Why
Marco, why did you write this long article?
Yes, it is long, and I know most of the people will not read it in full, but my hope is that at least someone will, and I count on them to make the wave of sanity.
Why I wrote it is simple. We write articles to share something we discover, or to share new approaches or as in this case to try to demystify and put in the right perspective the “last shining thing” that will save the world.
The “last shining thing” is the use of containers for relational databases management systems (RDBMS) and all the attached solutions like Kubernetes or similar.
Why is this a problem? The use of containers for RDBMS is not really a problem per se, but it had become a problem because it was not correctly contextualized and even more important, the model that should be used to properly design the solutions, was not reviewed and modified in respect to the classic one.
One example for all is this image:
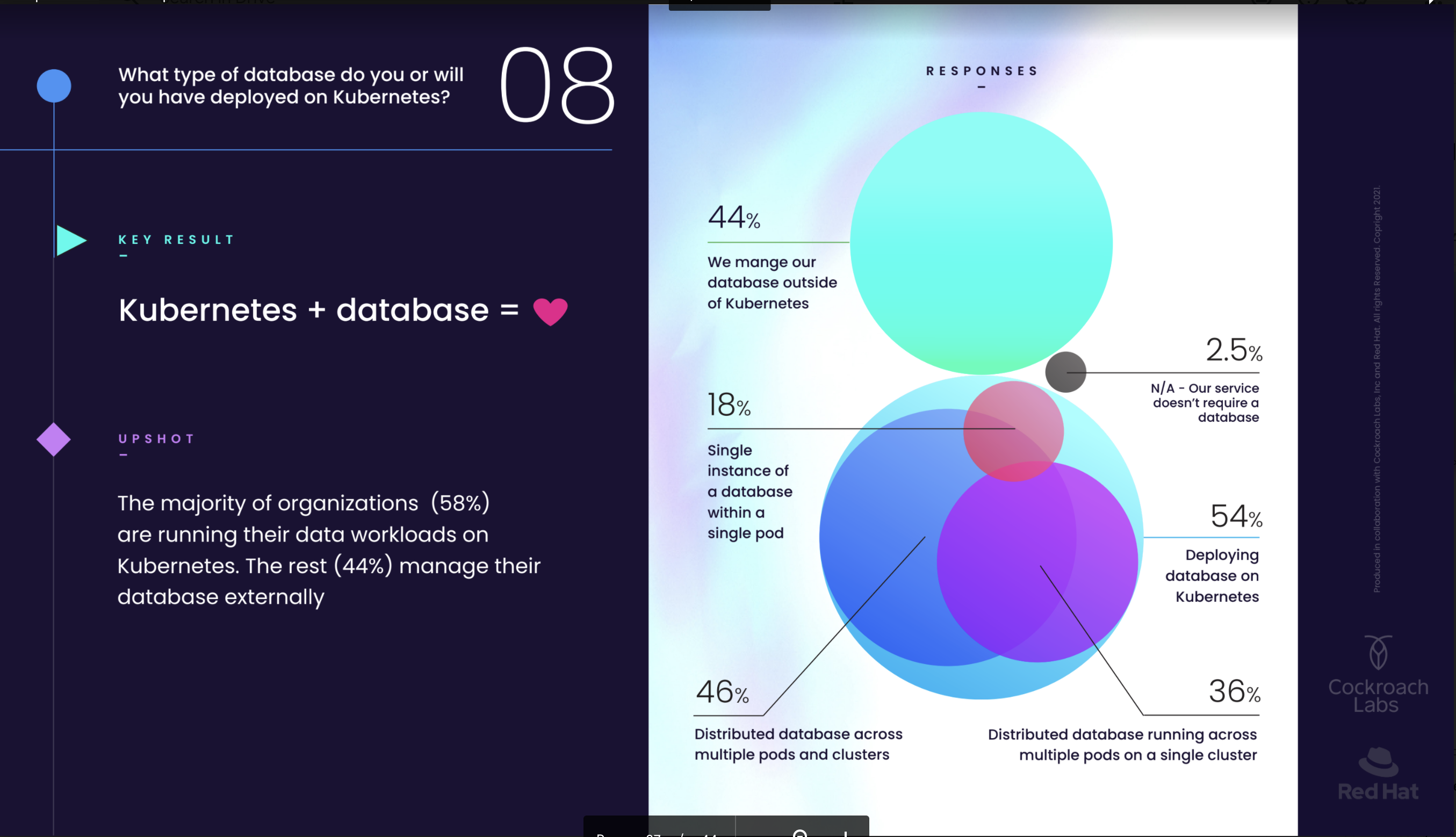
Source (https://www.cockroachlabs.com/blog/kubernetes-trends/)
In this report we find the use of the term Database multiple times, and reference how easy it is to adopt and scale a Database on Kubernetes. But the problem is … what Database? Not all the Databases are the same, not all can be adopted so easily, some use more restrictive design to be real RDBMS, others less.
Some are designed to scale horizontally, others no. The other missed part is that, to get something you need to give something. If I design a system to scale horizontally, I probably have to pay a price on something else. It could be the lack of referential integrity or the Isolation level, it doesn’t matter, but you do not get anything for free.
Generalizing without mentioning the difference is misleading.
What happens instead is that we have a lot of people, presenting solutions that are so generic that are unusable. The most hilarious thing is that they present that as an inevitable evolution, the step into the future that will solve every problem. But when doing this, they do not clarify what is the “Database” in use, what you get, what you lose. This may lead to misunderstanding and future frustration.
For instance we constantly see presentations that illustrate how easy it will be to manage hundreds, thousands of pods containing RDBMS, without even understanding the concept of RDBMS, the data they may host and its dimension.
The more we go ahead the more dangerous this disinformation is becoming, because we can say that on 100 companies currently using RDBMS to manage their crucial data, only 10 have a good team of experts that understand how to really use containers, and probably only 1 or 2 of them have real data experts that are able to redesign the data layer to be correctly utilized in containers or able to see to what proper Database to migrate to achieve the expected results.
Another common expectation is to move to container/kubernetes to reduce the costs, no matter if related to the iron (physical servers) or of the management of them.
Indeed you can optimise that part, but you need to understand the limitations of your future solution. You must take into account that you may not have the same level of service in a way or another. Honestly I haven't seen that addressed in current blogging or reports.
This is why this article. What I want to do is to open a door to a discussion, that will lead us to review the original model used to design data inside RDBMS, that will allow anyone to safely approach a different model to use for modern database design.
When
(if you know how we get here you can skip this)
To fully understand what we are talking about we need to do a jump back in time, because without history we are nothing, without memory we are lost. Just note that I am going to touch on things at a very high level and for what we are concerned, otherwise this will be a book not an article.
A long time ago in a world far far away where the internet was not, there was: client server approach.
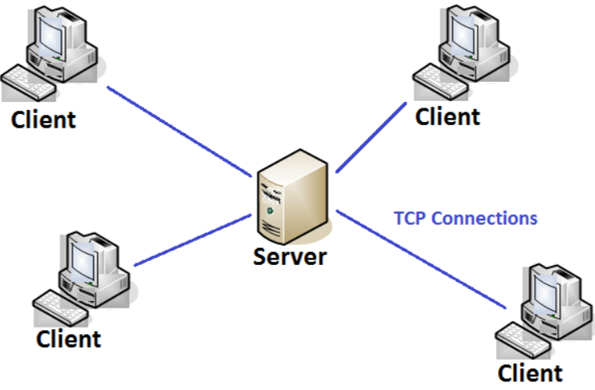
At that time we had many clients connecting to a server to provide access to whatever. Most of the clients were performing information rendering and local data validation, then they sent the information back to the application server who processed them and store… where? Well there was a high variety of containers. Some were just proprietary files with custom format, others connected to an external database. What is relevant here is that we had a very limited number of clients (often less than 1k) and at the end the amount of data in transit and then store was very small (if a database had more than 1GB data in total it was considered a monster).
Then came the internet … and many things started to change.
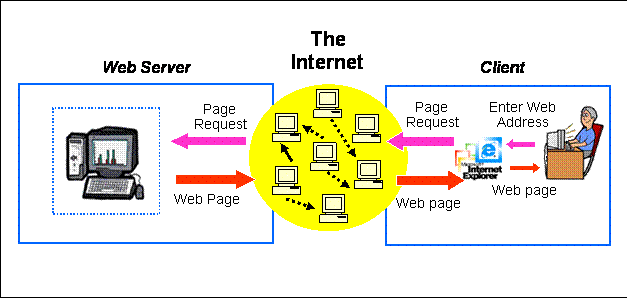
We still have a client on our PC, but now is called a web Browser, the information rendering is now standardize using SGML standards (HTML tagging), the server is not anymore a simple Application Server, but a web server who is connected to one or many application(s) using common gateway interface (CGI). Each application was then handling the data in/out independently, some using databases some not.
This new approach add to the previous model many challenges like:
- Anyone from anywhere can access the Web Server and any application hosted
- The number of requests and clients connected jump from well predictable numbers to something impossible to define.
- The connection to a web server follows a different approach based on a request issued by a browser and a set of information that will be sent as an answer from the server. (later we will have more interactive/active protocols but let us stay high ok?)
- Many application were duplicating the same functions but with different approach
- Data received and sent needs to be consistent not only locally on the server, but also between requests.
So on top of the problem generated by the number of possible clients connected and the amount of requests per second a web server was in need to process, the initial model was wasting resources in development and when running. There was the need to optimise the interactions between applications and their functions, to cover that the Service Oriented Architecture (SOA) model was largely adopted.
The data problem was partially solved identifying RDBMS as the best tool to use to guarantee the level of data consistency and at the same time it was possible to organize data in containers (tables) with validated interactions (Foreign keys and constraints) solving the online transaction processing (OLTP) problem. While for business analysis and reporting the Online analytical processing (OLAP) model was chosen. The OLAP model is based on facts and dimensions, which are elements of the data hypercube which is the base model that is utilized to first transform and then access the data.
During this time, the data as volume starts to increase significantly, most of the systems, when well designed, start to implement the concept of archiving, partitioning, and sharding.
We are around 2005-2008.
Then social media and online shopping explode...
Well we know that, right? We are still in this huge big bang of nonsense. What changed was not only that now anyone can access whatever is on a web server as certified information, but we can chat with anyone, we can buy almost anything, we can sell anything, we can make photos and share them, videos and ask anyone from anywhere to comment and we can say whatever and that crap will remain forever around.
And guess what? To do that you need a very, very, very powerful scalable platform and it should be resilient, but for real not as a joke. When we look for something today, we open our phones, we expect to have that now and no matter what. If we do not get it, we may look to a different place, like another shop, or another chat system or whatever. To achieve this you do not only need to have some specialized bloks, but to split the load in many small parts, then be able to have redundancy for each one of them, and be able to have any functional block able to connect to another functional block. Moreover, if one of the blocks goes down I must be able to retry the operation using another functional block of the same kind, and be sure I will have the same results.
To achieve this the SOA concept was evolved into the Microservice concept. But microservice also brings new challenges. One for all is how to manage these thousands of different functional bloks, and how to efficiently deploy/remove/modify them.
Interestingly the term DevOps also started to get more relevance, and automation became a crucial part of ANY environment.
In short the modern application architectures moves from Monolithic or SOA to microservice as shown here:
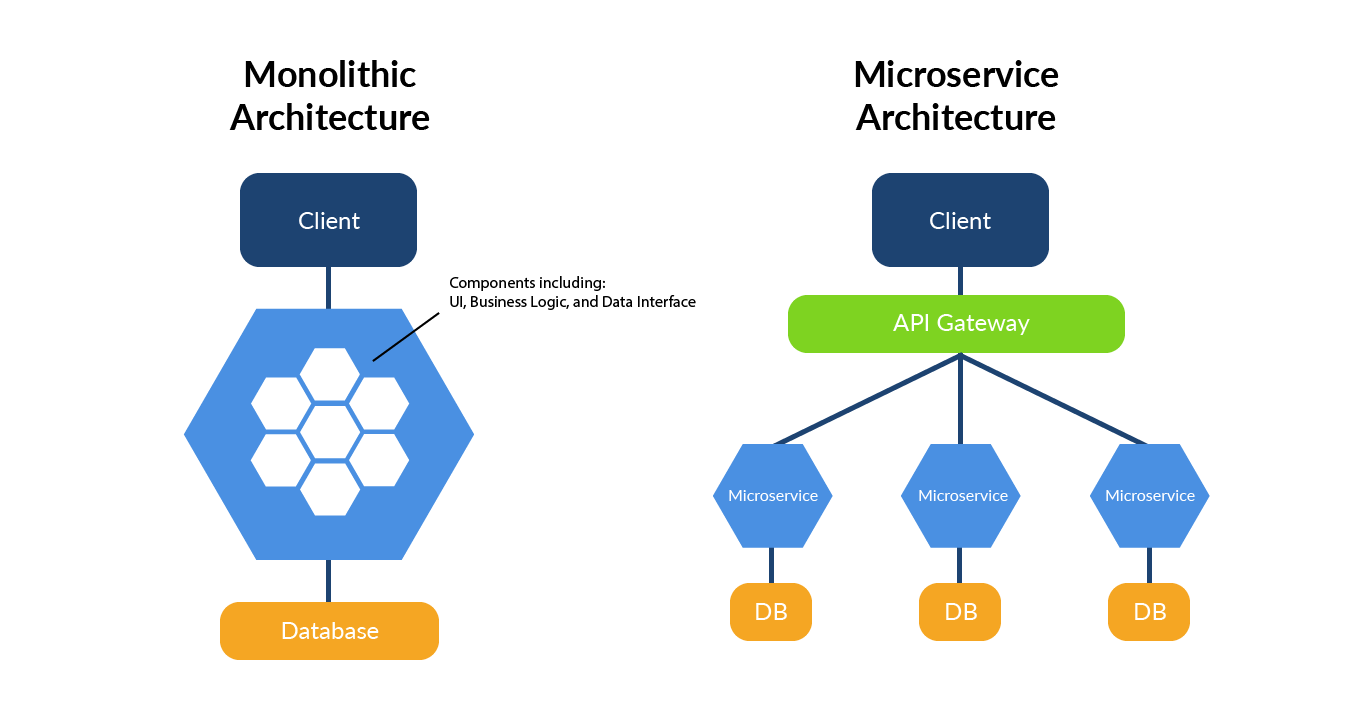
Of course reality sees each microservice block be redundant and scalable. Given that for each microservice kind we can have 1 to infinite number of instances.
It is in this context that the use of Kubernetes comes in help. Kubernetes is designed to help manage the resources as microservices, each element (pod) is seen in function of the service provided, the service will scale up and down adding/removing the pod, keeping the service resilient.
Expecting to deal with a structure like this without proper tooling/automation is just not possible:
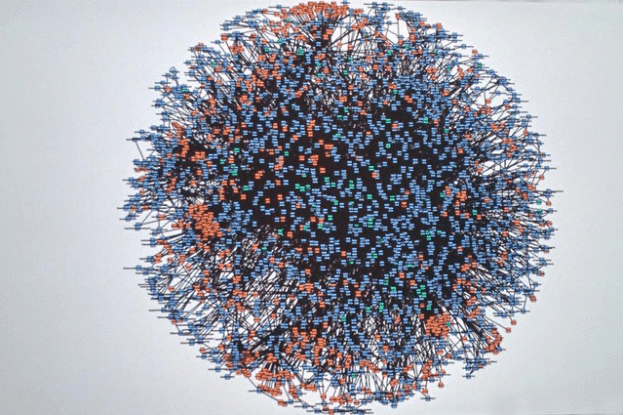
This picture represent the Amazon microservice infrastructure in 2008 https://twitter.com/Werner/status/741673514567143424
In conclusion
In short, we can say that the complex topologies we have to deal with today are the results of a needed evolution from monolithic application approach to a distributed one in services/microservices. The proliferation of which had made absolutely necessary the creation and usage of a tool to facilitate the management, reducing complexity, time to perform the operations and costs.
Cool eh? What about the database?
The first thing to say is that RDBMS as Oracle, Postgres and MySQL did not evolve in the same direction. They remain centralized structures. We have clusters but mostly to answer to High Availability needs and not scaling.
This is the part of the story, the current evangelists of the “last shining thing” are not telling you. There is no coverage for the RDBMS like Oracle, Postgres or MySQL in the microservice approach. None, zero, nich, nada!
To bypass that problem, many microservices developers implemented complex mechanisms of caching or use noSQL approaches.
Using caches to speedup the processing is absolutely ok, trying to use them instead of an ACID solution, is not. Same as the use of noSQL, if it makes sense because the service requires then ok otherwise no.
But what is the problem in seeing a RDBMS as a microservice?
Let us start with a positive thing. If you design it as a microservice and reset the expectations, then it is ok.
What benefits (pros)?
The first thought is why I should move to kubernetes/containers. What am I expecting to get more that I do not already have?
Well let see the few basic points a microservice solution should help me with in case of application:
- Modularity:
- This makes the application easier to understand, develop, test, and become more resilient to architecture erosion.
- Scalability:
- Since microservices are implemented and deployed independently of each other, i.e. they run within independent processes, they can be monitored and scaled independently.
- Better Fault Isolation for More Resilient Applications.
- With a microservices architecture, the failure of one service is less likely to negatively impact other parts of the application because each microservice runs autonomously from the others.
- Nevertheless, large distributed microservices architectures tend to have many dependencies, so developers need to protect the application from a dependency failure related shut down.
- Integration of heterogeneous and legacy systems:
- microservices is considered as a viable means for modernizing existing monolithic software applications.
- There are experience reports of several companies who have successfully replaced (parts of) their existing software with microservices, or are in the process of doing so.
- The process for Software modernization of legacy applications is done using an incremental approach.
- Faster Time to Market and “Future-Proofing”
- The pluggability of a microservices application architecture allows for easier and faster application development and upgrades. Developers can quickly build or change a microservice, then plug it into the architecture with less risk of coding conflicts and service outages. Moreover, due to the independence of each microservice, teams don’t have to worry about coding conflicts, and they don’t have to wait for slower-moving projects before launching their part of the application.
- Microservices also support the CI/CD/CD (Continuous Integration, Continuous Delivery, Continuous Deployment) development philosophy. This means that you quickly deploy the core microservices of an application – as a minimum viable product (MVP) – and continuously update the product over time as you complete additional microservices. It also means that you can respond to security threats and add new technologies as they appear. The result for the user is a “future proof” product that’s constantly evolving with the times.
Of course this is for applications let us try to map similar things for a database if it makes any sense.
- Modularity. We can have two different level of modularity:
- By service. When using by service we need to have data modules that serve the microservices who use that segment of data. IE login needs data about user login only, not information about customer orders.
- By context. When by context, we need to group as much as possible the data relevant to a specific topic. In a multitenant database we will need to separate the data such that all microservices will be able to scale accessing the data relevant to only one tenant, not all, then filtering. IE in our example above, we will have the whole schema in our service but only for one single tenant
- Scalability. To gain infinite scalability as we do for applications, we should be able to:
- Either the database service is able to perform non impacting distributed locking. What I mean here is that independently by the type of modularity used, if we need to be able to scale the number of requests/sec duplicating the service who answer the requests, we need to be able to avoid two different pods to overwrite eachother without or with minimal impact on the performance. As for today in the MySQL area we have two solutions that could cover that, PXC with galera and MySQL/PS with group replication. But both solutions have performance impact when using multiple writers. Not only, in these solutions data is not distributed by partitions, but duplicated in full for each pod. This means that unless you have a very good archiving strategy your space utilization will always be S x N (where s is the total space in one pod and N the number of pods).
Because of this, if we choose this approach, we need to keep our dataset to the minimum to reduce any locking impact and data utilization.
- Or sharding the data by pods, which means we need to have a controller able to distribute the data. Of course we need to have High Availability so we need to consider at least a copy of each node or distributed partitioning. As far as I know MySQL or Postgres don’t have this functionality, Mongo not sure.
In the end, a RDBMS microservice will not be able to scale in the same way an application microservice does.
- Better Fault Isolation for More Resilient Applications.
Well it comes without saying. If the model used is by context, the fact we will isolate the data service in smaller entities will help the resilience of the whole system. But the relationship that exists inside a schema can make the by service model more fragile, given that when 1 segment is down it will not be possible to validate the reference .
- Integration of heterogeneous and legacy systems. To be honest I can see this is possible only if modularity by service is used. Otherwise we will still have to deal with the whole structure and multiple services. In the last case I don’t see any benefit and we will have to perform operations like modifying a table definition, that can be as fast as renaming a field, or very impactful.
- Faster Time to Market and “Future-Proofing”
Indeed the divide and conquer approach especially if using the by service model will help in making each service more flexible to changes, but if by context is used, then we may have a negative effect because an application microservice may read data from N data microservices. If we change one data microservice (ie adding an index to a table), this change must be applied to all of the N microservice by context or the behaviour of the microservices will be different from the one with the change.
- Distributed development. Also in this case we need to consider it easier to achieve if modularity by service is used. Otherwise I don’t really see how it will be possible to perform any of the mentioned points that are valid for applications.
What concerns (cons)?
Now let us discuss the possible concerns.
- Services form information barriers. Well it comes without saying.
- Inter-service calls over a network have a higher cost in terms of network latency and message processing time than in-process calls within a monolithic service process. Just think about some standard maintenance work that needs to be done to consolidate the data from each service to a single location for business intelligence purposes. And keep in mind that all must be encrypted for security reasons.
- Testing and deployment are more complicated. While acting on a single module will be easier, the deployment of the full solution and its testing will become extremely complicated.
- Viewing the size of services as the primary structuring mechanism can lead to too many services when the alternative of internal modularization may lead to a simpler design. This is true when using the by service modularity, we may end up having too many fragments of data, with serious difficulties in consolidating it. And of course, we still need to know and keep an eye on what is happening on the rest of the schema used by other services.
- Two-phased commits are regarded as an anti-pattern in microservices-based architectures as this results in a tighter coupling of all the participants within the transaction. However, lack of this technology causes awkward dances which have to be implemented by all the transaction participants in order to maintain data consistency.
- Development and support of many services is more challenging if they are built with different tools and technologies. It is not uncommon to have complex applications use different data sources, like RDBMS and a document store. While the use of microservice can help in simplifying how the data is collected and handled from these different sources, the additional fragmentation leads to a significant increase of the complexity to handle the platform. To be honest, solutions as Kubernetes can help a lot here, but still an issue.
- The protocol typically used with microservices (HTTP) was designed for public-facing services, and as such is unsuitable for working internal microservices that often must be impeccably reliable. This issue applies to databases in a different way. Because we will have 2 different aspects. The first one is the application microservice connecting and reading/writing to the data microservice. These operations must use the proprietary client protocol of the RDBMS. Then the second part is when the application microservice is sharing/serving the data to others. Say I am posting a payment and a network glitch happens between application microservices. I must be able to:
- Retry the data sharing
- Rollback the operation on the database if failing
The HTTP protocol is not the best/most performant way to that given the post/get approach used.
Let me give an example to clarify this.
We are an organization who does multiple activities. We have shops all over the globe and a huge segment of my sales is online. We also organize travels and host web-stores. To deal with the traffic and load I have moved my large part of the application architecture to microservice. To provide better services to my customers I also have to differentiate my catalog by geographic regions, splitting my market into North America, Europe, Middle-East, Asia and pacific. I have data centers in each geo-zone. Each geo-zone also hosts a local data repository that is focused on the specifics of the area. Finally my sales are consolidated in two steps, first locally by geo-area, then centrally in the North America HQ. We have hundreds of database services for each segment of business, and thousands of pods of the application.
One of mine online shop that use microservices at high level looks like this for each geo-zone:
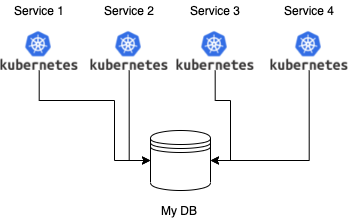
Where Service-1 can be the login of a user and its authentication, Service-2 the show/retrieval of the items in special-sales, Service-3 dealing with existing order information … and so on.
So I have specialized microservices that may serve multiple applications, like sign on, but each microservice at the moment needs to retrieve and send data from/to the same repository.
Each database contains data relevant to a specific business activity. For instance our main store data is separate from the travel data and so on. Because this the “My DB” above just represents one of many databases we have. The detailed design of it may resemble this:
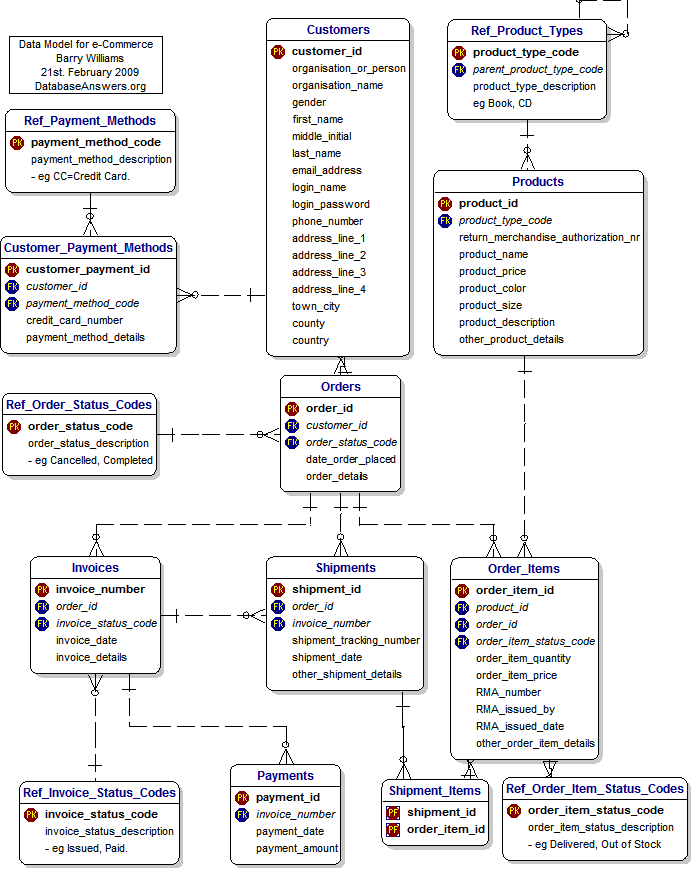
All credits for this diagram go to Barry Williams
Let us play the game, what do I need to do to convert this to a microservice?
Let us now try to apply what we have discussed so far about the expectations (pros/cons) and see if we will be able to make this fit. Given I am a MySQL expert I am going to cover the next step in the MySQL context.
Case one Modular by context
The first step is to choose the kind of modularity we want/can use. Let us start with the one which requires less changes, the module by context.
When using that approach our schema remains the same, what we do is in case of multi-tenant to make it single-tenant, then we need to see how to cover the other aspects.
The next step is scalability, and here we start to have problems. As already mentioned above there is no way to achieve the same level of scalability we have with the application layer. So what can we really do?
As mentioned in the MySQL ecosystem we have two major solutions, one is Percona XtraDB Cluster (PXC) using galera virtually synchronous replication, the other is MySQL or Percona Server with group replication (GR). We have another player here which may actually fit much better, but at the time of writing there is no container solution for it. I am talking about the MySQL NDB cluster.
Anyhow both PXC and GR allow to have Single primary (one writer) or multiple Primary (multiple writers). But the use of multi Primary is discouraged because of the loss of performance caused by the write conflict resolution. What this means is that at each commit the node receiving the writes must certify the commit against the whole cluster. The more nodes write at the same time, the more chances of conflicts will rise. Each conflict will end up with a conflict resolution and a possible rollback of the operation. All these instead adding scalability is actually impacting it and significantly reducing the performance.
On the other hand, reads can easily scale using multiple nodes. But keep in mind that the two solutions cannot really scale in number of nodes to the infinite. GR has a hard limit of nine nodes, while PXC has no hard limit, but more nodes, more latency at each write commit and more cost in maintaining the cluster, in short when you reach a cluster with 7 nodes you already start to experience significant slow down and latency.
So what level of scalability do we have here? The answer is easy, none!
Yes none, as it is you can have and will have only 1 node (pod) writing at a given time, so your level of scalability in writing is the capacity of 1 node, period.
Unless you adopt sharding. In that case you may have multiple microservice each covering one shard with a fixed number of nodes (pods). So the scaling is not internal to the microservice but in the duplication of it.
Application at this point has three ways to use this approach:
- Be shard aware and have a list of microservice to use when in the need (a shard catalog)
- Be shard aware but refer to a generalized catalog service to access the data.
- Not shard aware but pass information to the generalized catalog service to identify the shard.
The first option is not really optimal because anytime we add a shard we need to “inform/modify” the catalog in all relevant application microservice.
The second and the third assume the presence of another service dedicated to resolving the sharding.
I am not going into the details here but this can be achieved by adding a ProxySQL microservice. Such that the scenario will be:
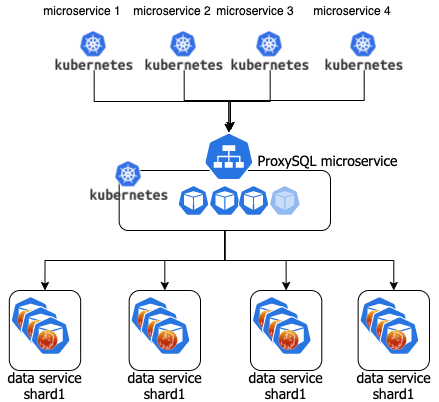
Where each data service shard is a Percona Distribution for MySQL Operator (PDMO).
Scalability is then guaranteed by adding a PDMO shard and just an entry in ProxySQL in the mysql servers and query rules.
Better Fault Isolation for More Resilient Applications. Adopting the above model will allow us to be not only more resilient in case we migrate from a multi-tenant approach, but also in case we do not. No matter what if the application is correctly written if a shard will go down only that segment will be affected.
Integration and changes will become more cumbersome given the scale of the services. This is in the model and will represent a risk in case of mistakes or improper data definition modifications. But it will be easier to roll back by shard than against the monolithic data service.
Distributed development. There will not be any advantage here, as developer or DBA I still need to consider the whole data definition scenario and not just a small segment. So while a developer can focus only on one aspect (i.e. login), a DBA still needs to take care of the whole schema and the impact of the operations (like locking) on the single table (i.e. users) for that service.
Dimension of the dataset. But here we have another important concern, at least for now. To be so agile each single service (or microservice) needs to be able to be rebuilt quickly. This means that when a pod inside a data microservice crashes the cluster needs to rebuild it as fast as possible, or the QOS (quality of service) will be impacted. As for now both PXC and GR if in need to rebuild a node must actually copy the data over the new pod. This can be very fast in case of small datasets, or take days in case of very large. Given that when we plan to use a data microservice we also need to plan/design a very efficient archiving mechanism that allows us to stay in our microservices only the data that is really needed at the moment. All the data that can be considered not actual should be moved to an OLAP system and have dedicated service to retrieve it.
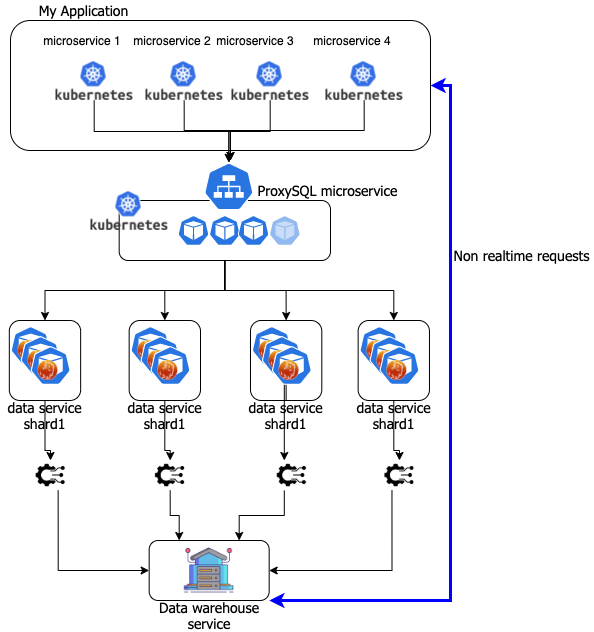
Case two modularity by service.
What modularity by service means? It means I can split the data schema definition into small segments that correspond to the services. So my data segment will be functional to the use done by the application microservices. As an example I may have microservice dealing with: Login; shipments; invoicing … and so on.
This means that in case of the invoice I should fragment the schema as follow:
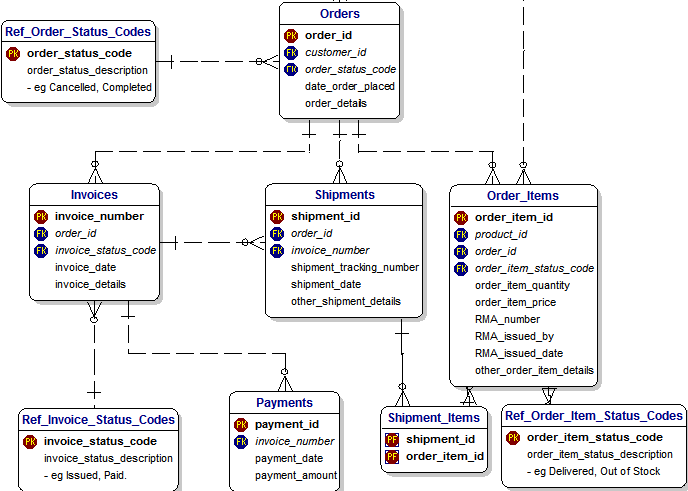
But these are the same tables I also need to serve shipments, so I must use the same data microservice, for both. This is ok … but … the question is can we? Can we split in small segments a schema that is built on relationships? Orders are linked to Customers and to products. How do we manage these referential integrity links if we start to split the schema?
Again a simple answer, we cannot. If you are using a RDBMS the R is for relational and you cannot break the model and hope to have some data integrity.
If you need that approach, then please use something else like noSQL Cassandra or similar. And then consolidate the data in the OLAP system. But do not use a RDBMS.
Given the above the by service approach, which was the one closer to give us what we need in the microsystem area, is not utilizable when talking of RDBMS. Period.
I want to move to containers/Kubernetes to rationalize the resource utilizations and lower management cost
So far we have talked about moving to containers/kubernetes as an answer to application microservices, but there is another possible need that may lead you to see containers/kubernetes as “the solution”, the need to optimize resources.
It goes without saying that if you have hundreds or more small instances of a RDBMS, sparse n many different physical servers, or also some virtualization, the move may help you. The current operators like PDMO offer you a lot of automation, to perform not only installation of the main environment, but you will be able to easily automate and manage:
- Installation
- Geographic distribution
- Backup/restore
- Point in time recovery
All this with simple commands through kubernetes.
As also indicated in my blog here, you will also be able to rationalize the resource utilization reducing the costs.
So yes, of course this can be helpful and probably you should seriously look into migrating your environment to it. But it is not for all.
Again keep in mind that Kubernetes/containers are mainly designed to work with distributed services, and when talking about resiliency, the resilient factor for kubernetes is the service, not the single pod.
What it means is that it could happen that a pod has issues and that it will be destroyed and rebuilt. If you have a pod containing stateless application, this takes seconds and has no impact on the cluster.
But if you are talking about the node of a cluster with several terabytes of data, that will impact the cluster and the service.
This is it, when dealing with large clusters and kubernetes, you may need to keep into account factors that may trigger actions, like dropping a pod, that instead require more flexibility.
A good example is when a pod starts to have temporary network glitches. In the case of PDMO with PXC, the cluster will try to heal itself at PXC level. That operation may temporarily exclude a node from the cluster, and then let it join again. This operation has a cost in performance and efficiency of the cluster itself, but normally it resolves in a few seconds.
The same network glitches can be seen from kubernetes as a pod failure, and action may be taken directly on the pod, removing it from the cluster and rebuilding a new node. That operation not only may take hours or days, but will impact on the cluster performance in a significant way until all the data is copied over from a data node to another.
The addition of kubernetes also adds the need to have additional understanding on how effectively tuning the service to prevent wrong management actions like the one described. Tuning that needs to be done in respect to the traffic served and the dimension of the dataset.
The advice here is to start small, adopt the help of experts in setting up the environment and tune it properly, gain good understanding and then start to increase the challenge. And never trust the defaults settings in the configuration files.
Wrapping up …
Given all the above.
If we are looking to containers/Kubernetes for our databases as an addition to an existing or new environment based on microservices, then the question is: Are we following evolution and really providing a benefit adopting the kubernetes/microservice approach to RDBMS?
As we have seen the move to microservice was an answer to provide better flexibility, scalability and many other *bility to the application layer.
An RDBMS is, on the other hand, a system designed to answer to the ACID paradigm, which is the core of a RDBM and the model should never be broken.
As we have seen, it is possible to create fragments and scale, but this needs to happen in getting consistent sets of data.
Sharding is one option, but it requires a lot of investment in re-design the data layer and adapting the application. It will also open a lot of new problems, including data archiving and possible/probable data redundancy. All problems that require a deep analysis and proper design before moving. Not impossible but not something you should do without preparation, care and investment in time and money.
If instead the scope is to reduce the overhead in management and resource optimization, the task is easier. The scaling factor is not there, and you are not bounding your data layer to a microservice concept. But, you still need to be careful and properly analyze the move, considering the side effects not only today, but in the long run. Questions like, how big my dataset will be in 1 year, are pivotal.
Blindly moving your database stack to containers/kubernetes or similar, without raising the right questions will only be your source of pain and despair for the next few years. It will not be your saviour but your executioner.
At the same time there are cases where it may fit, as shown previously, but is not a blanket solution.
Keep in mind this brief list:
- An RDBMS like MySQL, does not scale writes inside a single service (at the moment of writing)
- Bigger is the dataset longer it will be the possible downtime you will suffer (consider review your RTO/RPO)
- You cannot have a relation 1:1 with an application microservice, unless your RDBMS contains only non relational schemas.
- In case you go for microservice (and shard). You MUST have an OLAP system to serve consolidated data.
- In case you are looking to reduce management cost and gain resource optimization. Start small, and keep going like that.
Said that, if you instead of moving foolishly, stop and ask DBA and DATA experts for help, and design a proper system, then the use of RDBMS on containers/Kubernetes could become a nice surprise.
Last thing, you may discover that you do not need a tight RDBMS, you may discover that something else could serve your needs better like Cassandra or CockroachDB, and then you need to migrate to it as a real solution. In that case your need for data experts is even more urgent and the need to have them working closely with your developers is a mandatory step to success.
Disclaimer
My blog, my opinions.
I am not, in any way or aspects, presenting here the official line of thoughts of the company I am working for.
Comments
Comments are welcome but given the topic and the fact this is going to be more probable (hopefully) an open discussion, I advice you to comment on this linkedin post.

