What this is about
The following is a review of the real status about Amazon RDS in comparison with EC2.
The purpose is to have a better understanding of possible limitation in the platform usage, and what is a possible fit and what not.
{autotoc enabled=yes}
Why
I did a first review an year ago for internal purpose, but now we are receiving the same questions over and over from different customers.
Given that and given a lot of things could happen in one year, I have decide to repeat the review and perform the tests once again.
What needs to be underline is that, I am doing this in consideration of a usage in PRODUCION, not as QA or development.
So my considerations are obviously focus on more demanding scenarios.
About EC2 and RDS.
Machine configuration
There are different ways that we can choose to start our EC2 or RDS, both have different cost and “virtual” physical characteristics, the list for both is below:
EC2
T1 Micro (t1.micro) Free tier eligibleUp to 2 ECUs1 Core613 MiB
M1 Small (m1.small)1 ECU1 Core1.7 GiB
M1 Medium (m1.medium)2 ECUs1 Core3.7 GiB
M1 Large (m1.large)4 ECUs2 Cores7.5 GiB
M1 Extra Large (m1.xlarge)8 ECUs4 Cores15 GiB
M3 Extra Large (m3.xlarge)13 ECUs4 Cores15 GiB
M3 Double Extra Large (m3.2xlarge)26 ECUs8 Cores30 GiB
M2 High-Memory Extra Large (m2.xlarge)6.5 ECUs2 Cores17.1 GiB
M2 High-Memory Double Extra Large (m2.2xlarge)13 ECUs4 Cores34.2 GiB
M2 High-Memory Quadruple Extra Large (m2.4xlarge)26 ECUs8 Cores68.4 GiB
C1 High-CPU Medium (c1.medium)5 ECUs2 Cores1.7 GiB
C1 High-CPU Extra Large (c1.xlarge)20 ECUs8 Cores7 GiB
High Storage Eight Extra Large (hs1.8xlarge)35 ECUs16 Cores117 GiB
RDS
Micro DB Instance: 630 MB memory, Up to 2 ECU (for short periodic bursts), 64-bit platform, Low I/O Capacity
Small DB Instance: 1.7 GB memory, 1 ECU (1 virtual core with 1 ECU), 64-bit platform, Moderate I/O Capacity
Medium DB Instance: 3.75 GB memory, 2 ECU (1 virtual core with 2 ECU), 64-bit platform, Moderate I/O Capacity
Large DB Instance: 7.5 GB memory, 4 ECUs (2 virtual cores with 2 ECUs each), 64-bit platform, High I/O Capacity
Extra Large DB Instance: 15 GB of memory, 8 ECUs (4 virtual cores with 2 ECUs each), 64-bit platform, High I/O Capacity
High-Memory Extra Large DB Instance 17.1 GB memory, 6.5 ECU (2 virtual cores with 3.25 ECUs each), 64-bit platform, High I/O Capacity
High-Memory Double Extra Large DB Instance: 34 GB of memory, 13 ECUs (4 virtual cores with 3,25 ECUs each), 64-bit platform,
High I/O CapacityHigh-Memory Quadruple Extra Large DB Instance: 68 GB of memory, 26 ECUs (8 virtual cores with 3.25 ECUs each), 64-bit platform, High I/O Capacity
Embedded features
EC2 imply that we do by ourselves the installation, setting up and maintenance of our system and Database software, but for RDS, Amazon provide few “features” that is important to keep in mind and have in mind for later discussions.
The most relevant are:
Pre-configured Parameters – Amazon RDS DB Instances are pre-configured with a sensible set of parameters and settings appropriate for the DB Instance class we select.
Monitoring and Metrics – Amazon RDS provides Amazon CloudWatch metrics for your DB Instance deployments at no additional charge. You can use the AWS Management Console to view key operational metrics for your DB Instance deployments, including compute/memory/storage capacity utilization, I/O activity, and DB Instance connections.
Automated Backups – Turned on by default, the automated backup feature of Amazon RDS enables point-in-time recovery for your DB Instance.
DB Snapshots – DB Snapshots are user-initiated backups of your DB Instance.
Multi-Availability Zone (Multi-AZ) Deployments – Amazon RDS Multi-AZ deployments provide enhanced availability and durability for Database (DB) Instances, making them a natural fit for production database workloads.
When we provision a Multi-AZ DB Instance, Amazon RDS automatically creates a primary DB instance and synchronously replicates the data to a standby instance in a different Availability Zone (AZ).
Each AZ runs on its own physically distinct, independent infrastructure, in case of an infrastructure failure (for example, instance crash, storage failure, or network disruption), Amazon RDS performs an automatic failover to the standby so that you can resume database operations as soon as the failover is complete.
Read Replicas – This replication feature makes it easy to elastically scale out beyond the capacity constraints of a single DB Instance for read-heavy database workloads. Amazon RDS uses MySQL’s native replication to propagate changes made to a source DB Instance to any associated Read Replicas.
Storage
As shown before in RDS we cannot do too much regarding the storage, we can just choose between different instances, and if we want to have provisioned IOPS.
On EC2 we obviously have both, but we also can choose how to define and use our storage solution.
MySQL configuration
Amazon presents to us the Pre-configured parameters as a cool “feature” but this is just one side of the coin. The other side is that we cannot really adjust some of the critical parameters for MySQL, or that their values are not as define in standard MySQL.
The parameters in discussion are:
binlog_format | STATEMENT expire_logs_days | 0
(calc)| innodb_buffer_pool_size | 3921674240
innodb_doublewrite | ON
innodb_file_format_max | Antelope
innodb_locks_unsafe_for_binlog | OFF
innodb_log_file_size | 134217728
innodb_log_files_in_group | 2
innodb_log_group_home_dir | /rdsdbdata/log/innodb (Max 300)
innodb_open_files | 300
max_binlog_size | 134217728 (max 4294967295)
max_join_size | 4294967295
open_files_limit | 65535
Most concerning are, the binlog format, InnoDB Log related ones.
Multi-AZ implementation
From the architectural point of view, I do not have a clear way of HOW the Multi-AZ is implemented, and I am really interested in discovering how in Amazon they have achieved the declared Synchronous replication.
I am just guessing here but some base replication using DRBD Primary/Secondary seems the most probable. What could be concerning here is the protocol level use for such replication, and level of block transmission acknowledge, given a full protocol C will be probably to expensive, also if the ONLY really safe in the case of DRBD usage. But given I don’t have clear if the solution is really using it, let me just say it will be good to have better insight.
Standard replication
We cannot use standard replication in RDS, we need to rely on Read-Replicas, or not use replication at all. The only solution is to use external solution like Continuent Tungsten (http://scale-out-blog.blogspot.ca/2013/01/replicating-from-mysql-to-amazon-rds.html).
It is important to note that RDS replication between master and Read-replica is using the STATEMENT binlog format, and it cannot be change, as direct consequence we do have inefficient replication between master and replicas for all non-deterministic statements, and in case of mixed transactions between storage engines.
Tests done
The test performed where not too intensive, and I was mainly focus on identify what will be the safe limit of usage/load for RDS in comparison to an EC2 instance properly set.
As such I have choose to use the Large Instance set for both EC2 and RDS, with 2 virtual CPU 7.5GB virtual RAM, High I/O capacity for RDS.
For EC2 the only difference will reside in the fact I perform the tests using 1 EBS for the data directory in one case, and a raid5 of 4 EBS in the other.
Also in regards of the MySQL configuration I have “standardize” the configuration of the different instance using the same parameters.
Only differences was that I was not using SSL in the MySQL EC2 instance, while it cannot be turn off in RDS because Amazon security is relying on it.
The test was using a variable number of concurrent threads:
Writing on 5 main tables and on 5 child table.
Read on main table joining 4 tables to main, filtering the results by IN clause in on test, and by RANGE in another.
The structures of the tables are the following:
mysql> DESCRIBE tbtest1; FIELD | Type | NULL | KEY | DEFAULT | Extra autoInc | bigint(11) | NO | PRI | NULL | AUTO_INCREMENT a | int(11) | NO | MUL | NULL | uuid | char(36) | NO | MUL | NULL | b | varchar(100) | NO | | NULL | c | char(200) | NO | | NULL | counter | bigint(20) | YES | | NULL | time | timestamp | NO | | CURRENT_TIMESTAMP | ON UPDATE partitionid | int(11) | NO | | 0 | strrecordtype | char(3) | YES | | NULL |
mysql> DESCRIBE tbtest_child1; FIELD | Type | NULL | KEY | DEFAULT | Extra | a | int(11) | NO | PRI | NULL | bb | int(11) | NO | PRI | NULL | AUTO_INCREMENT partitionid | int(11) | NO | | 0 | stroperation | varchar(254) | YES | | NULL | time | timestamp | NO | | CURRENT_TIMESTAMP | ON UPDATE
The filling factor for each table after the initial write was:
Table tbtest1 total 1046 least 745 bytes per char: 3
Table tbtest2 total 1046 least 745 bytes per char: 3
Table tbtest3 total 1046 least 745 bytes per char: 3
Table tbtest4 total 1046 least 745 bytes per char: 3
Table tbtest5 total 1046 least 745 bytes per char: 3
Table tbtest_child1 total 779 least 648 bytes per char: 3
Table tbtest_child2 total 779 least 648 bytes per char: 3
Table tbtest_child3 total 779 least 648 bytes per char: 3
Table tbtest_child4 total 779 least 648 bytes per char: 3
Finally the total size of the data set was of 20Gb.
The inserts were using batch approach of 50 inserts per Insert command for all the platforms.
Below the summary of the tests to run
oltp 5 + 4 table write 4 -> 32
oltp 5 + 4 table read (IN) 4 -> 32
oltp 5 + 4 table read (RANGE) 4 -> 32
oltp 5 + 4 table write/read(IN) 4 -> 32
Results
Results for write using 4 to 32 concurrent threads
Write Execution time
(High value is bad)
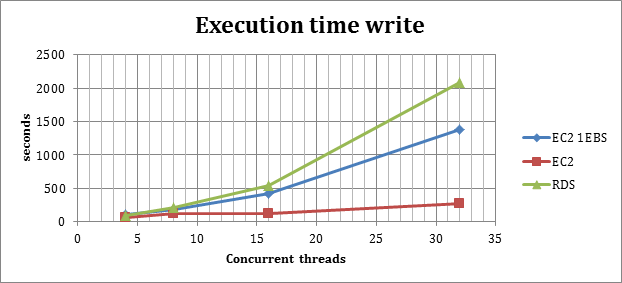
As the graph clearly shows, the behavior of the RDS and EC2 with one EBS is quite similar, while the EC2 running a RAID of EBS is maintaining good response time and scales in writes, the other two have a collapse point at 16 Threads, after which performance are becoming seriously affected.
Rows inserted
(High values is good)
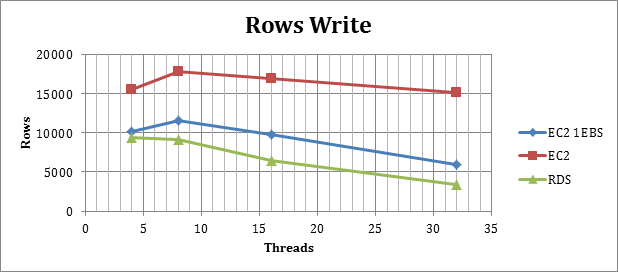
Consistently the number of Rows inserted in a defined period of time, see again the EC2 with RAID5 performing in the optimal way in relation to the other two.
During this test the performance loss starts at 8 threads, for EC2 solutions, while for the RDS solution it is with the increase of concurrency that we immediately see the performance degradation.
Select Execution time with IN
(High value is bad)
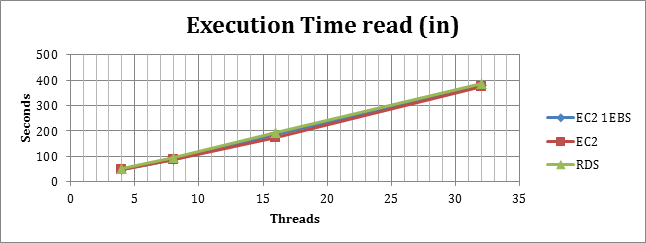
Using the select with IN given the high efficiency of the IN approach, and the reduce number of reads that require to be executed on disk, all the instance maintain a good level of performance.
Rows reads with IN
(High value is good)
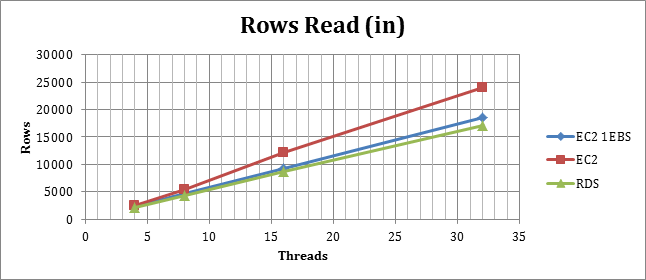
In this case all the instances are consistently performing, but the EC2 with RAID solution can serve a larger amount of requests, almost 1/3 larger then of the RDS.
Select Execution time with RANGE
(High value is bad)
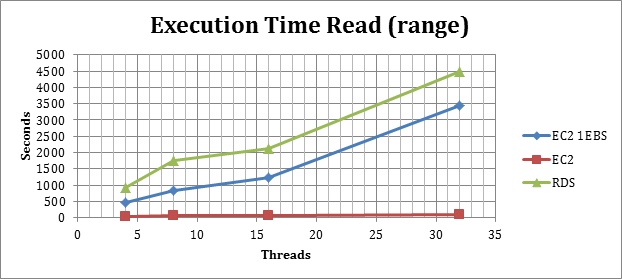
In the case of range selects and heavy access on disks, the RDS and EC2 with 1 EBS, are absolutely not able to perform at the same level of the RAID solution. This quite obviously related to the amount of data needs to be read from disks, and the limitation existing in RDS and 1 EBS solutions.
Rows reads with RANGE
(High value is good)
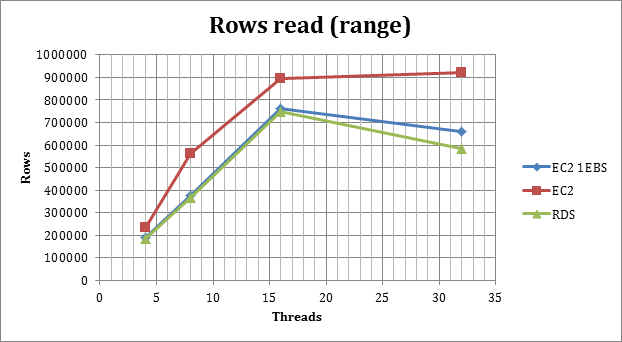
The volume test confirms and highlights the different behavior between EC2 RAID and the others, at 32 concurrent threads the RDS solution tends to collapse, while the EC2 RAID is serving successfully the traffic also if with less efficiency.
Select Execution time with mix of SELECT and INSERT
(High value is bad)
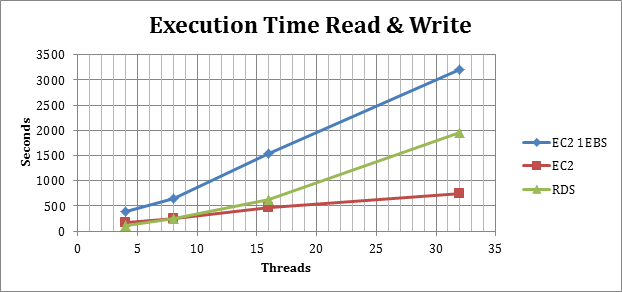
Rows reads with mix of SELECT and INSERT
(High value is good)
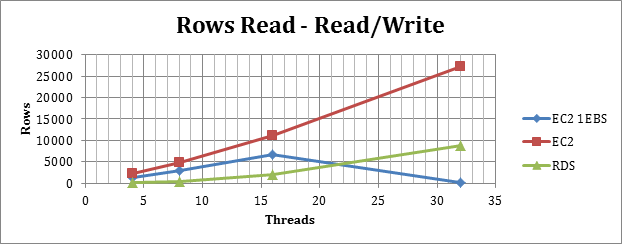
In a mix workload, I had unexpected results, with EC2 1 EBS behaving very badly when working with more then 16 threads, this given the I/O contention and possible RDS optimizations, implemented by Amazon to prevent single EBS problems.
Except that the RDS and the EC2 with RAID behave as I was expecting, with EC2 able to manage a larger volume of traffic, and the Inserts limiting the number of reads, as expected.
Conclusions
The comparison between RDS and EC2, cover several areas, from performance to High Availability.
My conviction is that RDS is not implementing a solid and trustable HA solution given the not clear way synchronous replication is implemented.
RDS is not applying correct best practices for replication given the use of STATEMENT format and the limitation existing in the replication management.
Finally RDS is not really efficient in managing large volume of traffic, or applications with a large number of highly concurrent threads.
Never the less it could be a temporary solution for very basic utilization in application that do not have demanding requirements.
RDS can probably further optimize, but I am sure it will never be enough to consider RDS production ready.
EC2 is more flexible and allow better tuning and control of the platform, multiple HA solutions and full control of replication and MySQL in general. All these define the significant difference with RDS, and draw the line for the right use of the tool.
Also there is not a difference in what kind of MySQL distribution we will implement, given that the source of the issue is on the platform.
My final advice is to use RDS for development or as temporary solution in a start-up, but it should not be use in the case of critical system or consolidated mature application, which require high available, scalable database support.
Reference
http://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/RDSFAQ.MultiAZ.html
http://scale-out-blog.blogspot.ca/2013/01/replicating-from-mysql-to-amazon-rds.html
http://www.mysqlperformanceblog.com/2011/08/04/mysql-performance-on-ec2ebs-versus-rds/
{joscommentenable}