Sakila, Where Are You Going?
This article is in large part the same of what I have published in the Percona blog. However I am reproposing it here given it is the first some other benchmarking exercise that I am probably going to present here in an extended format, while it may be more concise in other platforms.
In any case why this tests.
I am curious, and I do not like (at all) what is happening around MySQL and MariaDB, never like it, but now is really think is time to end this negative trend, that is killing not only the community, but the products as well.
The tests
Assumptions
There are many ways to run tests, and we know that results may vary depending on how you play with many factors, like the environment or the MySQL server settings. However, if we compare several versions of the same product on the same platform, it is logical to assume that all the versions will have the same “chance” to behave well or badly unless we change the MySQL server settings.
Because of this, I ran the tests ON DEFAULTS, with the clear assumption that if you release your product based on the defaults, that implies you had tested with them and consider them the safest for generic use.
I also applied some modifications and ran the tests again to see how optimization would impact performance.
What tests do we run?
High level, we run two sets of tests:
- Sysbench
- TPC-C (https://www.tpc.org/tpcc/) like
The full methodology and test details can be found here, while actual commands are available:
Results
While I have executed the whole set of tests as indicated on the page, and all the results are visible here, for brevity and because I want to keep this article at a high level, I will report and cover only the Read-Write tests and the TPC-C.
This is because, in my opinion, they offer an immediate and global view of how the server behaves. They also represent the most used scenario, while the other tests are more interesting to dig into problems.
The sysbench read/write tests reported below have a lower percentage of writes ~36% and ~64% reads, where reads are point selects and range selects. TPC-C instead has an even distribution of 50/50 % between read and write operations.
Sysbench read and write tests
Test using default configurations only MySQL in different versions.
Small dataset:

Optimized configuration only MySQL:

Large dataset using defaults:

Using optimization:

The first two graphs are interesting for several reasons, but one that jumps out is that we cannot count on DEFAULTS as a starting point. Or, to be correct, we can use them as the base from which we must identify better defaults; this is also corroborated by Oracle's recent decision to modify many defaults in 8.4 (see article).
Given that I will focus on the results obtained with the optimized configs.
Now looking at the graphs above, we can see that:
- MySQL 5.7 is performing better in both cases just using defaults.
- Given bad defaults, MySQL 8.036 was not performing well in the first case; just making some adjustments allowed it to over-perform 8.4 and be closer to what 5.7 can do.
TPC-C tests
As indicated, TPC-C tests are supposed to be write-intensive, using transactions and more complex queries with join, grouping, and sorting.
I was testing the TPC-C using the most common isolation modes, Repeatable Reads, and Read Committed.
While we experienced several issues during the multiple runs, those were not consistent, mainly due to locking timeouts. Given that, while I am representing the issue presence with a blank in the graph, they are not to be considered to impact the execution trend but only represent a saturation limit.
Test using optimized configurations:

Test using optimized configurations:
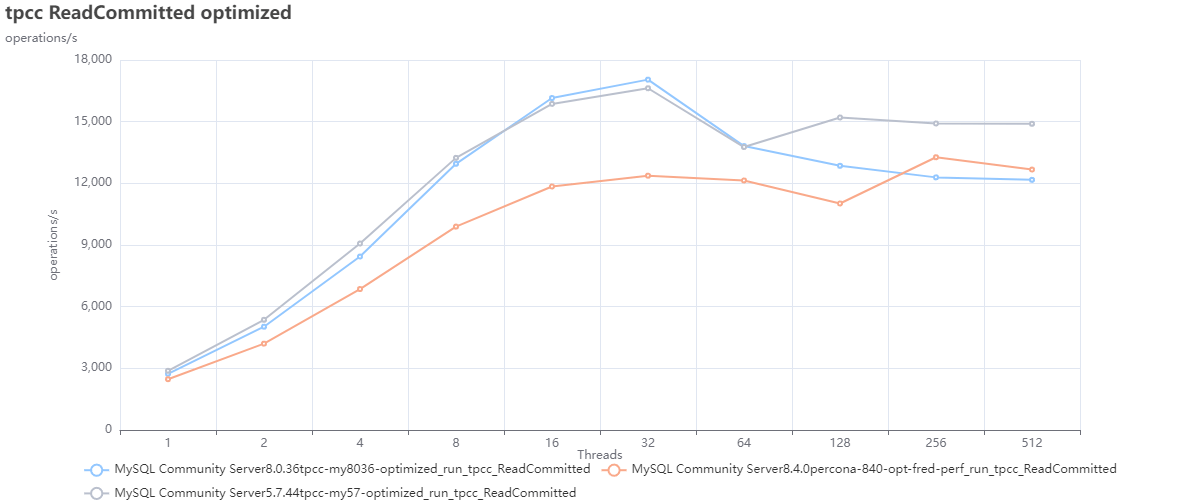
In this test we can observe that MySQL 5.7 is better performing in comparison with the other MySQL versions.
What if we compare it with Percona Server for MySQL and MariaDB?
I will present only the optimized tests here for brevity because, as I saw before, we know defaults are not serving us well.


When comparing the MYSQL versions against Percona Server for MySQL 8.0.36 and MariaDB 11.3, we see how MySQL 8.4 is doing better only in relation to MariaDB; after that, it remains behind also compared to MySQL 8.0.36.
TPC-C


As expected, MySQL 8.4 is not acting well here either, and only MariaDB is performing worse. Note how Percona Server for MySQL 8.0.36 is the only one able to handle the increased contention.
What are these tests saying to us?
Frankly speaking, what we get here is what most of our users get as well, but on their own skin. MySQL performances are degrading with the increase of versions.
For sure, MySQL 8.x comes with interesting additions; however, if you consider performance as the first and most important topic, then MySQL 8.x is not any better.
Having said this, we must say that probably most of the ones still using MySQL 5.7 (and we have thousands of them) are right. Why embark on a very risky migration and then discover that you have lost a considerable percentage in performance?
Regarding this, if we analyze the data and convert the trends into transactions/sec, we can identify the following scenarios if we compare the tests done using TPC:


As we can see, the performance degradation can be significant in both tests, while the benefits (when present) are irrelevant.
In absolute numbers:


In this scenario, we need to ask ourselves, can my business deal with such a performance drop?
Considerations
When MySQL was sold to SUN Microsystems, I was in MySQL AB. I was not happy about that move at all, and when Oracle took over SUN, I was really concerned about Oracle's possible decision to kill MySQL. I also decided to move on and join another company.
In the years after, I changed my mind, and I was supporting and promoting the Oracle/MySQL work. In many ways, I still am.
They did a great job rationalizing the development, and the code clean-up was significant. However, something did not progress with the rest of the code. The performance decrease we are seeing is the cost of this lack of progress; see also Peter's article Is Oracle Finally Killing MySQL?.
On the other hand, we need to recognize that Oracle is investing a lot in performance and functionalities when we talk of the OCI/MySQL/Heatwave offer. Only those improvements are not reflected in the MySQL code, no matter if it is Community or Enterprise.
Once more, while I consider this extremely sad, I can also understand why.
Why should Oracle continue to optimize the MySQL code for free when cloud providers such as Google or AWS use that code, optimize it for their use, make billions, and not even share the code back?
We know this has been happening for many years now, and we know this is causing a significant and negative impact on the open source ecosystem.
MySQL is just another Lego block in a larger scenario in which cloud companies are cannibalizing the work of others for their own economic return.
What can be done? I can only hope we will see a different behavior soon. Opening the code and investing in projects that will help communities such as MySQL to quickly recover the lost ground.
Let me add that while is perfectly normal in our economy to look for profit, at the end this is what capitalism is for, it is not normal, or for better say it is negative, to look for profit without keeping in mind you are burning out the resources. that gives you that profit.
This last is consumerism, using and abusing, without keeping in mind you MUST give the resources you use the time/energy/opportunity to renew and florish is stupid, short sight and suicidal.
Perfectly in line with our times isen't it?
So let say that many big names in the cloud, should seriously rethink what they are doing, not because they need to be nice. But because they will get better outcome and income helping the many opensource community instead as they are doing today, abusing them.
In the meantime, we must acknowledge that many customers/users are on 5.7 for a good reason and that until we are able to fix that, they may decide not to migrate forever or, if they must, to migrate to something else, such as Postgres.
Then Sakila will slowly and painfully die as usual for the greed of the human being, nothing new in a way, yes, but not good.

Happy MySQL to all.









