATUS: ONLINE
started: 2021-04-08 10:27:54.000000
lastupdate: 2021-04-08 10:30:12.000000
active: 1
COMMENT: REPLICA restarted for the channel dc2_to_dc1
*************************** 2. row ***************************
server_uuid: f47df54e-9793-11eb-a60b-08002734ed50
HOST: gr2
PORT: 3306
channel_name: dc2_to_dc1
gr_role: SECONDARY
STATUS: ONLINE
started: NULL
lastupdate: NULL
active: 1
COMMENT: Resetted by primary node ebff1ab8-9793-11eb-ba5f-08002734ed50 at 2021-04-08 10:27:53
*************************** 3. row ***************************
server_uuid: e891d1b4-9793-11eb-92ac-08002734ed50
HOST: gr3
PORT: 3306
channel_name: dc2_to_dc1
gr_role: SECONDARY
STATUS: ONLINE
started: NULL
lastupdate: NULL
active: 1
COMMENT: Just inserted
Now, what we can see is:
- Node gr1 had become active in replicating
- It reports the time it started the replication
- It reports the last time it checked for the replication to be active
- Node gr2 is marked SECONDARY
- In the comment is also reported the time and when the replication was restarted on the new REPLICA node
If for any reason the replication in the original node gr2 was restarted (like moving back the PRIMARY) while the countdown was still in place, grFailOver will stop any action and reset the gr1 status.
In short, now my two DCs can rely on AAF for failing over on a different SOURCE and on grFailOver for shifting the Node following GR Primary, or to failover to another node when my Primary crashes.
Conclusion
I am sure Oracle is backing something about this and I am sure we will see it out soon, but in the meantime, I have to say that this simple solution works. It has improved the resiliency of my testing architecture A LOT.
And while I am still testing it and I am totally confident that the procedure can be written in a more efficient way, I am also sure bugs and errors are around the corner.
BUT, this was a POC and I am happy with the outcome. This proves it is not so difficult to make better what we have, and also proves that sometimes a small thing can have a HUGE impact.
It also proves we should not always wait for others to do what is required and that ANYONE can help.
Finally, as mentioned above, this is a POC solution, but no one prevents you to start from it and make it a production solution, as my colleague Yves did for his Percona XtraDB Cluster Replication Manager.
Is just on you! Great MySQL to all.
References
https://www.datacenterdynamics.com/en/news/fire-destroys-ovhclouds-sbg2-data-center-strasbourg/
http://www.tusacentral.net/joomla/index.php/mysql-blogs/227-mysql-asynchronous-source-auto-failover
https://github.com/y-trudeau/Mysql-tools/tree/master/PXC
https://www.percona.com/blog/2020/10/26/mysql-8-0-22-asynchronous-replication-automatic-connection-io-thread-failover/